Простая для понимания, слабосвязанная и легко тестируемая — вот лишь некоторые из преимуществ этой архитектуры, ориентированной на API.

Одно из самых важных решений, которое вы должны принять при создании нового приложения, — это структура его архитектуры. Принятие неправильного решения или, что еще хуже, отсутствие набросков архитектуры вообще может отбросить вас в будущее.
Есть так много соображений, от тестируемости до масштабируемости и читабельности, как вы решаете, какую архитектуру использовать?
Позвольте мне представить вам устойчивую архитектуру API, разработанную как решение, подходящее для большинства случаев использования API и обеспечивающее прочную архитектурную основу для вашего API.
Проблема
Прежде чем я углублюсь в детали архитектуры устойчивого API, стоит понять проблему, которую я пытаюсь решить. Если вы хотите погрузиться прямо в детали архитектуры, вы не потеряете понимание самой архитектуры, пропустив этот раздел.
Существует много задокументированных архитектур для создания программного обеспечения. Например, Многоуровневая архитектура, Чистая архитектура или Гексагональная архитектура — это хорошие архитектуры? Да, но все они очень общие и предназначены для всех типов приложений, которые вы только можете себе представить.
Кроме того, какой из них вы выбираете? Например, многоуровневая архитектура отлично подходит для небольших сервисов, но плохо масштабируется для более крупных сервисов. Hexagonal превосходно обеспечивает изоляцию ваших знаний о приложении от внешнего мира, но оставляет архитектуру основной логики приложения в значительной степени неопределенной.
Это не делает их неподходящими для API, и моя архитектура определенно опирается на несколько существующих архитектур, включая описанные выше. Однако контекстуализировать их и применить к собственным приложениям может быть сложно.
Устойчивая архитектура API
Я хотел создать архитектуру, которую можно было бы легко понять и применить практически к любому API. В частности, я хотел убедиться, что любой, кто использует архитектуру, получил надежный план для использования своего API, чтобы он не превратился в запутанный беспорядок и, следовательно, в кошмар для обслуживания.
Его легко тестировать, он несвязан и фокусируется на предметной области.
Если у вас возникли проблемы с пониманием каких-либо разделов, пожалуйста, оставьте комментарий с любыми вопросами, я буду рад попытаться помочь ответить на них. Кроме того, в конце статьи приведен полностью рабочий пример фиктивного API, созданного с использованием этой архитектуры.
Слои архитектуры
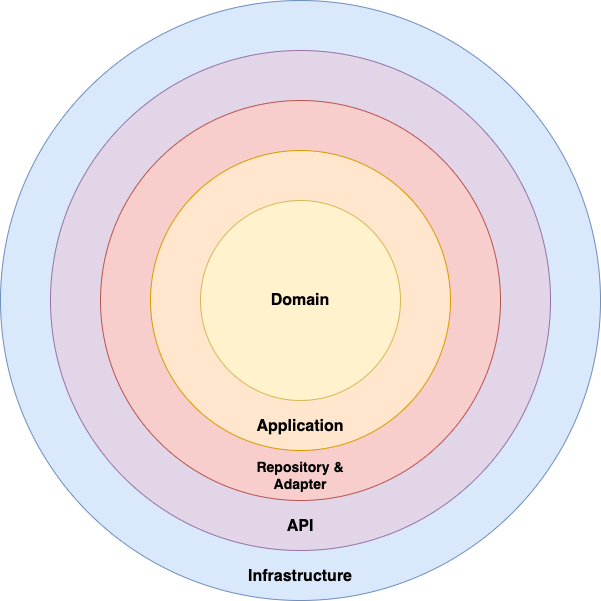
В конечном счете, именно так выглядит архитектура с точки зрения слоев. Внешние слои считаются низкоуровневыми деталями и, вероятно, будут одинаковыми для всех приложений на вашем предприятии. В то время как внутренние слои содержат то, что делает ваше приложение уникальным. Посередине находится уровень Репозиторий и адаптер, который защищает ядро вашего приложения (два центральных уровня) от влияния изменений в самом API и любой инфраструктуре, необходимой для работы вашего сервиса.
Каждый уровень может зависеть только от вещей на своем собственном уровне и уровнях внутри него (за исключением интерфейсов, которые будут важны позже). Следовательно, сам домен не должен иметь зависимостей ни от чего за пределами уровня домена. Уровень Приложения может зависеть от самого себя, от уровня Domain и так далее.
Мы подробно рассмотрим некоторые ключевые моменты каждого слоя позже в этой статье, а пока вот обзор каждого слоя:
- Инфраструктура — этот уровень будет содержать все, что является внешним по отношению к вашему приложению. Примеры включают балансировщик нагрузки, любые базы данных, а также очереди сообщений.
