Индекс Джини и энтропия являются критериями расчета прироста информации. Алгоритмы дерева решений используют прирост информации для разделения узла.
И Джини, и энтропия являются мерами загрязнения узла. Узел, имеющий несколько классов, является нечистым, тогда как узел, имеющий только один класс, является чистым. Энтропия в статистике аналогична энтропии в термодинамике, где она означает беспорядок. Если в узле есть несколько классов, в этом узле есть беспорядок.
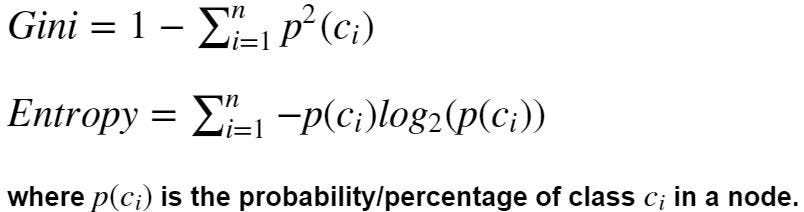
Прирост информации представляет собой энтропию родительского узла за вычетом суммы взвешенных энтропий дочерних узлов.
Вес дочернего узла — это количество выборок в узле/общее количество выборок всех дочерних узлов. Аналогичным образом прирост информации рассчитывается с помощью показателя Джини.
# Let's create functions to calculate gini and entropy scores
# Imports
from math import log
# calcpercent calculates the number of samples and percentages of each class
def calcpercent(node):
nodesum = sum(node.values())
percents = {c:v/nodesum for c,v in node.items()}
return nodesum, percents
# giniscore calculates the score for a node using above formula
def giniscore(node):
nodesum, percents = calcpercent(node)
score = round(1 - sum([i**2 for i in percents.values()]), 3)
print('Gini Score for node {} : {}'.format(node, score))
return score
# entropy score calculates the score for a node using above formula
def entropyscore(node):
nodesum, percents = calcpercent(node)
score = round(sum([-i*log(i,2) for i in percents.values()]), 3)
print('Entropy Score for node {} : {}'.format(node, score))
return score
# infogain calculates the information gain given parent node, child nodes and criterion
def infogain(parent, children, criterion):
score = {'gini': giniscore, 'entropy': entropyscore}
metric = score[criterion]
parentscore = metric(parent)
parentsum = sum(parent.values())
weighted_child_score = sum([metric(i)*sum(i.values())/parentsum for i in children])
gain = round((parentscore - weighted_child_score),2)
print('Information gain: {}'.format(gain))
return gain
# Parent node
parent_node = {'Red': 3, 'Blue':4, 'Green':5 }
# Let's say after the split nodes are
node1 = {'Red':3, 'Blue':4}
node2 = {'Green':5}
gini_gain = infogain(parent_node, [node1, node2], 'gini')
Gini Score for node {'Red': 3, 'Green': 5, 'Blue': 4} : 0.653
Gini Score for node {'Red': 3, 'Blue': 4} : 0.49
Gini Score for node {'Green': 5} : 0.0
Information gain: 0.37
entropy_gain = infogain(parent_node, [node1, node2], 'entropy')
Entropy Score for node {'Red': 3, 'Green': 5, 'Blue': 4} : 1.555
Entropy Score for node {'Red': 3, 'Blue': 4} : 0.985
Entropy Score for node {'Green': 5} : 0.0
Information gain: 0.98
# Performance wise there is not much difference between entropy and gini scores.
# Imports
import numpy as np
import pandas as pd
import os
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.naive_bayes import MultinomialNB
from sklearn.ensemble import RandomForestClassifier
# Load Dataset
# Dataset can be found at: https://www.kaggle.com/uciml/sms-spam-collection-dataset
df = pd.read_csv('spam.csv', encoding = 'latin-1' )
# Keep only necessary columns
df = df[['v2', 'v1']]
# Rename columns
df.columns = ['SMS', 'Type']
df.head()
# Let's view top 5 rows of the loaded dataset
df.head()

# Let's process the text data
# Instantiate count vectorizer
countvec = CountVectorizer(ngram_range=(1,4), stop_words='english', strip_accents='unicode', max_features=1000)
cdf = countvec.fit_transform(df.SMS)
# Instantiate algos
dt_gini = DecisionTreeClassifier(criterion='gini')
dt_entropy = DecisionTreeClassifier(criterion='entropy')
# ests = {'Logistic Regression':lr,'Decision tree': dt,'Random forest': rf, 'Naive Bayes': mnb}
ests = {'Decision tree with gini index': dt_gini, 'Decision tree with entropy': dt_unbal}
for est in ests:
print("{} score: {}%".format(est, round(cross_val_score(ests[est],X=cdf.toarray(), y=df.Type.values, cv=5).mean()*100, 3)))
print("\n")
Decision tree with gini index score: 96.572%
Decision tree with entropy score: 96.464%
Как мы видим, нет большой разницы в производительности при использовании индекса Джини по сравнению с энтропией в качестве критерия разделения. Поэтому в качестве критерия расщепления можно использовать любой из показателей Джини или энтропии.
Ссылка на официальный пост об индексе Джини и энтропии: https://thatascience.com/learn-machine-learning/gini-entropy/
Дополнительные подробные руководства можно найти на https://thatascience.com.
Чтобы получить помощь по Python и машинному обучению, посетите: Справка Python
Скоро будет новый подробный мастер-класс.
Быть в курсе !!!