Вступление
R - это язык и среда для статистических вычислений и графики, которые имеют сходство с языком и средой S. Хотя R можно рассматривать как другую реализацию S, есть некоторые важные отличия.
R предоставляет широкий спектр статистических (линейное и нелинейное моделирование, классические статистические тесты, анализ временных рядов, классификация, кластеризация и т. Д.) И графических методов и обладает высокой расширяемостью. Язык S часто рассматривается как основной выбор для исследований в области статистической методологии, а R предоставляет открытый путь к участию в этой деятельности.
Скачивание R для Windows
Перейдите на веб-сайт https://cran.rstudio.com и загрузите R для Windows, следуя инструкциям ниже (4.0.0 - это версия, которую я установил).

Установка R для Windows
После загрузки файла установите его, выполнив действия, указанные ниже.

После нажатия Далее › на шаге 8 начнется установка.
Теперь откройте программу «R», и вы увидите что-то вроде изображения, показанного ниже.

Во-первых, мы должны выяснить, какой у нас рабочий каталог. Введитеgetwd() в консоли R, чтобы найти текущий рабочий каталог. Обычно он указывает на C:/Users/username/Documents. В моем случае это указывает на C:/Users/Nipuna/Documents. Но когда мой рабочий каталог указывает на каталог Documents, возникает проблема. Итак, я могу изменить свой рабочий каталог, щелкнув Файл → Изменить каталог. и выбрав соответствующую папку.
Гайки и болты
Пример кода
Перейдите в Файл → Новый скрипт. И теперь вы увидите еще один файл, который открывается в приложении RGui. Просто введите следующую строку кода в новый файл.
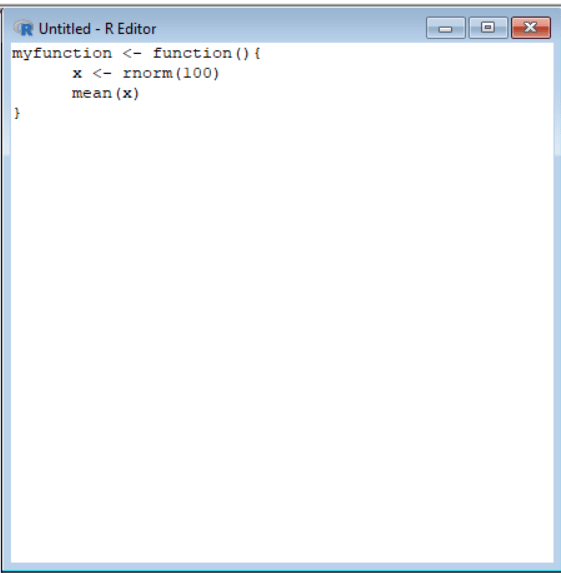
Теперь мы можем запустить эту функцию двумя способами. Первый способ - скопировать весь скрипт, нажав «CTRL + C», и вставить его в консоль, нажав «CTRL + V». Даже после вставки и нажатия «Enter» ничего не произойдет, потому что сначала нам нужно получить доступ к элементу в рабочей среде и запустить его, выбрав элемент. Итак, чтобы перечислить все элементы в рабочей среде, введите ls() в R-console. После ввода этого сообщения вы увидите, что на выходе отображается [1] "myfunction", так что это единственный элемент в текущей рабочей среде. Чтобы запустить функцию, введите в консоли myfunction(). Круглые скобки () используются здесь, потому что это функция. Если бы это была переменная, мы должны ввести myfunction
Второй способ запустить эту функцию - сохранить этот сценарий «Без названия» и получить к нему доступ в R-консоли. Сохраните функцию, нажав «CTRL + S», и дайте файлу простое имя, например example.R. Как видите, .R - это расширение R-файлов. Теперь, чтобы получить доступ к файлу, введите dir() в R-console, и он покажет, что "example.R" находится в рабочем каталоге. Теперь, чтобы получить доступ к файлу, введите в консоли source("example.R"). Функция source() загружает элементы из файла в консоль. Итак, теперь мы можем набрать ls() и найти наш элемент myfunction и набрать myfunction(), чтобы запустить функцию.
Вход R-console
Символ <- - это оператор присваивания в R-console. Когда вы набираете x <- 10, переменной x присваивается 10. Вы можете просмотреть значение x в R-console, набрав print(x) или просто набрав x и нажав "Enter". Если вы просто наберете x <- и нажмете «ввод», ошибок не будет, и консоль будет ждать ввода.
Типы данных
Объекты
В R. есть пять базовых классов типов данных: character, numeric(real numbers), integer, complex, boolean(True/False
Самая основная структура данных в R - это vector. Она содержит элементы одного типа. Тип вектора можно проверить с помощью typeof() функции, а его длину (количество элементов в нем) можно проверить с помощью функции length(). Кроме того, пустой вектор может быть создан с помощью функции vector(). Самый простой способ создания векторов - использовать функцию c(). Другой способ создать вектор - это ввести что-то вроде этого: x <- 0:6 Теперь вектор x создается со значением 0 1 2 3 4 5 6.
