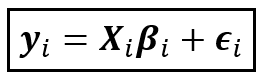
Приведенное выше уравнение представляет собой матричную форму. Предполагая, что на группу приходится t интервалов, k регрессионных переменных на единицу и n единиц, размерности каждой матричной переменной в уравнении следующие.
- y_i — это зависимая переменная для единицы i и вектор размера t X 1.
- x_i — матрица независимых переменных величины t X k.
- beta_i — это матрица коэффициентов размера k X 1, содержащая совокупность (истинное значение) значения коэффициента для k независимой переменной X_i.
- epsilon_i представляет собой матрицу величины t X 1, содержащую член ошибки модели, который является одним членом ошибки для каждого периода t. Член ошибки определяется как разница между наблюдаемым значением и значением моделирования.
В приведенной выше регрессионной модели термин ошибки epsilon_i возникает по следующим причинам.
- Погрешность измерения
- Случайный шум в экспериментальных условиях
- Случайное или преднамеренное упущение одной или связанных объясняющих переменных
- Ошибка неправильного выбора модели регрессии или выбора типа функции для переменной регрессии или переменной отклика в модели
- Ошибки из-за невозможности измерения удельных характеристик на единицу



Предполагается, что все специфичные для юнитов эффекты вводятся Z_i. Матрица Z_i и ее вектор коэффициентов γ_i являются чисто теоретическими терминами, поскольку их нельзя реально наблюдать и измерять.
Наша цель — найти способ оценить все ненаблюдаемые эффекты, содержащиеся в Z_i, то есть влияние Z_i __i на y_i. Чтобы упростить оценку, мы объединим эффекты всех отдельных ненаблюдаемых эффектов в одну переменную. Поскольку Z_i нельзя наблюдать напрямую, необходимо сформулировать эффект исключения Z_i, чтобы измерить эффект Z_i. Для этого мы разрабатываем концепцию статистики, называемую смещением отсутствующих переменных.
Пропущенная переменная погрешность (누락변수편향)
То, что происходит, когда Z_i удаляется из модели во время построения модели на наборе панельных данных, называется отклонением отсутствующей переменной. Если регрессионная модель оценивается без учета Z_i, можно увидеть, что оценочное значение β_cap_i коэффициента модели β_i смещено следующим образом.
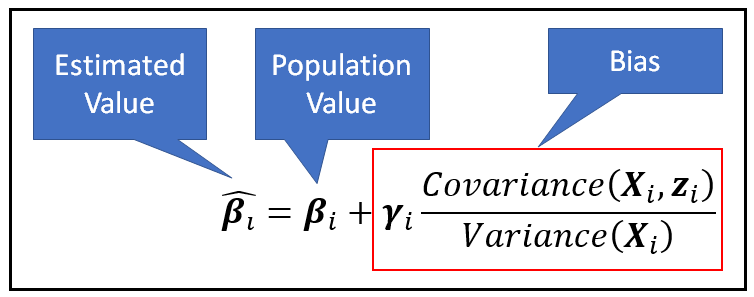
В приведенном выше уравнении видно, что смещение, введенное в оценку β_cap_i, прямо пропорционально ковариации между опущенной переменной z и независимой переменной x. Это дает стимул для построения двух типов регрессионных моделей.
- Модель с фиксированным эффектом, в которой ковариация не равна нулю, то есть когда эффект каждой единицы коррелирует с независимой переменной.
- Модель случайного эффекта, в которой ковариация равна нулю, то есть когда эффект каждой единицы не зависит от независимой переменной.
Модель случайных эффектов
Чтобы понять структуру модели случайного эффекта, необходимо начать с рассмотрения структуры модели FE и сравнения ее с моделью RE. Поэтому давайте еще раз взглянем на структуру модели с фиксированным эффектом.
Основное предположение модели с фиксированным эффектом состоит в том, что ненаблюдаемый эффект коррелирует с независимой переменной модели. В приведенном выше описании смещения отсутствующей переменной мы видим, что если такая корреляция существует, ковариация становится отличной от нуля, что, в свою очередь, пропорционально абсолютному значению этой ковариации. Чтобы противостоять этому смещению, в модели с фиксированным эффектом используется подход, заключающийся в введении в уравнение регрессии члена отклонения, специфичного для единицы, следующим образом.

