
Почему увеличение данных?
Современные модели машинного обучения, такие как глубокие нейронные сети, могут иметь миллиарды параметров и требовать массивных размеченных наборов обучающих данных, которые часто недоступны. Метод искусственного расширения помеченных обучающих наборов данных, известный как увеличение данных, быстро стал критическим для борьбы с этой проблемой нехватки данных. Сегодня расширение данных используется в качестве секретного соуса почти во всех современных моделях классификации изображений и становится все более распространенным в других модальностях, таких как понимание естественного языка. Цель этого сообщения в блоге — предоставить обзор недавних усилий в этой захватывающей области исследований.
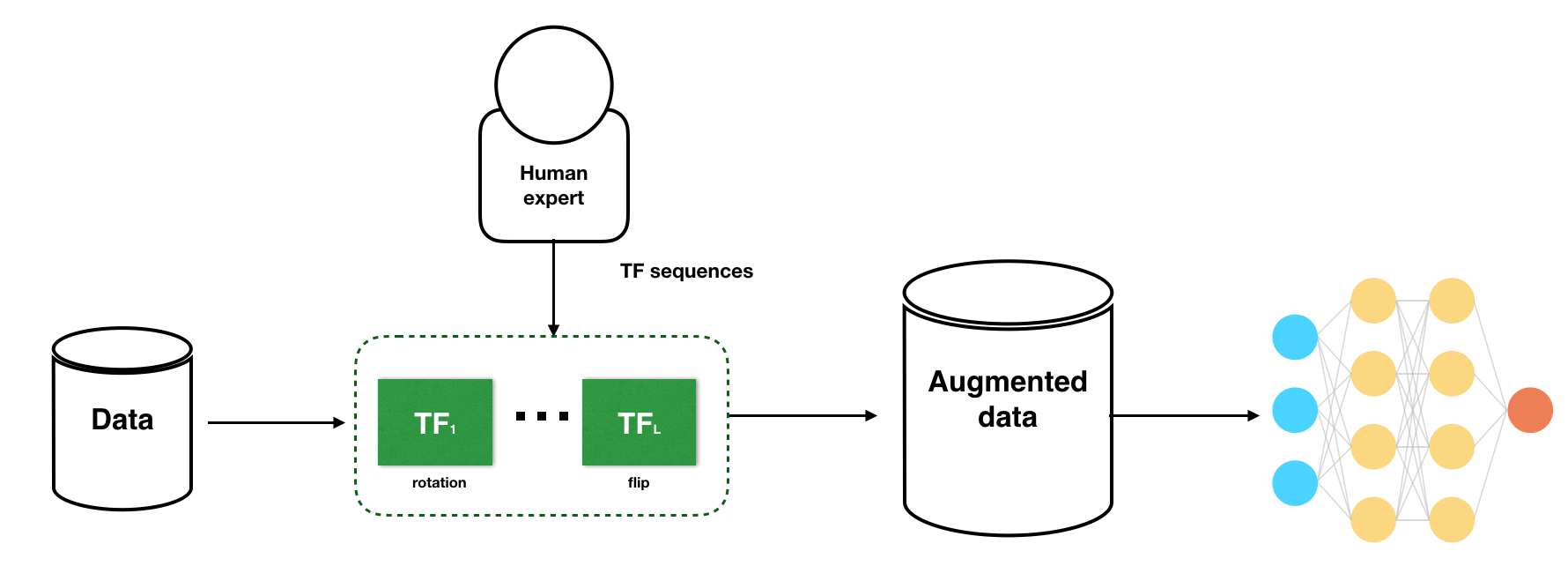
Схемы эвристического расширения данных часто полагаются на состав набора простых функций преобразования (TF), таких как повороты и перевороты (см. рис. 1). При тщательном выборе схемы дополнения данных, настроенные экспертами-людьми, могут повысить производительность модели. Однако на практике такие эвристические стратегии могут привести к большим различиям в производительности конечной модели и могут не привести к дополнениям, необходимым для современных моделей.
Открытые вызовы в области увеличения данных
Ограничения традиционных подходов к дополнению данных открывают огромные возможности для исследовательского прогресса. Ниже мы суммируем несколько проблем, которые мотивируют некоторые работы в области увеличения данных.
- От ручного к автоматизированному алгоритму поиска: в отличие от выполнения неоптимального ручного поиска, как мы можем разработать обучаемые алгоритмы, чтобы найти стратегии расширения, которые могут превзойти разработанные человеком эвристики?
- От практического к теоретическому пониманию. Несмотря на быстрый прогресс в создании различных прагматических подходов к дополнению, понимание их преимуществ остается загадкой из-за отсутствия аналитических инструментов. Как мы можем теоретически понять различные аугментации данных, используемые на практике?
- От грубого к детальному обеспечению качества модели. В то время как большинство существующих подходов к расширению данных сосредоточено на повышении общей производительности модели, часто необходимо иметь более точную детальный взгляд на критические подмножества данных. Когда модель демонстрирует противоречивые прогнозы для важных подгрупп данных, как мы можем использовать дополнения данных, чтобы смягчить разрыв в производительности предписанным образом?
В этом блоге мы будем описывать идеи и последние исследовательские работы, ведущие к преодолению этих проблем.
Практические методы обучаемого увеличения данных
Обучаемое увеличение данных многообещающе, поскольку оно позволяет нам искать более мощные параметризации и композиции преобразований. Возможно, самая большая трудность при автоматизации увеличения данных заключается в том, как искать в пространстве преобразований. Это может быть недопустимо из-за большого количества функций преобразования и связанных с ними параметров в пространстве поиска. Как мы можем разработать обучаемые алгоритмы, которые эффективно и действенно исследуют пространство функций преобразования и находят стратегии расширения, которые могут превзойти разработанные человеком эвристики? В ответ на вызов мы выделяем несколько последних методов ниже.
TANDA: трансформация состязательных сетей для расширения данных
Чтобы решить эту проблему, TANDA (Ратнер и др., 2017) предлагает структуру для изучения дополнений, которая моделирует дополнения данных как последовательности функций преобразования (TF), предоставляемые пользователями. Например, это может быть повернуть на 5 градусов или сдвинуть на 2 пикселя. По сути, эта структура состоит из двух компонентов (1) изучения генератора последовательностей TF, что приводит к полезным точкам дополненных данных, и (2) использования генератора последовательностей для увеличения обучающие наборы для нисходящей модели. В частности, генератор последовательности TF обучен создавать реалистичные изображения, обманывая сеть дискриминатора, следуя структуре GAN (Goodfellow et al. 2014). Основное предположение здесь состоит в том, что преобразования приведут либо к реалистичным изображениям, либо к неразличимым изображениям мусора, которые находятся за пределами многообразия. Как показано на рисунке 1, цель генератора состоит в том, чтобы создать последовательность TF, чтобы точка расширенных данных могла обмануть дискриминатор; тогда как целью дискриминатора является получение значений, близких к 1 для точек данных в исходном обучающем наборе, и значений, близких к 0, для точек дополненных данных.

