Часть 1 из 3-х частей.

Добро пожаловать в первую моей серии из трех частей, посвященной изучению структур данных в Swift. Здесь мы в целом поговорим о структурах данных и углубимся в массивы.
Введение в структуры данных
Мы много слышали о структурах данных. Структуры данных - это контейнеры, которые хранят данные в определенном макете. Они чрезвычайно важны, учитывая, что все программы работают с данными и с тем, как они хранятся. Следовательно, необходимо учитывать, как мы храним эти данные - не только с точки зрения пространства (т. Е. Потребления памяти), но и времени (оценка того, сколько времени мы можем / не можем превышать).
Вы поняли - нам приходится иметь дело со сложностями пространства и времени. Именно об этом и будет рассказано в этой серии из трех частей. Мы рассмотрим некоторые встроенные в Swift структуры данных - массивы, наборы и словари. И к концу этой серии статей мы получим более глубокое понимание того, как эти структуры данных работают под капотом, а также ключевые операции для каждой из них.
Массивы
Оглавление:
A. Как массивы работают под капотом
B. Операции над массивами
C. Activity: реализация кругового буфера
Массивы: под капотом
Массив - это упорядоченная коллекция с произвольным доступом.
Массивы содержат элементы одного типа. Тип элемента массива может быть строковым, целочисленным, вплоть до класса. Способы создания массивов включают их инициализацию как пустые, что требует объявления явного типа или предварительного определения элементов массива с помощью литералов массива.
Прежде чем мы перейдем к тому, как массивы работают под капотом, давайте поговорим о двух свойствах массивов - count и capacity . Count определяет количество элементов в массиве. Емкость определяет общее количество элементов, которое может содержать массив до превышения и необходимости выделения новой памяти.
Массивы резервируют определенный объем памяти для хранения своего содержимого. После заполнения емкости и добавления дополнительных элементов в массив массив выделяет большую область памяти и копирует свои элементы в новое хранилище. Это может занять много времени. Размер нового хранилища экспоненциально увеличивается по сравнению со старым размером. Поэтому по мере роста массива перераспределение происходит все реже. См. Ниже, как работает изменение размера:
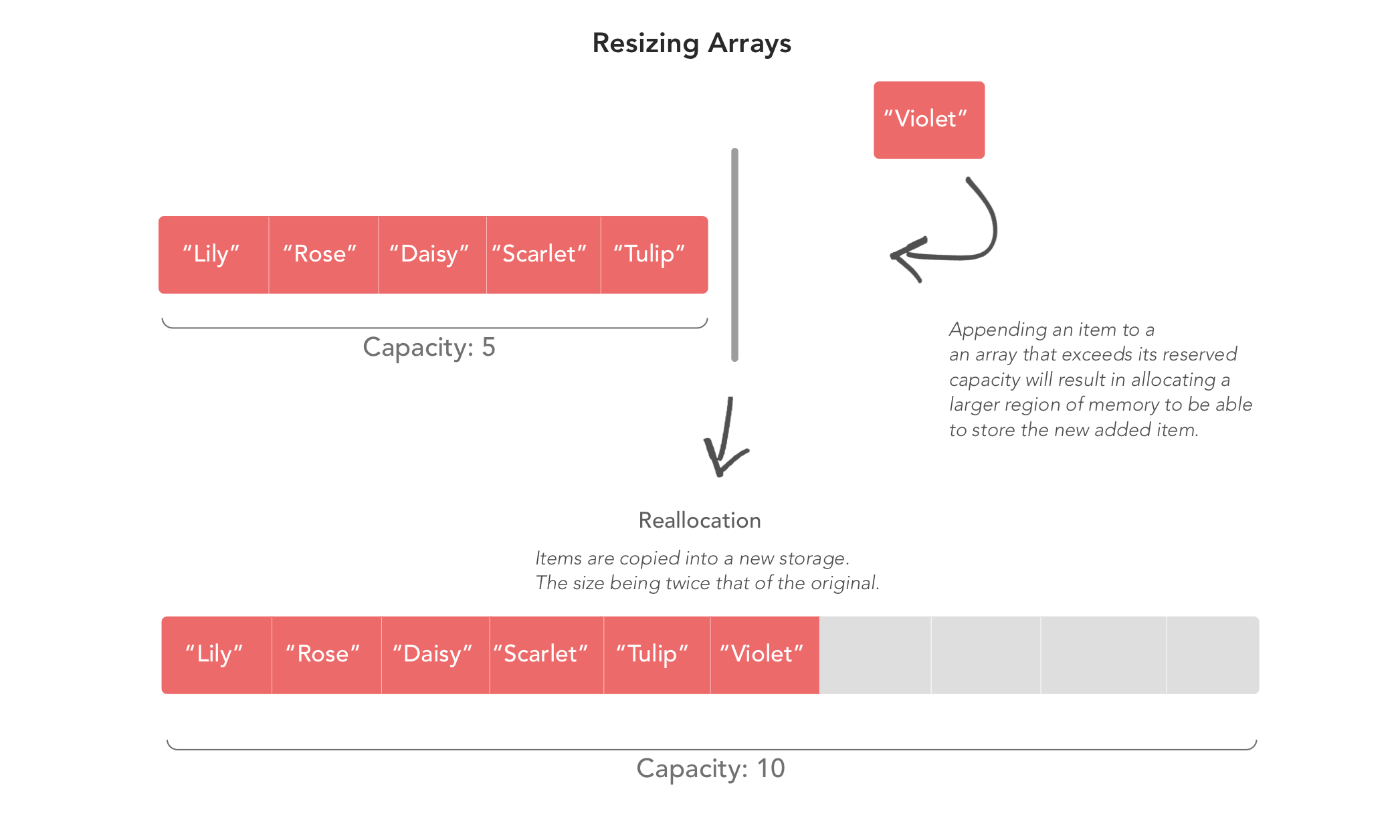
