Геометрический институт логистической регрессии
Что такое логистическая регрессия?
Логистическая регрессия - один из основных и популярных алгоритмов для решения задачи классификации, в отличие от его названия, в котором есть регрессия. Он называется «логистическая регрессия», потому что лежащий в его основе метод такой же, как и линейная регрессия. Одно из преимуществ логистической регрессии состоит в том, что она может обрабатывать различные типы отношений, не ограничиваясь линейными отношениями.

Давайте попробуем понять геометрическую интуицию, лежащую в основе логистической регрессии:
Существует несколько подходов к пониманию логистической регрессии, в основном это вероятностный подход, геометрический подход и подход к минимизации функции потерь, но среди всех Геометрический подход - это то, что я лично считаю более интуитивным для понимания. Итак, посмотрим:
Допущения: базовое предположение для логистической регрессии состоит в том, что данные почти или совершенно линейно разделимы, т.е. либо все (+ ve) и (-ve) классы разделены, а если нет, то очень немногие из них смешиваются. .
Цель: наша цель - найти плоскость (π), которая лучше всего разделяет (+ ve) и (-ve) классы.
Основы. Давайте посмотрим на некоторые основные термины, которые упростят понимание.
Представим самолет с. Пи (𝜋) и перпендикулярно плоскости с W
Уравнение плоскости:

w ^ t * xi + b = 0, где b - скаляр, а xi - i-е наблюдение. и если плоскость проходит через начало координат, уравнение принимает вид w ^ t * xi = 0,
Где w ^ t ( читается как Wtranspose ) - вектор-строка, а xi - вектор-столбец
Геометрическая интерпретация:

Если мы возьмем любые + ve точек класса, их расстояние di от плоскости вычисляется как:
(di = w ^ t * xi / || w ||. пусть, вектор нормы (|| w ||) равен 1)
Поскольку w и xi находятся на одной стороне границы решения, расстояние будет + ve. Теперь вычислите dj = w ^ t * xj, поскольку xj является противоположной стороной w, тогда расстояние будет -ve.
мы можем легко классифицировать точку на -ve и + ve точек, используя if (w ^ t * x ›0) then + ve class и if (w ^ t * x‹ 0) then -ve класс
Итак, наш классификатор:
If w^t * xi > 0 : then Y = +1 where Y is the class label If w^t * xi < 0 : then Y = -1 where Y is the class label
Наблюдения:
Внимательно глядя на точки на диаграмме выше, мы наблюдаем следующие случаи:
case 1: Yi >0 and w^t * xi > 0Yi = +1 means that the correct class label is +ve => Yi* w^t * xi >0 means that we have correctly predicted the class label. as +ve * +ve = +vecase 2: Yi <0 and w^t * xi <0Yi = -1 means that the correct class label is -ve => Yi* w^t * xi >0 means that we have correctly predicted the class label. as -ve * -ve = +vecase 3: Yi >0 and w^t * xi <0Yi = +1 means that the correct class label is -ve => Yi* w^t * xi <0 means that we have wrongly predicted the class label. as +ve * -ve = -vecase 2: Yi <0 and w^t * xi >0Yi = -1 means that the correct class label is -ve => Yi* w^t * xi <0 means that we have wrongly predicted the class label. as -ve * +ve = -ve
Теперь может быть бесконечное количество возможных плоскостей, которые можно использовать для разделения точек или классов на + ve и -ve. Наиболее оптимальной будет плоскость, которая классифицирует больше точек в правильные классы, т.е. чтобы найти оптимальную плоскость, нам нужно максимизировать сумму классификатора для всех точек.
Это дает нам нашу функцию оптимизации:

Сжатие: необходимость в логистической функции, сигмовидной функции или S-образной кривой
у нас уже есть функция оптимизации, тогда зачем нам еще одна функция ??
Проблема с указанной выше функцией оптимизации, чтобы понять, в чем проблема, давайте рассмотрим следующие сценарии:

На рис: 1. расстояние до плоскости (𝜋) правильно классифицирует все точки при d = 1, кроме одной, которая является выбросом, при d = 100 и за ее пределами. функция оптимизации для плоскости дает результат как -90
Пока на рис: 2. первая синяя (+ ve) точка находится на d = 1, а все остальные на d = 1, отдельно друг от друга, аналогично есть 1 зеленая точка (-ve), которая правильно классифицирована и находится на d = 1 от плоскости, в то время как остальные точки неправильно классифицированы.
Функция оптимизации дает результат как +1
Интуитивно, если вы посмотрите на приведенный выше рисунок, вы поймете, что (рис. 1: 𝜋) лучше, чем (рис. 2: 𝜋), поскольку (рис. 1: 𝜋) правильно классифицировал большее количество точек данных и (рис. 2: 𝜋) ) правильно классифицировал только одну точку данных, но согласно нашей функции оптимизации (рис. 2: 𝜋) лучше из-за +1 ›-90
Чтобы решить эту проблему из-за выбросов, нам нужна надежная функция, которая не сильно зависит от выбросов.
Одной из таких функций является сигмовидная функция или S-образная функция:

Почему сигмовидная функция?
- Это монотонная функция, которая сжимает значение от 0 до 1: независимо от того, какой выброс, значение функции не превышает 0–1, поэтому общий процесс называется сжатием.
- Это дает хорошую вероятностную интерпретацию. Пример - Если точка лежит на поверхности принятия решения (d = 0), то интуитивно ее вероятность должна быть 1/2, так как она может принадлежать к любому классу, и здесь также мы можем видеть, что - Sigma (0) = 1/2.
- Легко дифференцируемый,
Итак, нам нужно максимизировать сигмовидную функцию, которая определяется как:

что дает нам функцию оптимизации как:

Подождите, что ?????? Хотите знать, как мы получили указанную выше функцию из сигмовидной функции? вот как:
Мы использовали свойство сигмоидной функции, которая является монотонной функцией, а также f (x) = log (x) также является монотонной функцией: мы взяли журнал сигмоидной функции, чтобы упростить ее.
мы будем использовать следующие свойства, чтобы получить желаемую форму функции оптимизации
- журнал (1 / x) = -log (x)
- argmax (-f (x)) = argmin (f (x)) т.е. максимизация отрицательной функции аналогична минимизации положительной функции.
применяя два вышеупомянутых свойства, мы получаем:
Стратегия минимизации:
Вернемся к уравнению:
n
W(optimal) = argmin(∑i=1 log(1 + exp(- Yi * w^t * xi))
Let z= Yi * w^t * xi
n
W(optimal) = argmin(∑i=1 log(1 + exp(- Zi))