AutoAugment и дальнейшее улучшение Используя аналогичную структуру, AutoAugment (Cubuk et al. 2018), разработанный Google, продемонстрировал современную производительность с использованием изученных политик расширения. В этой работе генератор последовательности TF учится напрямую оптимизировать точность проверки конечной модели. В нескольких последующих работах, включая RandAugment (Cubuk et al. 2019) и Adversarial AutoAugment (Zhang et al. 2019), было предложено снизить вычислительную стоимость AutoAugment, установив новый современный уровень производительности при классификации изображений. ориентиры.
Теоретическое понимание дополнений данных
Несмотря на быстрый прогресс практических методов увеличения данных, точное понимание их преимуществ остается загадкой. Даже для более простых моделей не совсем понятно, как обучение на дополненных данных влияет на процесс обучения, параметры и поверхность принятия решений. Это усугубляется тем фактом, что в современных конвейерах машинного обучения расширение данных выполняется различными способами для разных задач и областей, что исключает общую модель преобразования. Как мы можем теоретически охарактеризовать и понять эффект различных дополнений данных, используемых на практике? Чтобы решить эту проблему, наша лаборатория изучила увеличение данных с точки зрения ядра, а также в упрощенной линейной настройке.
Увеличение данных как ядро
Дао и др. 2019 разработал теоретическую основу, моделируя увеличение данных как цепь Маркова, в которой увеличение выполняется посредством случайной последовательности преобразований, подобно тому, как увеличение данных выполняется на практике. Мы показываем, что эффект применения цепи Маркова к обучающему набору данных (в сочетании с классификатором k-ближайших соседей) подобен использованию классификатора ядра, где ядро является функцией базовых преобразований.
Опираясь на связь между теорией ядра и расширением данных, Dao et al. 2019 показывают, что классификатор ядра на дополненных данных приблизительно разбивается на два компонента: (i) усредненная версия преобразованных признаков и (ii) член регуляризации дисперсии, зависящий от данных. Это предполагает более тонкое объяснение увеличения данных, а именно то, что оно улучшает обобщение как за счет инвариантности, так и за счет уменьшения сложности модели. Дао и др. 2019 эмпирически подтвердить качество нашей аппроксимации и провести связи с другими методами улучшения обобщения, включая недавнюю работу по инвариантному обучению (van der Wilk et al. 2018) и надежной оптимизации (Namkoong & Duchi, 2017).
Увеличение данных в упрощенной линейной настройке
Одним из ограничений вышеупомянутых работ является то, что сложно определить эффект применения конкретного преобразования к полученному ядру. Кроме того, пока неясно, как эффективно применять увеличение данных к методам ядра, чтобы получить производительность, сравнимую с нейронными сетями. В более поздней работе мы рассматриваем более простую линейную настройку, которая способна моделировать широкий спектр линейных преобразований, обычно используемых при увеличении изображения, как показано на рисунке 3.
Теоретические выводы. Мы предлагаем несколько теоретических идей, рассматривая сверхпараметризованную линейную модель, в которой обучающие данные лежат в низкоразмерном подпространстве. Мы показываем, что преобразования, инвариантные к меткам, могут добавлять новую информацию к обучающим данным, а ошибка оценки гребневой оценки может быть уменьшена за счет добавления новых точек, которые находятся за пределами диапазона обучающих данных. Кроме того, мы показываем, что смешивание (Zhang et al., 2017 может играть эффект регуляризации за счет уменьшения веса обучающих данных относительно члена регуляризации L2 на обучающих данных.