Как показано на диаграмме выше, мы добавляем «Violet» к массиву, который вот-вот превысит свою емкость. Элемент не добавляется сразу, но происходит то, что в другом месте создается новая память, все элементы копируются, и, наконец, элемент добавляется в массив. Это называется перераспределением: выделение нового хранилища в другой области памяти. Размер массива увеличивается экспоненциально. В Swift это называется геометрической моделью роста.
Итак, после того, как мы добавили «Violet», емкость массива вырастет экспоненциально с 5 до 10. А если мы добавим одиннадцатый элемент, произойдет перераспределение, и емкость массива вырастет до 20.
Можно ли уменьшить перераспределение?
Да! Здесь пригодится метод reserveCapacity(_:) . Если вы приблизительно знаете, сколько всего элементов будет содержаться в массиве, вы можете объявить размер емкости с помощью метода reserveCapacity(_:) прямо при инициализации массива. Следует иметь в виду, что это не означает, что в массиве может быть только определенное количество элементов; элементы, которые превышают размер зарезервированной емкости, по-прежнему могут быть добавлены, но это вызовет перераспределение.
Операции с массивами
А. Добавление
append(_:)Добавляет один элемент в конец массива.append(contentsOf: )Добавляет несколько элементов данного параметра в конец массива.insert(_:at:)Вставляет элемент по указанному индексу.insert(contentsOf:at:)Вставляет несколько элементов по указанному индексу.
Добавление элементов в массив создает в среднем время выполнения O (1). Это для динамических массивов - массивов, которые могут расширяться по мере добавления к ним элементов. Есть только один случай, когда время выполнения равно O (n) - при выделении новой памяти, поскольку вам нужно скопировать все элементы в новое хранилище.
Но это очень редко, поскольку массив становится больше! Думаю об этом. Массив удваивается в размере каждый раз, когда запускается перераспределение, из-за чего для заполнения массива требуется гораздо больше времени. Следовательно, эти изменения отменяют друг друга, оставляя среднее время выполнения O (1) для каждого вызова добавления.
Имейте в виду, что массивы имеют среднее время выполнения O (1) для каждого элемента. Таким образом, добавление нескольких элементов займет в среднем O (n), где n - количество элементов, добавленных в массив. Вставка также требует времени выполнения O (n), где n - количество элементов после вставленного индекса, поскольку мы должны сдвинуть все элементы на один.
