Краткий обзор важных концепций и почему они важны

В моем предыдущем посте о переходе от программного обеспечения к разработке данных я изложил очень общее представление о том, как может выглядеть производственный конвейер и что означают соответствующие концепции. Однако это еще не все. Данные сами по себе ничего не значат ни для вас как инженера, ни для бизнеса, если вы не знаете, как их использовать.
Часто в компаниях естественным образом происходит то, что, пытаясь оставаться на вершине стремительного прогресса технологий и инноваций в соответствующих областях бизнеса, чтобы оставаться конкурентоспособными, они пренебрегают или, скорее, упускают из виду некоторые передовые методы. Для стартапов нет ничего необычного в том, чтобы выбрасывать решения за дверь, чтобы продвинуться вперед и искать «обходные пути», откладывать некоторые надлежащие реализации в пользу MVP.
Одна из распространенных вещей, которая может оказаться в бэклоге «на потом», — это каталогизация данных, которые есть у компании. Это не то, что у всех было бы наивысшим приоритетом, поскольку с самого начала данных не так много. Итак, кажется безобидным игнорировать, каждый сервис просто «запускает и забывает» некоторые байтовые массивы, которые достигают какого-то хранилища, и все, работа выполнена, у нас есть данные.
Через несколько лет появится несколько десятков, а то и сотен микросервисов, отправляющих всевозможные данные, появятся конвейеры, извлекающие данные из третьих сторон, и бизнес захочет принимать разумные решения на основе уже имеющихся у него очень богатых данных. Если вы не приложили некоторых усилий на более раннем этапе своего роста, то здесь вы будете бороться… много. В большинстве случаев компании добавили бы хотя бы реестр схем, возможно, правильную родословную и мечту каждого человека, работающего с данными, — каталог данных.
Реестр схемы
По сути, это централизованный репозиторий для ваших файлов схемы. Они могут быть в формате JSON или AVRO и определять структуру и значение всех свойств внутри всех событий и точек данных, проходящих через системы компании. Эти схемы могут иметь версии и изменяться, а также принадлежат производителям соответствующих данных.
В идеале должен быть пользовательский интерфейс, позволяющий каждому в бизнесе просматривать текущие активные схемы и старые определения.
Каждое событие, отправленное в конвейер, должно быть проверено, и только действительные попадают в хранилище.
{ "schema": "http://schema-def-url", "title": "user account created", "self": { "vendor": "a vendor", "name": "user_account_created", "format": "jsonschema", "version": "1-0-0" }, "type": "object", "properties": { "user_id": { "type": [ "string" ], "description": "the user id..." }, "email": { "type": [ "string" ], "description": "the user email...", "pii": true}, ... "region": { "type": [ "string" ], "description": "..." } }, "required": [ "user_id", "email", ... ] }
Это пример части очень простой схемы. Вы заметите, что он определяет имя и тип всех необходимых свойств. Также есть один дополнительный бит pii: true . Это предназначено для того, чтобы показать, что поле является PII (личной идентифицируемой информацией), поэтому это поле может быть анонимизировано при необходимости (по запросу клиента или по истечении установленного законом срока хранения). В каждое поле может быть добавлено гораздо больше битов, обеспечивающих правильную проверку, хранение и использование — например, максимальная длина, кодировка, тип столбца в таблице, в которую оно преобразуется, и т. д.
Правильно, схемы можно использовать для создания представлений поверх таблицы, где событие хранится так же, как полезная нагрузка JSON, или для материализации в таблицу.
Более того, схемы позволят вам определять классы на их основе и работать с данными более управляемым способом в ваших приложениях (существуют инструменты, которые автоматически генерируют классы на основе определения, чтобы они могли быть частью вашего процесса выпуска для реестр схемы). На его основе можно создать общекорпоративный API, что означает, что все приложения всегда будут на одной странице.
Потоковые данные
Я упомянул, что приложения могут использовать реестр схем для десериализации событий и работы с ними как с классами. В крупной компании у вас будет несколько приложений, производящих события, и, возможно, столько же приложений, потребляющих их из выбранного потокового решения и предпринимающих действия или создающих отчеты на их основе.