Вдохновленный теорией новый современный уровень. Один вывод из нашего теоретического исследования заключается в том, что разные (составные) преобразования показывают очень разные конечные результаты. Вдохновленные этим наблюдением, мы хотели бы использовать тот факт, что одни преобразования более эффективны, чем другие. Мы предлагаем схему случайной выборки на основе неопределенности, которая среди преобразованных точек данных выбирает точки с наибольшими потерями, т. е. те, которые предоставляют наибольшую информацию (см. рис. 4). Наша схема выборки обеспечивает более высокую точность за счет нахождения более полезных преобразований по сравнению с RandAugment на трех разных архитектурах CNN, устанавливая новую современную производительность на общих тестах. Например, наш метод превосходит RandAugment на 0,59% на CIFAR-10 и 1,24% на CIFAR-100 с использованием Wide-ResNet-28–10. Пожалуйста, ознакомьтесь с нашей полной статьей здесь. Наш код скоро будет выпущен, чтобы вы могли его опробовать!

Новое направление: увеличение данных для исправления модели
Большинство исследований в области машинного обучения, проводимых сегодня, по-прежнему решают фиксированные задачи. Однако в реальном мире модели машинного обучения при развертывании могут дать сбой из-за непредвиденных изменений в распределении данных. Это поднимает вопрос о том, как мы можем переходить от построения модели к сопровождению модели адаптивным образом. В нашей последней работе мы предлагаем исправление модели — первую структуру, которая использует увеличение данных для смягчения проблем с производительностью ошибочной модели при развертывании.
Случай использования исправления модели в медицине
Чтобы привести конкретный пример, при обнаружении рака кожи исследователи показали, что стандартные классификаторы имеют совершенно разные результаты в двух подгруппах ракового класса из-за ассоциации классификатора между разноцветными повязками и доброкачественными изображениями (см. Рисунок 5 слева). Этот разрыв в производительности подгруппы также изучался в параллельном исследовании нашей группы (Oakden-Rayner et al., 2019) и возникает из-за того, что классификатор полагается на особенности, характерные для подгруппы, например. красочные повязки.

Чтобы исправить такие недостатки в развернутой модели, экспертам в предметной области приходится прибегать к ручной очистке данных, чтобы стереть различия между подгруппами, например. удаление маркировки на данных рака кожи с помощью Photoshop (Winkler et al. 2019) и переобучение модели с измененными данными. Это может быть чрезвычайно трудоемко! Можем ли мы каким-то образом научиться преобразованиям, которые позволяют увеличивать примеры, чтобы сбалансировать население между группами заданным образом? Это именно то, к чему мы обращаемся с помощью этой новой структуры исправления модели.
CLAMP: изученные расширения с учетом классов для исправления моделей
Концептуальная основа исправления модели состоит из двух этапов (как показано на рисунке 6).
- Изучите преобразования между подгруппами между разными подгруппами. Эти преобразования представляют собой карты, сохраняющие классы, которые позволяют семантически изменять идентификатор подгруппы точки данных (например, добавлять или удалять разноцветные повязки).
- Переобучиться, чтобы исправить модель с помощью дополненных данных, поощряя классификатор быть устойчивым к их вариациям.

Мы предлагаем CLAMP, воплощение нашей первой сквозной среды исправления моделей. Мы сочетаем новый регуляризатор согласованности с надежной целью обучения, вдохновленной недавней работой Group Distributionally Robust Optimization (GDRO, Sagawa et al. 2019). Мы расширяем GDRO до цели обучения, обусловленной классом, которая совместно оптимизируется для худших показателей подгруппы в каждом классе. CLAMP может сбалансировать производительность подгрупп в каждом классе, сократив разрыв в производительности до 24x. В наборе данных ISIC для обнаружения рака кожи CLAMP повышает устойчивую точность на 11,7% по сравнению с базовым уровнем надежного обучения. С помощью визуализации мы также показываем на рисунке 5, что CLAMP успешно устраняет зависимость модели от ложного признака (цветные повязки), переключая внимание на поражение кожи — истинный интересующий признак.