Б. Удаление
remove(at:)Удаляет и возвращает элемент по заданному индексу в массиве.removeFirst()Удаляет и возвращает первый элемент в массиве .removeLast()Удаляет и возвращает последний элемент в массиве.removeAll(),removeAll(keepingCapacity:)Удаляет все элементы в массиве и уменьшает емкость до 0, если не объявлено сохранение емкости с помощью true.removeSubrange(_:)Удаляет все элементы в диапазоне и сдвигает элементы после этого, чтобы заполнить свои позиции.popLast()Удаляет и возвращает последний элемент в массиве.
Похоже, что операции popLast() и removeLast() делают то же самое. 🧐 Однако у них определенно есть большая разница; В случае, когда вам не гарантировано наличие значений в массиве, использование операции popLast() будет безопасным, поскольку ее возвращаемое значение является необязательным и вернет nil, если есть в массиве нет элементов. Но с removeLast(), а также с removeFirst() массив должен содержать элементы, иначе он выдаст ошибку.
C. Индексирование
firstНеобязательное значение, возвращающее первый элемент в массиве, но ноль при выполнении с пустыми массивами.lastНеобязательное значение, которое возвращает последний элемент массива, но ноль при выполнении с пустыми массивами.startIndexПозиция первого элемента в массиве.endIndexПозиция на единицу больше, чем последний элемент.indicesВозвращает индексированный диапазон коллекции.firstIndex(of:)Возвращает необязательный индекс первого найденного заданного элемента.firstIndex(where:)Возвращает необязательный индекс первого найденного элемента, который удовлетворяет заданному предикату.lastIndex(of:)Возвращает необязательное целое число последнего индекса данного найденного элемента.lastIndex(where:)Возвращает необязательный индекс последнего найденного элемента, удовлетворяющего заданному предикату.dropFirst()Возвращает подпоследовательность, содержащую все элементы, кроме первого элемента.dropLast()Возвращает подпоследовательность, содержащую все элементы, кроме последнего элемента.swap(_: _:)Меняет значения по данному индексу.
Чем полезны startIndex и endIndex ? Эти операции отлично подходят для перебора индексов массива, когда вы не хотите выходить за пределы. Тогда почему бы не использовать свойство count в массиве? Свойство count может иметь значение O (n) в случае, если коллекция не соответствует протоколу RandomAccessCollection. И здесь пригодится свойство endIndex! Проверьте фрагмент кода ниже:
Как показано выше, оба цикла for делают одно и то же. Оба они перебирают диапазон от 0 до на единицу меньше, чем общее количество элементов в массиве, и имеют одинаковый результат. Эти две операции не имеют разницы во времени выполнения, только если гарантируется сбор random-access performance. В другом случае использование endIndex было бы более эффективным, поскольку count было бы временем выполнения O (n). Вы также можете ознакомиться с более подробной информацией о цикле по массивам.
🎉🎉🎉 Мы завершили первую часть нашего погружения в массивы! Спасибо, что держались со мной так далеко. Надеюсь, вы лучше познакомились с массивами и их различными операциями. Бросьте несколько аплодисментов, прежде чем решите уйти. 👏👏👏 Но! У нас также есть для вас упражнение по круговым буферам, где мы реализуем его с помощью массива. 😄
Круговой буфер
Круговой буфер - это структура данных, в которой используется буфер фиксированного размера, как если бы он был соединен сквозным образом, как круг.
Конечно, мы можем создавать кольцевые буферы с различными структурами данных, такими как связанные списки или массивы. Здесь мы реализуем это с помощью массива.
Из рисунка ниже вы, вероятно, сможете понять, как круговые буферы работают с массивом и как их реализовать.

Методы и свойства, которые следует учитывать
max sizeСвойство для объявления максимального размера буфера.sizeСвойство, отслеживающее общее количество элементов в буфере.frontСвойство, возвращающее элемент в начале буфера.isEmptyМетод проверки, содержит ли буфер элементы или нет.isFullМетод проверки, заполнен ли буфер или нет.enqueue(item: )Метод вставки элемента в заднюю часть буфера.dequeue()Метод, который удаляет и возвращает элемент в начале буфера.
Я настоятельно рекомендую вам нарисовать диаграмму того, как будет выглядеть буферный массив, когда будет добавлено много элементов - enqueued - или написать псевдокод, прежде чем переходить к приведенному ниже коду вместе со мной!

