В конце прошлой недели мы выпустили нашу первую версию библиотеки Graph Algorithms на 2019 год, в которой представлены несколько новых алгоритмов, некоторые оптимизации производительности и, конечно же, исправления ошибок.
Обновление. Книга О’Рейли Графические алгоритмы на Apache Spark и Neo4j Book теперь доступна для бесплатной загрузки с сайта neo4j.com.
tl;dr
В этом выпуске представлены алгоритмы ArticleRank и Сходство Пирсона, поддержка проекции Cypher для алгоритмов подобия и оптимизация производительности для алгоритма Лувена.
Вы можете загрузить эти обновления для Neo4j 3.4 или 3.5, и если вы используете Neo4j Desktop, он автоматически загрузит последнюю версию.
Не забудьте прочитать подробный пост Jennifer Reif, в котором объясняется, как устанавливать плагины, если вы еще не использовали их.
Сходство Пирсона
Мы добавили поддержку Сходства Пирсона по просьбе моего коллеги Уилла Лайона. Сходство Пирсона - это мера линейной корреляции между двумя наборами значений.
Мы можем использовать алгоритм подобия Пирсона, чтобы определить сходство между двумя вещами. Затем мы могли бы использовать вычисленное сходство как часть рекомендательного запроса.
Уилл ранее показал, как вычислить сходство Пирсона непосредственно в Cypher в рамках Песочницы рекомендаций, поэтому я подумал, что попробую перевести его работу. Следующий запрос позволяет найти пользователей, наиболее похожих на конкретного пользователя в расширенном наборе данных фильмов:
MATCH (u1:User {name:"Cynthia Freeman"})-[r:RATED]->(m:Movie)
WITH u1, avg(r.rating) AS u1_mean
MATCH (u1)-[r1:RATED]->(m:Movie)<-[r2:RATED]-(u2:User)
WITH u1, u1_mean, u2, COLLECT({r1: r1, r2: r2}) AS ratings
MATCH (u2)-[r:RATED]->(m:Movie)
WITH u1, u1_mean, u2, avg(r.rating) AS u2_mean, ratings
UNWIND ratings AS r
WITH sum( (r.r1.rating-u1_mean) * (r.r2.rating-u2_mean) ) AS nom,
sqrt( sum( (r.r1.rating - u1_mean)^2) * sum( (r.r2.rating - u2_mean) ^2)) AS denom,
u1, u2 WHERE denom <> 0
RETURN u1.name, u2.name, nom/denom AS pearson, nom, denom
ORDER BY pearson DESC LIMIT 100;
Эквивалентный запрос с использованием функции из библиотеки Graph Algorithms выглядит следующим образом:
MATCH (p1:User {name: "Cynthia Freeman"})-[x:RATED]->(m:Movie)
WITH p1, algo.similarity.asVector(m, x.rating) AS p1s
MATCH (m)<-[y:RATED]-(p2:User)
WITH p1, p2, p1s, algo.similarity.asVector(m, y.rating) AS p2s
RETURN p1.name,
p2.name,
algo.similarity.pearson(p1s, p2s,{vectorType: "maps"}) AS sim
ORDER BY sim DESC

