
Boosting и Bagging: как разработать надежный алгоритм машинного обучения
Машинное обучение и наука о данных требуют большего, чем просто бросание данных в библиотеку Python и использование всего, что получится.
Начальная загрузка / бэггинг / бустинг
Машинное обучение и наука о данных требуют большего, чем просто закидывать данные в библиотеку Python и использовать все, что получится.
Специалистам по данным необходимо действительно понимать данные и процессы, стоящие за ними, чтобы иметь возможность внедрить успешную систему.
Одна из ключевых методологий реализации - знать, когда модель может получить выгоду от использования методов начальной загрузки. Это так называемые ансамблевые модели. Некоторыми примерами ансамблевых моделей являются AdaBoost и Stochastic Gradient Boosting.
Зачем использовать ансамблевые модели?
Они могут помочь повысить точность алгоритма или сделать модель более надежной. Двумя примерами этого являются ускорение и упаковка. Повышение и упаковка - это темы, которые должны знать специалисты по данным и инженеры по машинному обучению, особенно если вы планируете пройти собеседование по науке о данных / машинному обучению.
По сути, ансамблевое обучение соответствует слову ансамбль. За исключением того, что вместо того, чтобы несколько человек поют в разных октавах, создавая одну прекрасную гармонию (каждый голос заполняет пустоту другого), ансамблевое обучение использует от сотен до тысяч моделей одного и того же алгоритма, которые работают вместе, чтобы найти правильную классификацию.
Еще один способ подумать об ансамблевом обучении - это басня о слепых и слоне. В этом примере каждый слепой ощущает разные части слона, поэтому они расходятся во мнениях о том, что они чувствуют. Однако, если бы они собрались вместе и обсудили это, они могли бы понять, что смотрят на разные части одного и того же.
Использование таких методов, как повышение и упаковка, привело к повышению надежности статистических моделей и уменьшению дисперсии.
Теперь возникает вопрос, в чем разница между всеми этими разными словами «Б»?
Начальная загрузка
Давайте сначала поговорим об очень важной концепции начальной загрузки. Многие специалисты по данным упускают это из виду и сразу же начинают объяснять бустинг и бэггинг. Но оба требуют начальной загрузки.
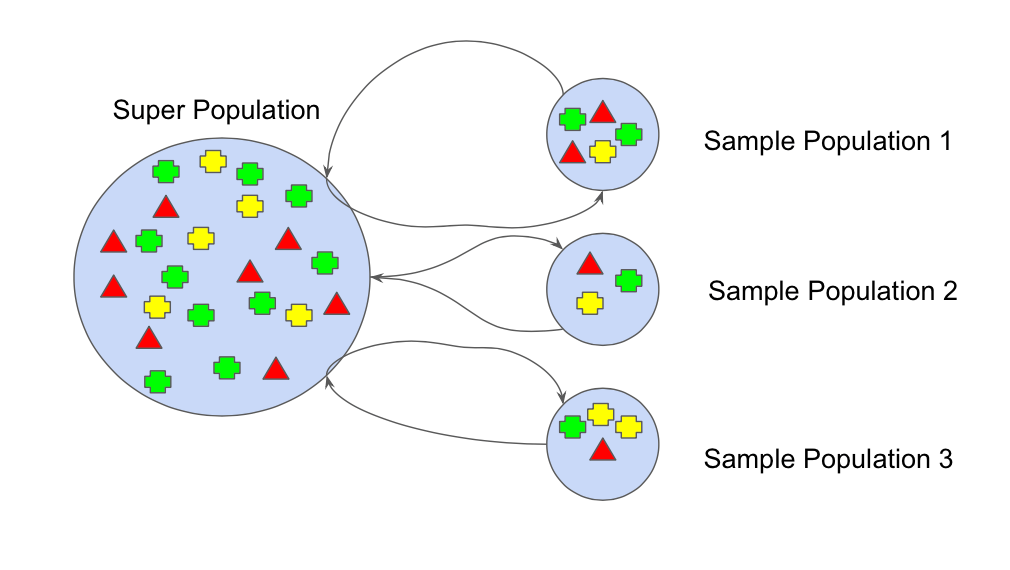
В машинном обучении метод начальной загрузки относится к случайной выборке с заменой. Этот образец называется повторным сэмплом. Это позволяет модели или алгоритму лучше понять различные смещения, дисперсии и особенности, существующие в повторной выборке. Выборка данных позволяет повторной выборке содержать характеристики, отличные от тех, которые она могла бы содержать в целом. Это показано на Рисунке 1, где каждая выборка состоит из разных частей, и ни одна из них не идентична. Затем это повлияет на общее среднее значение, стандартное отклонение и другие описательные показатели набора данных. В свою очередь, он может разрабатывать более надежные модели.