Существует 2 типа потоков с точки зрения механизма, с помощью которого приложения получают сообщения:
- pull — означает, что приложения будут извлекать из очереди событий/сообщений всякий раз, когда будут готовы их обработать, а затем фиксируют индикатор, чтобы «запомнить», куда он попал, в случае его смерти. При таком подходе приложение контролирует скорость обработки, смещение и количество извлеченных событий. Это хорошее решение, когда данные передаются постоянно и в больших объемах, оно более надежное из двух, нет риска потери данных, если не произойдет серьезного сбоя. Примером этого является Kafka, одно из самых популярных решений.
- push: приложения получают запрос всякий раз, когда в очередь добавляются новые сообщения. Решения обычно могут быть настроены на повторные попытки несколько раз, и как только они будут приняты, они перемещают «указатель» на следующее место в очереди. Этот подход больше подходит для случаев, когда данные отправляются спорадически и редко и/или обработка не так критична (поскольку, если приложение не ответит OK в течение настроенного количества попыток, сообщения могут быть пропущены, это вне контроля этого приложения). ). Примером этого может служить Pub/Sub от Google.
Приложения будут подписываться на темы (или любую другую абстракцию, связанную с реализацией, используя Kafka здесь) и читать все, но обрабатывать и реагировать только на записи, которые важны для конкретного приложения.
Обычно приложения, являющиеся частью бизнес-операций, потребляют данные из непрерывного потока, но существует также концепция пакетной потоковой передачи. Итак, кратко упомяну разницу:
- Пакетная обработка — это модель, в которой данные накапливаются с течением времени и обрабатываются порциями. Обычно это используется для импорта сторонних данных в хранилище данных с помощью процесса, подобного ETL. Его также можно использовать для импорта агрегированных данных из непрерывного потока, чтобы оптимизировать импорт или сэкономить на цене. Другим вариантом использования может быть перемещение агрегированных данных в другое хранилище, чтобы упростить аналитику или отчетность.
- Модель потоковой обработки относится к модели, в которой данные непрерывно проходят через систему в реальном или близком к реальному времени. Это обычно используется для принятия оперативных решений.