Из приведенного выше графика exp (-Zi) всегда будет положительным.
exp(-Zi) — > 0 to +∞
n
W(optimal) = argmin(∑i=1 log(1 + exp(- Zi)) >= 0
when exp(-Zi)-> 0 => argmin(∑i=1 log(1 + 0)) and as log(1) = 0
So-min значение функции оптимизации равно 0, и это происходит, когда exp (- Zi) = 0
, следовательно, общее минимальное значение для нашей функции оптимизации будет иметь место, когда
Zi -> +∞ for all i
теперь, как мы знаем, Zi = Yi * w ^ t * xi, здесь xi - Feature, а Yi - Label исправлены, единственное, что можно изменить, это w ^ t
Чтобы переместить значение Zi в бесконечность, мы выберем очень большое значение (+ или -) для W.
case 1:Yi =+1(Yi * w^t * xi) = +1 * (very large +ve value of W ) * xi = Very large +ve value ~>+∞case 2: Yi= -1 (Yi * w^t * xi) = -1 * (very large -ve value of W ) * xi = Very large +ve value ~>+∞
Таким образом, наша задача сделать Zi → + ∞ достигнута.
Регуляризация:
Проблема с вышеупомянутой стратегией заключается в том, что мы можем сделать Zi → + ∞ для всех значений i, найдя такое большое значение W.
Почему это проблема: Проблема здесь в переобучении, мы тоже делаем нашу модель хорошо быть правдой, сделав Zi -> +∞
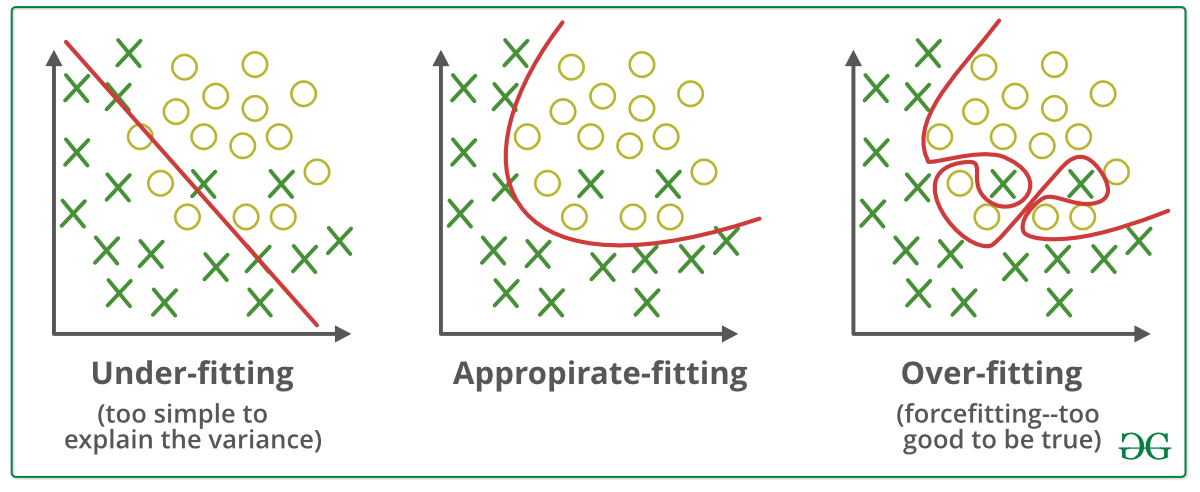
Если граница решения чрезмерно подогнана, форма может быть сильно искажена, чтобы соответствовать только обучающим данным, при этом не удастся обобщить для невидимых данных.
поэтому мы используем Регуляризацию, поэтому функция стоимости логистической регрессии обновляется, чтобы штрафовать высокие значения параметров.
В основном используются два типа регуляризации:
- L2 регуляризация
- L1 Регуляризация
Регуляризация L2:
В L2 Regularization мы вводим дополнительный термин, называемый параметром регуляризации, чтобы предотвратить переоснащение.

Гиперпараметр: λ
Срок регуляризации : λW ^ TW
Функция потерь : W * = argmin (∑i = 1 log (1 + exp (- Yi W ^ TXi))
Теперь, если мы попытаемся сделать Zi → + ∞, увеличив значение W и сделав член потерь ~ ›0, наш член регуляризации компенсирует это, превратившись в + ∞ as, у нас есть λW ^ TW как термин регуляризации. так что, по сути, существует компромисс между сроком убытков и сроком регуляризации
Значение λ:
λ играет ключевую роль в оптимизации нашей функции.
- Если мы значительно уменьшим значение λ, тогда модель переоценивается, поскольку влияние члена регуляризации становится незначительным.
- Если мы значительно увеличим значение λ, тогда наша модель не подходит, так как член потерь становится незначительным, а член регуляризации не содержит никаких обучающих данных.
L1 Регуляризация:
Регуляризация L1 также играет ту же роль, что и L2, т.е. предотвращает переоснащение, но в отличие от регуляризации L2.
Срок регуляризации : λ || W ||
где || W || = Сумма всех абсолютных значений W для i = от 1 до n
Важность регуляризации L1 заключается в уменьшении признаков, поскольку регуляризация L1 создала разреженные векторы, поэтому для признака fi, если это не важно, его соответствующий вес будет 0 в случае регуляризации L1, тогда как при регуляризации L2 он будет значительно меньше, но не 0
Эластичная сеть:
Есть даже еще одна регуляризация, которая считается лучшей как в мире, так и здесь.
Срок регуляризации: λW ^ TW + λ` || W ||
___________________________ _КОНЕЦ_ ____________________
Свяжитесь со мной на LINKEDIN