Начальная загрузка также отлично подходит для наборов данных небольшого размера, которые могут иметь тенденцию переобучаться. Фактически, мы рекомендовали это одной компании, которая была обеспокоена тем, что их наборы данных далеки от больших данных. В этом случае оптимальным решением может быть начальная загрузка, поскольку алгоритмы, использующие начальную загрузку, могут быть более надежными и обрабатывать новые наборы данных в зависимости от методологии (ускорение или упаковка).
Причина использования метода начальной загрузки заключается в том, что он может проверить стабильность решения. Он может повысить надежность за счет использования нескольких наборов выборочных данных и тестирования нескольких моделей. Возможно, один набор выборочных данных имеет большее среднее значение, чем другой, или другое стандартное отклонение. Это может привести к поломке модели, которая была переобучена и не протестирована с использованием наборов данных с различными вариантами.
Одна из многих причин, по которой бутстрапирование стало обычным явлением, - это увеличение вычислительной мощности. Это позволяет выполнять гораздо больше перестановок с разными повторными выборками, чем это было возможно в противном случае. Как будет обсуждаться ниже, бутстреппинг используется как в упаковке, так и в ускорении.
Упаковка
Бэггинг на самом деле относится к (агрегаторам начальной загрузки). Практически любая статья или сообщение, в котором упоминается использование алгоритмов упаковки, также будет ссылаться на Лео Бреймана, который написал статью в 1996 году под названием« Предикторы упаковки ».
Где Лео описывает упаковку в мешки как:
«Предикторы упаковки в пакеты - это метод создания нескольких версий предиктора и их использования для получения агрегированного предиктора».
Пакетирование помогает уменьшить отклонение от моделей, которые могут быть очень точными, но только на данных, на которых они были обучены. Это также известно как переоснащение.
Переоснащение - это когда функция слишком хорошо соответствует данным. Как правило, это связано с тем, что фактическое уравнение слишком сложно для учета каждой точки данных и выбросов.
Другой пример алгоритма, который легко переобучить, - это дерево решений. Модели, разработанные с использованием деревьев решений, требуют очень простой эвристики. Деревья решений состоят из набора операторов if-else, выполняемых в определенном порядке. Таким образом, если набор данных будет изменен на новый набор данных, который может иметь некоторую предвзятость или различие вместо основных характеристик по сравнению с предыдущим набором, модель не будет такой точной. Это связано с тем, что данные также не будут соответствовать модели (что в любом случае является обратным утверждением).
Бэггинг обходит это, создавая собственную дисперсию среди данных путем выборки и замены данных, в то время как он проверяет несколько гипотез (моделей). В свою очередь, это снижает шум за счет использования нескольких выборок, которые, скорее всего, будут состоять из данных с различными атрибутами (медиана, среднее значение и т. Д.).
После того, как каждая модель разработала гипотезу, модели используют голосование для классификации или усреднение для регрессии. Здесь и вступает в игру «агрегирование» в «агрегировании бутстрапа». Каждая гипотеза имеет такой же вес, как и все остальные. Когда мы позже обсудим повышение, это одно из мест, где две методологии различаются.