- API.Уровень API полностью отвечает за определение конечных точек вашего API, а также является точкой входа и выхода для вашего приложения. Этот уровень в основном содержит контроллеры, а также любые вспомогательные классы, обеспечивающие аутентификацию, проверку и представление ответов API.
- Репозиторий и адаптер —ключевой уровень, гарантирующий, что ничто вне вашего приложения не повлияет на внутри. Хотя репозиторий обычно выступает в роли адаптера, я хотел, чтобы конкретное упоминание репозитория подчеркивало одноименный шаблон (о котором мы вскоре подробно расскажем).
- Приложение — первый из двух основных уровней, уровень приложения, на котором живут специфические для приложения бизнес-правила. Он не должен содержать никакой доменной логики и обеспечивает связующее звено между вашим доменом и остальной частью приложения. В основном этот слой будет состоять из классов обслуживания.
- Домен — наконец, Домен. Этот слой содержит объекты предметной области, объекты-значения и службы предметной области (при необходимости). Скорее всего, он будет довольно небольшим, в зависимости от размера вашего домена, и не будет подвержен слишком большим изменениям после полной реализации.
Обоснование выбора этих уровней основано на многолетнем опыте работы с API — как минимум, каждому API понадобятся эти уровни. Каждый слой играет важную роль, и, надеюсь, относительно легко представить, как код вашего API будет вписываться в эти слои.
Хотя я бы рекомендовал начинать с этих слоев, нет никаких причин, по которым вы не можете добавить больше слоев, если они нужны вашему приложению. Обычным следующим шагом для этой архитектуры будет добавление асинхронной функциональности, которую эта архитектура сможет обрабатывать с помощью настройки уровней (например, уровень API, распространяющийся на потребителей, например).
Какие преимущества дают нам эти слои?
Отличный вопрос, так как он может быть не сразу очевиден, если вы не привыкли работать со слоями в архитектуре — мне потребовалось довольно много времени, чтобы действительно увидеть в них ценность.
Распространенным принципом в инженерии является Принцип единой ответственности — буква S в слове SOLID. Он обычно используется при разработке классов, но также применяется к более крупным конструкциям, таким как библиотеки и приложения.
В случае с устойчивой архитектурой API каждый уровень несет единственную ответственность, которую я описал выше. Кроме того, мы не хотим, чтобы обязанности пересекались. Мы хотим, чтобы их соответствующие проблемы были разделены, поэтому, например, ничто на уровне Infrastructure не должно влиять на любой другой уровень.
Этот принцип называется Разделение интересов, и это отдельная тема — я подробно описал его в этой статье.
Для целей нашей архитектуры классическим нарушением этого принципа является передача объектов от слоя к слою. Например, используемый вами фреймворк может автоматически анализировать HTTP-запросы в объект в ваших контроллерах. Само по себе это не проблема, мы не должны бороться с фреймворком, но мы не должны передавать этот объект ни в какие слои ниже, иначе они теперь будут знать все о используемом вами фреймворке — нарушая принцип.
Основная причина введения слоев в наши приложения — ограничить область любых изменений как можно меньшим числом слоев. Если мы решим изменить фреймворк, на котором построен наш API, или обновить существующий фреймворк, мы не хотим, чтобы это изменение повлияло на наше основное приложение. Предполагая, что у нас есть правильное распределение по слоям, это изменение может подействовать только на самые внешние слои.
Преодоление границ с помощью инверсии зависимостей
Хотя мы хотим, чтобы наши слои были разделены с точки зрения их проблем, нашему приложению необходимо пересекать границы, чтобы функционировать, иначе запросы к нашему API никогда не прошли бы через балансировщик нагрузки!
Однако имейте в виду, что внутренний круг может ничего не знать ни о чем вне себя. Например, уровень API не должен ничего знать об уровне Инфраструктура, а уровень Приложения ничего не должен знать о Репозитории и Уровень адаптера, API или инфраструктуры.
Чтобы достичь этого, мы снова опираемся на SOLID — на этот раз мы используем «D», что означает принцип инверсии зависимостей. В нем говорится, что мы должны полагаться на абстракции, а не на конкреции. Проще говоря, наши классы должны зависеть от интерфейсов, а не от конкретных классов.
Это обеспечивает слабую связанность слоев и дальнейшее разделение задач. Если класс зависит от интерфейса, мы можем использовать внедрение зависимостей для внедрения любого заданного класса, который реализует этот интерфейс во время выполнения. Следовательно, наш класс ничего не знает о конкретном классе, он просто знает, что ему будет предоставлен класс, потенциально из любого уровня, который придерживается интерфейса, необходимого для его функционирования.
Мы более подробно рассмотрим, как мы можем использовать инверсию зависимостей, в следующем разделе.