Но есть исключение под названием list, которое представлено как вектор, но может содержать объекты разных классов.
Числа
Числа в R обычно рассматриваются как числовые объекты, которые являются действительными и имеют двойную точность. Но если вы явно хотите иметь целое число, вы можете ввести L после числа (например: x <- 1L). Существует также специальный номер Inf, который представляет бесконечность, и, в отличие от других языков программирования, вы можете использовать Inf для обычных вычислений (например: 1/Inf это 0), а значение NaN представляет неопределенные значения (например: 0/0 равно NaN).
Атрибуты
Объекты R могут иметь такие атрибуты, как names, dimnames, dimensions, class, length, other user-defined attributes/metadata К атрибутам объекта можно получить доступ с помощью функции attributes().
Смешивание объектов
Предположим, что вы создали вектор, x <- c(5.2,"a") Тогда что произойдет, если вы нажмете «ввод» после того, как наберете его? Ошибок не будет, поскольку возникает понятие coercion. Он учитывает иерархию приоритетов и назначает типы данных атрибутам внутри вектора. Например, тип вектора, который мы набрали ранее, теперь имеет тип character. Иерархия приоритета - character, numeric(real numbers), integer, complex, boolean(True/False с уменьшением приоритета. Но вы можете выполнить явное принуждение с помощью функции as.*. Например, когда вы набираете x <- 0:2 и набираете class(x), вы получаете тип integer. И когда вы набираете as.numeric(x), на выходе вы получаете [1] 0 1 2. И когда вы набираете as.logical(x), на выходе вы получаете [1] FALSE TRUE TRUE.
Списки
Списки - это объекты R, которые содержат элементы разных типов, такие как числа, строки, векторы и другой список внутри него. Список также может содержать матрицу или функцию в качестве элементов списка. Список создается с помощью функции list() (например: x <- list(1,"a", TRUE)). Вы можете давать имена элементам списка, создавая другой вектор с помощью функции names() (например: для приведенного выше примера мы можем присвоить имена, подобные этому names(x)<-c("number","character","boolean")).
Матрицы
Матрицы - это векторы с атрибутом размер. Атрибут Dimension сам по себе является целочисленным вектором длины два (_77 _) (например: n <- matrix(nrow=2, ncol=2)). Вы можете найти размеры матрицы, набрав dim() function (например: dim(n) даст вам 2 2 в качестве ответа). И когда вы набираете attributes(n), он дает вам $dim в качестве ответа, указывая на то, что атрибуты имеют размерный тип. Мы можем создать матрицу, просто создав вектор и назначив ему размеры (например: n <- 1:10 дает вам вектор со значениями 0 1 2 3 4 5 6 7 8 9, и когда вы набираете dim(n) <- c(2,5), он присваивает значения матрице с именем n, которая имеет размеры 2 x 5). Простой способ сделать это n <- matrix(1:10, nrow=2,ncol=5)
Матрицы могут быть созданы с помощью привязки столбцов или привязки строк с cbind() и rbind()

Как вы можете видеть, когда есть несоответствие длины, значения повторяются для создания матрицы.
Совет: используйте «CTRL + L», чтобы очистить R-консоль.
Факторы
Факторы используются для представления категориальных данных. Факторы могут быть заказаны или неупорядочены. Можно представить фактор как целочисленный вектор, в котором каждое целое число имеет метку.
Факторы обрабатываются особым образом с помощью функций моделирования, таких как lm() и glm(). Использование факторов с метками лучше, чем использование целых чисел, поскольку факторы описываются самостоятельно (например: наличие значений heads и tails монеты лучше, чем наличие 0 и 1).