Z_i γ_i, содержащий все известные специфические для устройства эффекты, был заменен c_i, матрицей размера T X 1, в которой каждый элемент имеет одно и то же значение c_i. Кроме того, c_i является постоянным для всех периодов панели данных.
Оценка c_i, c_cap_i – это переменная вероятности, имеющая распределение вероятностей, в котором среднее значение равно c_i. В модели с фиксированным эффектом предполагается, что оценочное значение всех эффектов, характерных для устройства, имеет одинаковое значение σ².
Поэтому его можно выразить следующим образом.
c_cap_i ~ N(c_i , σ²)

Вернемся к модели случайного эффекта. Если влияние ненаблюдаемой переменной не коррелирует с независимой переменной, эффект целиком является частью ошибки ε_i. Таким образом, в модели произвольного эффекта Z_i, что означает, что все ненаблюдаемые переменные в модели с фиксированным эффектом не могут быть использованы, и, следовательно, специфический для блока эффект c_i, нельзя предположить. Следовательно, необходима новая стратегия, отражающая влияние каждой единицы.
Поскольку Z_i γ_i показывает эффект в единицах, в произвольной модели эффекта он становится вероятностной переменной со средним значением и дисперсией. Следует помнить, что в модели с фиксированным эффектом это была константа.
Модель случайного эффекта предполагает, что специфическое для единицы воздействие на все единицы следует неизвестному случайному распределению вероятностей и распределяется вокруг общего среднего значения. Мы также предполагаем, что это общее среднее является постоянным для всех периодов панели данных.
Это допущение приводит к следующим условным ожиданиям для Z_i γ_i, что означает все специфические для устройства эффекты, которые невозможно наблюдать.

Вернемся к модели,

В приведенном выше уравнении Z_iγ_i-E( Z_iγ_i | X_i) — это изменение эффекта каждой единицы относительно среднего значения, которое указывается как μ_i. Кроме того, уже предполагается, что желтый член уравнения, представляющий собой ожидаемое значение всех специфических для единицы эффектов, имеет постоянное значение α.
Следовательно, приведенное выше уравнение изменяется следующим образом.

Уравнение выше дает следующие идеи.
Следующие два можно увидеть, оценив параметры модели и вычтя эффект Z_iγ_i на единицу.
- Константа α представляет собой среднее значение эффектов каждой единицы. Это не меняется время от времени (независимая от времени переменная), эффективно заменяя член пересечения модели регрессии.
- μ_i ошибки пропорциональна дисперсии эффекта на единицу с центром в среднем, размер которого является постоянным. Ошибка прямо пропорциональна дисперсии индивидуального специфического эффекта.
С этой точки зрения можно понять, почему μ_i и член ошибки ε_i объединяются, чтобы сформировать сложный член ошибки, показанный в скобках. Этот член составной ошибки является определяющей характеристикой модели анализа случайных эффектов. Это связано с тем, что отдельные компоненты члена составной ошибки должны оцениваться как часть процедуры оценки модели RE.
Ниже приводится уравнение модели произвольного эффекта для единицы i и конкретного времени t.
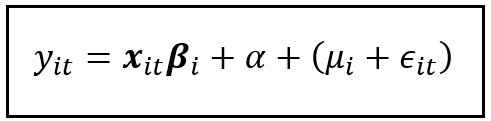
- y_it — значение зависимой переменной единичного объекта i в период t.
- x_it – это вектор-строка размера1 X k, предполагающий наличие k независимых переменных. Здесь x_it — это t-строка матрицы X_i размера T X K, о которой говорилось выше.
- β_i — вектор-столбец величины k X 1.
- Константа α представляет собой общее смещение (среднее значение эффектов всех единиц). Он образует перехват модели линейной регрессии.
- μ_i – дисперсия, возникающая из-за специфического воздействия на единицу i. Нижний индекс времени отсутствует, поскольку предполагается, что он постоянен для всех периодов панели данных. Предполагается, что она случайна и не должна коррелировать с независимой переменной.
- ε_itэто ошибка, оставшаяся после вычитания всех других эффектов, учитываемых i-м объектом в периоде t.
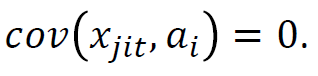
Матричная форма

Характеристики сложных членов ошибки в модели произвольного эффекта
Член составной ошибки модели RE имеет несколько важных характеристик, которые определяют, как оценивать ошибку.

Оценка параметров модели множественной регрессии со случайным эффектом
Оценка параметров модели RE включает следующие два параметра.
1. Оценки компонентов дисперсии σ²_ϵ и σ²_u, связанных с составными остатками (μ + ϵ)
2. Оценка коэффициент регрессии β_i и общее отклонение α (которое образует точку пересечения регрессионной модели)