Шаблон репозитория и адаптеры
Еще одна ключевая часть этой архитектуры — защита двух самых внутренних уровней от внешних факторов, включая изменения API, которые клиенты используют для взаимодействия с вашим приложением.
Для этого нам нужны два аспекта: репозитории и адаптеры. Репозитории — это тип адаптера, но я специально назвал репозитории из-за шаблона репозитория.
В статье, указанной выше, много подробностей, поэтому обязательно прочитайте ее. Короче говоря, репозитории отвечают за перевод между уровнем приложения и базой данных на уровне инфраструктуры. Мы можем сделать это, используя инверсию зависимостей, которая была рассмотрена в предыдущем разделе.
Шаблон репозитория с инверсией зависимостей работает следующим образом:
- Мы определяем интерфейс, как правило, на уровне Приложение (вы также можете поместить его на уровень Домен, существуют разные мнения о том, где должны располагаться интерфейсы репозитория).
- Любые классы на уровне Application, которым необходимо сохранять данные, делают это с помощью интерфейса, который мы создали на шаге 1 в конструкторе класса.
- Конкретная реализация репозитория создается на уровне Репозиторий и адаптер и внедряется в классы, которым она нужна во время выполнения.
Для тех, кто предпочитает визуальное представление, это будет выглядеть так:

В нашем третьем шаге выше мы внедрили бы OrderRepository в класс UpdateOrder во время выполнения.
После выполнения этих шагов наш уровень Application знает только то, что ему будет предоставлен класс, соответствующий требуемому интерфейсу, но ничего не знает о том, как сохраняются данные. Если, например, база данных была изменена с MySQL на MongoDB, прикладной уровень никогда не узнает об этом, поскольку вместо MySQL будет введена конкретная реализация для MongoDB.
И последнее соображение касается данных, передаваемых в репозитории и, в частности, из них. Большинство библиотек для взаимодействия с базами данных (например, ORM) будут иметь свои собственные классы для возврата данных — их не следует передавать обратно напрямую из репозитория. Вместо этого вы должны возвращать сущности предметной области и объекты-значения. Если бы мы возвращали объекты из библиотек базы данных, уровень приложения был бы затронут, если бы мы изменили базу данных или даже изменили схемы в базе данных.
Все вышесказанное применимо и к адаптерам. Как упоминалось ранее, репозитории — это тип адаптера, но мы также можем создавать адаптеры для других взаимодействий. Вот некоторые примеры:
- Получение/хранение данных из сервисов AWS, таких как S3
- Публикация сообщений в брокере сообщений, таком как Kafka
- Вызов других API внутри вашего предприятия или извне
Те же шаги, которые мы определили для репозиториев, применимы и к адаптерам.
Дизайн, управляемый доменом
Поскольку предметная область находится в центре архитектуры устойчивого API, было бы неправильно не коснуться предметно-ориентированного проектирования (DDD).
Это не новая концепция, но я настоятельно рекомендую прочитать Внедрение предметно-ориентированного проектирования, если вы еще этого не сделали. Хотя эта архитектура будет работать без глубоких знаний DDD, она, безусловно, будет намного более мощной, если согласовать модель предметной области для вашего приложения.
В качестве отправной точки подумайте о классах, которые делают вашу службу уникальной на вашем предприятии, и поместите их на уровень Domain. Обычно это простые классы данных, а также классы, содержащие логику предметной области. Это сильно упрощает DDD, поэтому я рекомендую узнать о нем больше, если вы еще этого не сделали.
На моем нынешнем месте работы предметно-ориентированное проектирование стало настолько уважаемым, что основные модели предметных областей известны и понятны заинтересованным сторонам и даже генеральному директору. Я не могу достаточно высоко оценить силу того, что все говорят на одном и том же вездесущем языке.
Пример устойчивой архитектуры API
Я создал полностью работающий фиктивный API, используя устойчивую архитектуру API, в качестве руководства для всех, кто хочет его использовать. Не стесняйтесь копировать код как есть и изменять для вашего случая использования!
Он построен с использованием C# в фреймворке .NET Core, но эта архитектура будет работать для любого языка и фреймворка. Он доступен на GitHub здесь, а руководство по навигации по коду включено в README. Кроме того, сам код изобилует комментариями, поясняющими, как он относится к архитектуре, и у каждого класса есть комментарий, идентифицирующий его уровень.
Если вы дочитали до этого места — большое спасибо за прочтение! Я надеюсь, что вы нашли архитектуру и информацию полезными, и я хотел бы услышать любые ваши комментарии, мысли или вопросы по архитектуре.
Want to Connect With the Author? Looking to expand your technical knowledge but not sure what to read? I run a free newsletter providing fortnightly technical book recommendations, including my key takeaways from the books. Interested? Sign up here!