Пошаговое руководство о том, как выполнить прогноз временных рядов в R
У вас есть много данных временных рядов, и вам интересно, как вы можете использовать эти данные для создания прогноза на будущее?
Если ваш ответ да, то вы попали по адресу…

В этой статье позвольте мне рассказать вам о простом в реализации методе прогнозирования набора данных временных рядов с использованием модели Seasonal ARIMA. В демонстрационных целях мы будем использовать Набор данных о продажах рыбы под лицензией MIT и набор данных о ценах на акции Yahoo Finance (загруженный непосредственно в R)…
Исследовательский анализ данных
Прежде чем приступить к любой задаче, связанной с наукой о данных или ИИ, рекомендуется выполнить исследовательский анализ данных (EDA). Во время EDA вы получите ценную информацию, которая может существенно повлиять на вашу будущую стратегию моделирования. Если вы не знакомы с EDA, рекомендую вам взглянуть на другую мою историю, в которой я выполняю образец EDA.
Давайте начнем…
В качестве первого шага мы импортируем библиотеки, необходимые для нашего прогноза временных рядов, и считываем данные…
вот как выглядят "голова" и "хвост" нашего набора данных о продажах рыбы…

Из приведенного выше фрагмента видно, что данных намного больше, чем нужно. Наш прогноз временных рядов будет создан для значений продажи. Соответственно, начинаем манипулировать данными и избавляемся от всех переменных, кроме «старт» и «продажи»…
Возвраты журнала рассчитываются по переменной ‘logr’. Они добавлены в отдельный столбец, и теперь заголовок данных выглядит как…

Затем данные форматируются в переменную ts под переменной test_ts.
Давайте представим данные во временной области, чтобы получить представление о том, с чем мы имеем дело…
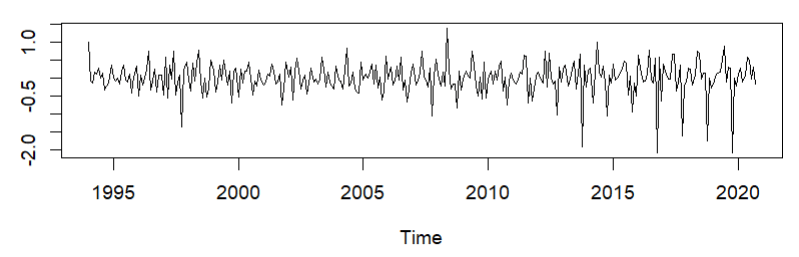
Затем данные разбиваются на «необработанные данные», «сезонность», «тренд» и «остатки». , построенный сверху вниз на следующем изображении

Затем оцениваются функции Автокорреляция и Частичная автокорреляция…


По приведенным выше графикам можно выделить хорошую сезонность наряду с разумными корреляциями в данных, однако Расширенный тест Дики-Фуллера может подтвердить предположение. Полученное значение p ‹ 0,05, поэтому можно с уверенностью предположить, что набор данных является стационарным.

На основании этого вывода для создания прогноза выбирается сезонная модель ARIMA. Коэффициенты для Seasonal ARIMA оцениваются на основе того факта, что набор данных показывает сильную сезонность (seasonal = TRUE)…
…и подводятся итоги


Основываясь на предположении о стационарности, модель работала достаточно хорошо. Давайте посмотрим на пример с другим набором данных…
Прогноз временных рядов финансовых данных Yahoo
Во втором примере снова проверяется стационарность данных, и данные кажутся достаточно стационарными, чтобы использовать сезонный ARIMA для прогноза временных рядов. Реализуется тот же процесс, что и выше…
с входными данными…
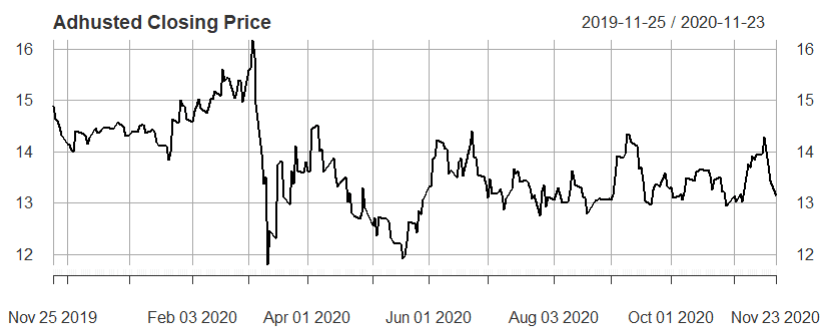
… и вывод и сводка, как показано ниже здесь.


Обсуждение
В целом, мы использовали сезонную модель ARIMA, чтобы соответствовать двум различным (стационарным) наборам данных временных рядов для прогноза. Однако, глядя на результаты, вы можете заметить большую ошибку во втором примере (в наборе финансовых данных Yahoo) по сравнению с первым примером (в наборе данных о продажах рыбы).
Как вы думаете, почему это произошло? Каково твое мнение?
Чтобы ответить на этот вопрос, вам, возможно, придется самостоятельно запустить код для Yahoo Financial Dataset (полный код для обоих примеров приведен в моем репозитории).
Если вы хотите еще больше попробовать прогнозирование временных рядов и изучить другие алгоритмы, такие как SARIMAX и Prophet в Python, вы можете взглянуть на историю ниже.
Если вам понравился мой рассказ и вы хотите перейти к коду и полному набору данных, я опубликовал его в репозитории на моем личном git.
Поставьте репозиторию звезду и свяжитесь со мной по linkedin!
Ура :)