Поскольку для подобия Пирсона необходимо вычислить средний рейтинг пользователя по всем фильмам, которые он оценил, мы должны использовать несколько иной подход к подготовке данных, чем с другими алгоритмами подобия, которые рассчитываются исключительно на основе оценок, пересекающихся с рейтингами другого пользователя.
algo.similarity.asVector преобразует наши пары фильмов и рейтингов в список карт, содержащий категории и веса. Затем мы можем передать эти списки в функцию, убедившись, что мы передали параметр vectorType: «maps», чтобы функция знала, какой формат передается.
Если у нас есть два вектора значений одинаковой длины, мы можем передать их напрямую, не выполняя этого преобразования данных и без дополнительного параметра:
RETURN algo.similarity.pearson([1,2,3], [4,5,6])
Существует также процедура, которая может использоваться для вычисления сходства между более крупными наборами данных.
Поддержка Cypher Projection
Говоря о процедурах подобия ... мы добавили поддержку проекции Cypher к процедурам подобия Пирсона, сходства косинуса и евклидова расстояния, что полезно для уменьшения использования памяти при вычислении сходства с большими векторами подобия.
Например, в наборе данных рекомендаций, если мы хотим вычислить сходство между всеми парами пользователей на основе рейтингов фильмов, нам нужно будет построить векторы с размером, равным количеству фильмов. У нас есть 9 125 фильмов в этом наборе данных, поэтому у нас будет вектор, содержащий 9 125 элементов для каждого пользователя, даже несмотря на то, что большинство значений в этих векторах будет NaN, поскольку пользователи, как правило, оценивают только небольшое количество фильмов.
Если вместо этого мы используем проекцию Cypher, процедура строит сжатые векторы, которые занимают гораздо меньше места.
В любом случае, достаточно о внутреннем устройстве, давайте посмотрим, как мы будем использовать эту функцию в наборе данных. Следующий запрос находит пользователей, наиболее похожих на каждого пользователя, при условии, что они имеют минимальное сходство 0,1. Затем он создает ПОДОБНЫЕ отношения между пользователями:
WITH "MATCH (user:User)-[rated:RATED]->(c)
RETURN id(user) AS item, id(c) AS category,
rated.rating AS weight" AS query
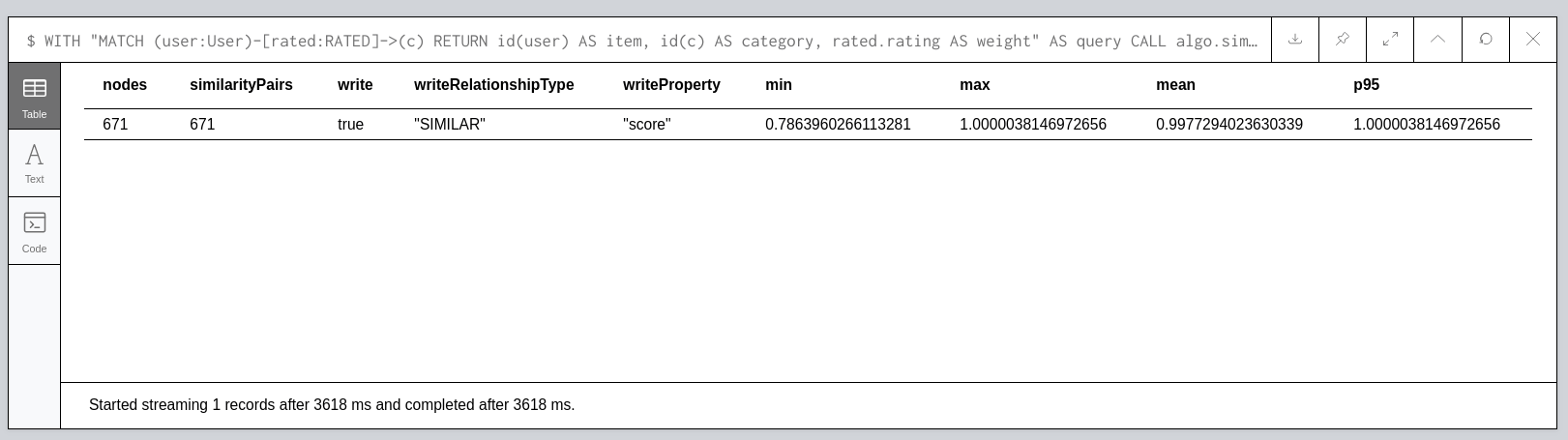
CALL algo.similarity.pearson(query, {
graph: 'cypher', topK: 1, similarityCutoff: 0.1, write:true
})
YIELD nodes, similarityPairs, write, writeRelationshipType, writeProperty, min, max, mean, stdDev, p95
RETURN nodes, similarityPairs, write, writeRelationshipType, writeProperty, min, max, mean, p95
Следующий график из браузера Neo4j показывает нам добавленные дополнительные отношения:

СтатьяRank
ArticleRank - это небольшая вариация популярного алгоритма PageRank. Это снижает предвзятость PageRank в отношении присвоения более высоких оценок узлам со связями от узлов, которые имеют мало исходящих связей.
Чтобы найти оценку для данного узла, PageRank подсчитывает все входящие оценки и делит их на количество исходящих ссылок для каждой данной входящей страницы. ArticleRank присваивает оценку, подсчитывая все входящие оценки, и делит их на среднее количество исходящих ссылок плюс количество исходящих ссылок для каждой данной входящей страницы.

Этот алгоритм часто предпочитают для анализа в сетях цитирования, и Томаз Братанич написал в блоге сообщение, показывающее, как использовать этот алгоритм в сети цитирования Стэнфордской теории физики высоких энергий.
Он также сравнивает результаты с результатами, полученными с помощью алгоритма PageRank.
Тимоти Холдсворт работал над этим алгоритмом, поэтому спасибо Тимоти за это полезное дополнение к библиотеке!
Исправление ошибок
Этот выпуск также содержит исправление для исключения ArrayOutOfBounds, которое иногда возникало при загрузке отношений между собой.
Мы также провели некоторую оптимизацию производительности алгоритма Лувена и наблюдали ускорение в 7–8 раз на тестовых наборах данных.
Мы надеемся, что вам понравится этот выпуск, и если у вас есть какие-либо вопросы или предложения, отправьте нам письмо по адресу [email protected]