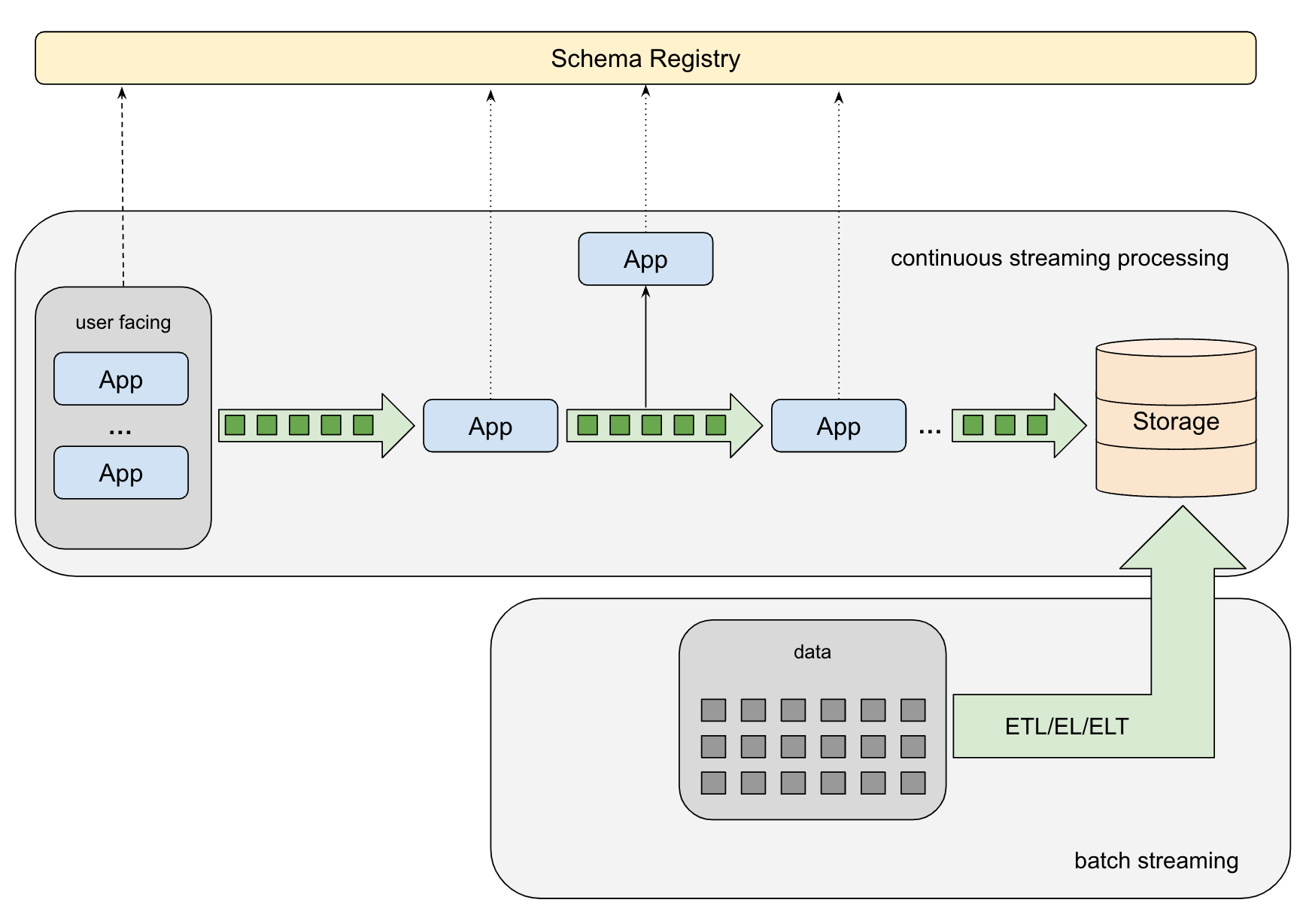
Происхождение данных
В дополнение к структуре данных и значению отдельных свойств, есть еще одна важная информация, которую инженеры должны знать о данных, и это происхождение. В идеале это означало бы возможность отслеживать весь жизненный цикл фрагмента данных и визуализировать его.
Это означает, что нужно показать, где был создан каждый фрагмент данных, были ли и как они преобразованы в конвейере, какими приложениями и где и попали ли они в целевое решение для хранения.
Наличие этого процесса позволит компании:
- обнаружить данные
- отследить ошибки
- внедрить изменения с меньшим риском
- отслеживаемые детали также могут помочь в аудите и соблюдении любых организационных политик и нормативных стандартов.
Каталог данных
Реестр схем и происхождение данных, наряду с другими принципами работы с данными, направлены на то, чтобы сделать данные пригодными для использования и значимыми для бизнеса.
Каталоги данных — это то, что дает пользователям (будь то инженеры данных, специалисты по данным, бизнес-аналитики или разработчики) доступ ко всей этой полезной информации в одном месте. Часто корпоративные решения не содержат никаких фактических данных, а скорее представляют собой набор конечных точек для доступа к запрошенным битам и частям информации из разных источников, агрегированию и представлению в удобном для человека формате. Это означает, что никакие метаданные не дублируются, и, следовательно, не нужно решать проблему синхронизации и актуальности.
По сути, каталог данных — это портал для всех видов метаданных:
- технические — схемы, имена файлов, имена источников данных, имена приложений, которые внесли изменения или каким-либо образом обработали данные и т. д.
- бизнес — любая относящаяся к предметной области информация, имеющая отношение к бизнесу, например описания, комментарии, аннотации, классификации и т. д.
- оперативный — журналы доступа, время обновления и т. д.
Невозможно исчерпать все, что можно сказать о данных и людях умнее, чем я написал подробные статьи и публикации по каждой отдельной концепции, которую я упомянул. Моя цель здесь состояла в том, чтобы просто дать фрагмент каждой из них и побудить вас прочитать больше. Надеюсь, это был успех :)
Спасибо за прочтение!