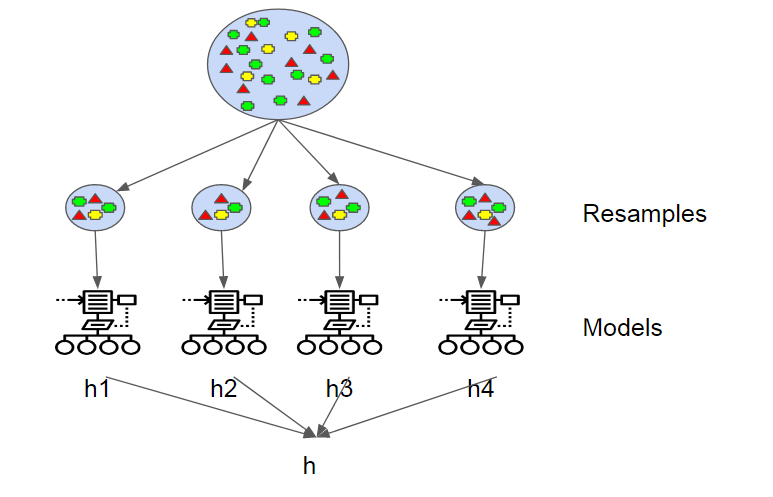
По сути, все эти модели работают одновременно, и голосование по поводу того, какая гипотеза является наиболее точной.
Это помогает уменьшить дисперсию, т.е. уменьшить переобучение.
Повышение
Повышение относится к группе алгоритмов, которые используют средневзвешенные значения, чтобы сделать из слабых учеников более сильных. В отличие от бэггинга, при котором каждая модель запускалась независимо, а затем агрегировала результаты в конце без предпочтения какой-либо модели, бустинг - это все о «командной работе». Каждая запущенная модель определяет, на каких функциях будет сосредоточена следующая модель.
Повышение также требует начальной загрузки. Однако здесь есть еще одно отличие. В отличие от упаковки в пакеты, увеличение веса каждой выборки данных. Это означает, что одни образцы будут запускаться чаще, чем другие.
Зачем нужно взвешивать образцы данных?
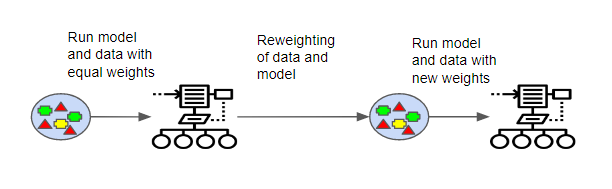
При ускорении запускает каждую модель, она отслеживает, какие образцы данных наиболее успешны, а какие нет. Наборы данных с наиболее неверно классифицированными выходными данными получают больший вес. Эти данные считаются более сложными и требуют большего количества итераций для правильного обучения модели.
На этапе фактической классификации также есть разница в том, как бустинг обрабатывает модели. При повышении уровень ошибок модели отслеживается, потому что лучшим моделям присваивается лучший вес.
Таким образом, когда происходит «голосование», как в случае с мешками, модели с лучшими результатами имеют большее влияние на конечный результат.
Резюме
Повышение и упаковка - отличные методы для уменьшения дисперсии. Методы ансамбля обычно превосходят одну модель. Вот почему многие победители Kaggle использовали ансамблевые методики. То, что здесь не обсуждалось, - это укладка. (Для этого нужен отдельный пост.)
Однако они не решат все проблемы, и у них самих есть свои проблемы. Есть разные причины, по которым вы бы использовали одно вместо другого. Бэггинг отлично подходит для уменьшения дисперсии при переобучении модели. Однако бустинг, скорее всего, будет лучшим выбором из двух методов. Повышение также может вызвать проблемы с производительностью. Это также отлично подходит для уменьшения смещения в модели недостаточного соответствия.
Вот тут-то и пригодятся опыт и знания в предметной области! Можно легко перейти на первую работающую модель. Однако важно проанализировать алгоритм и все функции, которые он выбирает. Например, если дерево решений устанавливает определенные листья, возникает вопрос, почему! Если вы не можете поддержать это с помощью других точек данных и визуальных элементов, вероятно, не стоит реализовывать его.
Речь идет не только о том, чтобы попробовать AdaBoost или случайные леса на различных наборах данных. Окончательный алгоритм зависит от результатов и поддержки.