Вы можете видеть, что мы можем найти категориальные данные более конкретным образом, используя факторы. Порядок уровней может быть установлен с помощью аргумента levels для factor(). Это важно при линейном моделировании, поскольку первый уровень используется как базовый уровень, x<-factor(c("yes","yes","no"),levels=c("yes","no"))
Недостающие значения
Отсутствующие значения обозначаются NA или NaN для неопределенных математических операций. is.na() используется для проверки объектов, являются ли они NA или нет, и аналогичным образом is.nan() используется для проверки NaN
Значения NA имеют классы, такие как целое число NA и символ NA. Значения NaN также являются значениями NA, но обратное неверно.
Фреймы данных
Фреймы данных могут использоваться для хранения табличных данных. Они представлены в виде списка особого типа, каждый элемент которого должен иметь одинаковую длину. Кроме того, каждый элемент списка можно рассматривать как столбец, а длина каждого элемента - это количество строк. Фреймы данных имеют специальный атрибут, называемый row.names. Эти фреймы данных обычно создаются путем вызова read.table() или read.csv(). Их можно преобразовать в матрицы с помощью функции data.matrix().
Теперь давайте посмотрим, как мы можем читать и записывать данные с помощью R.
Чтение данных
Есть несколько основных функций, которые можно использовать для чтения данных в R.
read.table()read.csv()для чтения табличных данных.readLinesдля чтения строк текстового файла.sourceдля чтения файлов кода R (инверсияdump).dgetдля чтения в файлах кода R (инверсияdput).loadдля чтения в сохраненных рабочих областях.unserializeдля чтения отдельных объектов R в двоичной форме.
Запись данных
Есть аналогичные функции для записи данных в файлы.
write.table writeLines dump dput save serialize
который выполняет функции, обратные упомянутым выше.
Чтение файлов данных с помощью read.table()
Функция read.table() имеет несколько важных аргументов.
fileимя файла или подключенияheaderлогически выражает, есть ли у файла заголовок или нетsepуказывает, как разделены столбцыcolClassesуказывает класс каждого столбца в наборе данных.nrowsколичество строк в наборе данныхcomment.charсимвольная строка, обозначающая символ комментарияskipколичество строк, которые нужно пропустить с началаstringAsFactorsуказывает, должны ли символьные переменные кодироваться как факторы или нет
Подсказка: обычно «#» - это способ начать комментарий в R.
Подсказка: при использовании больших наборов данных в R рекомендуется вычислить объем памяти перед выполнением задачи.
Текстовые форматы
dumping и dputing полезны, потому что полученный текстовый формат можно редактировать, и в случае повреждения мы можем его восстановить. Это связано с тем, что при использовании этих методов метаданные сохраняются.
Интерфейсы с внешним миром
Данные считываются с использованием интерфейсов подключения. Некоторые из самых популярных подключений в R: file gzfile bzfile и url (gzfile и bzfile для сжатых папок)
Подмножество
Есть несколько способов получить доступ к данным в объектах. Например, [ всегда возвращает объект того же класса, что и исходный, а[[ используется для извлечения элементов списка или фрейма данных - это можно использовать только для извлечения одного элемента, и класс возвращаемого объекта не обязательно будет список или фрейм данных. Кроме того, $ используется для извлечения элементов списка или фрейма данных по имени, семантика аналогична семантике [[
Это ключевые концепции, которые нам нужно понять, чтобы начать программировать на R. Вы можете посмотреть документацию и понять концепции дальше. О том, как начать программировать на R, мы рассмотрим в отдельной статье.