Используйте это изображение как ссылку при создании класса кольцевого буфера.
инструкции
Ниже приведены инструкции по созданию класса кольцевого буфера. Если вы написали псевдокод, я настоятельно рекомендую кодировать его, прежде чем проверять свой. 👇👇👇
- Для создания класса мы используем дженерики, поэтому мы можем объявлять разные типы каждый раз, когда создаем экземпляр класса.
- Создайте массив с необязательным типом, так как мы хотим, чтобы сначала все элементы были равны нулю. мы используем метод
init(repeating:count:)для создания экземпляра массива с повторяющимися элементами в нем. - Создайте инициализатор для пользователей, чтобы объявить размер буфера.
- Создайте удобный инициализатор, в котором пользователь не объявляет размер буфера; это приведет к созданию буфера размером 8. Подробнее об инициализаторах в Swift.
У нас в классе ровно три свойства: bufferMaxSize, который будет объявлен при инициализации или будет иметь размер 8 по умолчанию; size, который начинается с 0, поскольку в буфере нет элементов; и elements, который будет представлять буфер. Перейдем к созданию свойств front, isEmpty и isFull .
- Создайте свойство
front, которое вернет nil, если буфер пуст - Чтобы получить переднюю часть буфера в непустом массиве, мы можем просто вычесть максимальный размер буфера из размера элементов в массиве. Это дает вам индекс первого элемента в массиве буферов.
- Создайте функцию
isEmpty, которая проверяет свойство размера, поскольку мы обновляем его, когда мыenqueueилиdequeueэлементов. - Создайте функцию
isFull, которая сравнивает свойство размера с максимальным размером буфера.
Теперь, когда у нас есть эти свойства для проверки, давайте создадим функции enqueue и dequeue для обновления массива буферов и свойства size.
- Проверьте, пуст ли буфер. Если это так, мы можем просто установить последний индекс равным добавленному элементу.
- Если буфер не пуст, мы начнем перебирать индексы. Убедитесь, что индекс не выходит за пределы допустимого диапазона, поскольку нам нужно будет проверить элемент перед ним, чтобы обновить текущее значение.
- После прохождения через все (завершение смещения всех элементов вперед) мы устанавливаем последний элемент равным элементу в очереди.
- Мы не хотим постоянно увеличивать размер, даже когда буфер заполнен. Поэтому мы просто используем
logical operator, чтобы убедиться, что он не заполнен, и увеличиваем размер.
- Используйте
logical operator(!), Чтобы убедиться, что массив не пуст. - Буфер не пустой, поэтому мы обновляем передний элемент, чтобы он стал равным нулю, уменьшаем счетчик размеров и возвращаем значение переднего элемента.
- Если буферный массив пуст, эта строка будет выполнена, и мы просто вернем nil.
Вы также можете найти полный код кругового буфера здесь.
🎉🎉🎉 Готово! Спасибо, что дочитали до этого места. 💡 Есть вопросы? Свяжитесь со мной или оставьте комментарий ниже. 😃
Ресурсы
Динамические массивы, Интервью Торт
Производительность массивов, Взлом с помощью Swift
📌 Найдите меня в LinkedIn и GitHub здесь. 😄
Примечание редактора. Heartbeat - это онлайн-публикация и сообщество, созданное авторами и посвященное предоставлению первоклассных образовательных ресурсов для специалистов по науке о данных, машинному обучению и глубокому обучению. Мы стремимся поддерживать и вдохновлять разработчиков и инженеров из всех слоев общества.
Независимая редакция, Heartbeat спонсируется и публикуется Comet, платформой MLOps, которая позволяет специалистам по обработке данных и группам машинного обучения отслеживать, сравнивать, объяснять и оптимизировать свои эксперименты. Мы платим участникам и не продаем рекламу.
Если вы хотите внести свой вклад, отправляйтесь на наш призыв к участникам. Вы также можете подписаться на наши еженедельные информационные бюллетени (Deep Learning Weekly и Comet Newsletter), присоединиться к нам в » «Slack и подписаться на Comet в Twitter и LinkedIn для получения ресурсов, событий и гораздо больше, что поможет вам быстрее и лучше строить лучшие модели машинного обучения.