Задача системы автокоррекции — выяснить, какие слова в документе написаны с ошибками. Эти слова с ошибками могут быть представлены пользователю путем подчеркивания этих слов. Исправление - это задача замены правильно написанного слова на орфографические ошибки.

Современные системы автокоррекции используют высокотехнологичные методы глубокого обучения, которые немного сложны для понимания. Если интересно, вы можете ознакомиться с некоторыми из этих документов.
- Использование Интернета для независимой от языка проверки орфографии и автоисправления
- Насколько сложно разработать идеальную программу проверки орфографии? Кросс-лингвистический анализ с помощью комплексного сетевого подхода
- Автокоррекция: глубокое индуктивное выравнивание зашумленных геометрических аннотаций
- Нейронные сети для исправления и дополнения текста при декодировании с клавиатуры
В этом сообщении блога мы рассмотрим простую и интуитивно понятную систему автокоррекции, основанную на вероятностях. Подробнее в следующих разделах.
Посмотреть этот проект на -› Kaggle Link, GitHub Link
Примечание. Если вы заинтересованы в параллельном изучении кода, я настоятельно рекомендую просмотреть его на Kaggle.
Требования к данным
Самое первое требование системы автокоррекции, которую мы будем создавать, — это данные. Нам нужен надежный (хороший английский и грамматика) корпус текстов. Есть несколько корпусов текстов, находящихся в общественном достоянии. Поскольку это проблема неконтролируемого типа, здесь нам нужен просто текст. Можно использовать любые данные соревнований или любой другой общедоступный набор данных, который имеет столбец текстового поля. В текущей версии я использовал небольшую часть вики-корпуса.
Архитектура

Эта архитектура автокоррекции состоит из 4 компонентов:
1) Фильтрация орфографических ошибок. Одним из простых подходов может быть проверка наличия слова в словаре или его отсутствия. Мы будем использовать текстовый корпус для определения словаря.
2) Механизм подсказки слов: этот механизм предлагает слова-кандидаты на основе удаления, вставки, переключения или замены одного или двух символов в слове. исходное слово.
3) Механизм распределения вероятностей: Распределение вероятностей {ключ(слово) : значение(вероятность)} вычисляется с использованием текстового корпуса. Вероятность каждого кандидата определяется с использованием этого распределения, и наиболее вероятный кандидат является окончательным.
4) Заменить орфографические ошибки: просто замените слово с ошибкой на наиболее вероятное предложение.
Это очень упрощенная архитектура по сравнению с тем, что используется в реальности. Следовательно, его производительность будет не очень хорошей. Но мы можем внести некоторые улучшения в эту архитектуру, чтобы добиться лучших результатов.
Недостатки
— фиксированный результат. то есть «химэ» будет преобразовано только в «время» (поскольку «время» является более частым словом, следовательно, более вероятным), а не «дом» или что-то еще.
- Это основано исключительно на частоте слов. в корпусе.
– Не обращает внимания на контекст.
– Не обращает внимания на части речи, грамматику и пунктуацию.
– Не может предложить то, чего нет в словарь
Улучшения
1) Его можно улучшить, введя вероятности биграмм. Следовательно, он получит некоторый вывод из предыдущих слов.
2) Предложения, которые находятся на меньшем расстоянии от слова с ошибкой, более вероятны. Таким образом, система может быть дополнительно улучшена путем введения функций редактирования минимального расстояния на основе динамического программирования.
Улучшение 1. Введение вероятностей n-грамм для получения контекста из предыдущих слов
Эта идея взята из языковых моделей, основанных на n-граммах. В языковой модели с n-граммами
— Предположим, что вероятность следующего слова зависит только от предыдущей n-граммы.
— Предыдущая n-грамма — это последовательность предыдущих «n» слов.
Условная вероятность слова в позиции «t» в предложении, учитывая, что предшествующие ему слова w(t-1), w(t-2) ….. w(t-n), равна:
P( w(t) | w(t-1)….w(t-n) )
Эту вероятность можно оценить, подсчитав количество вхождений этих серий слов в обучающие данные. появляется после того, как слова от (t-1) до (tn) появляются в обучающих данных.
— Знаменатель — это количество раз, когда слово от t-1 до tn появляется в обучающих данных.

Другими словами, чтобы оценить вероятности на основе n-грамм, сначала найдите количество n-грамм (для знаменателя), затем разделите его на количество (n+1)-грамм (для числителя).
- Функция C(….) обозначает количество вхождений данной последовательности.
— P означает оценку P.
— Знаменатель приведенного выше уравнения – это количество вхождений предыдущих n слов, а числитель – та же последовательность, за которой следует слово w(t).
Теперь проблема с приведенной выше формулой заключается в том, что она не работает, когда счетчик n-грамм равен нулю.
— Предположим, мы столкнулись с n-граммой, которой не было в обучающих данных.
- Тогда последнее уравнение не может быть вычислено (оно становится нулем, деленным на ноль).
Способ обработки нулевого количества состоит в том, чтобы добавить k-сглаживание.
- K-сглаживание добавляет положительную константу k в каждый числитель и k * |V| в знаменатель, где |V| количество слов в словаре.
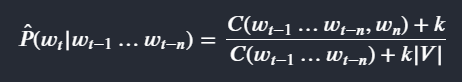
Для n-грамм с нулевым счетом приведенное выше уравнение становится 1/|V|.
— это означает, что любая n-грамма с нулевым счетом имеет одинаковую вероятность 1/|В|.
Улучшение 2: введение функциональности min_edit_diatsnce
Идея исходит из интуиции, что предположения, которые находятся на меньшем расстоянии от слова с ошибкой, более вероятны. Таким образом, система может быть дополнительно улучшена путем введения функций редактирования минимального расстояния на основе динамического программирования.
Таким образом, учитывая строку source[0..i] и строку target[0..j], мы вычислим все комбинации подстрок[i, j] и рассчитаем их расстояние редактирования. Чтобы сделать это эффективно, мы будем использовать таблицу для хранения ранее вычисленных подстрок и использовать их для вычисления более крупных подстрок.
Сначала мы создадим матрицу и обновим каждый элемент в матрице следующим образом:

Внедрение этих улучшений улучшит нашу систему автокоррекции. Давайте посмотрим на демонстрацию того, насколько хорошо это работает.
Демо
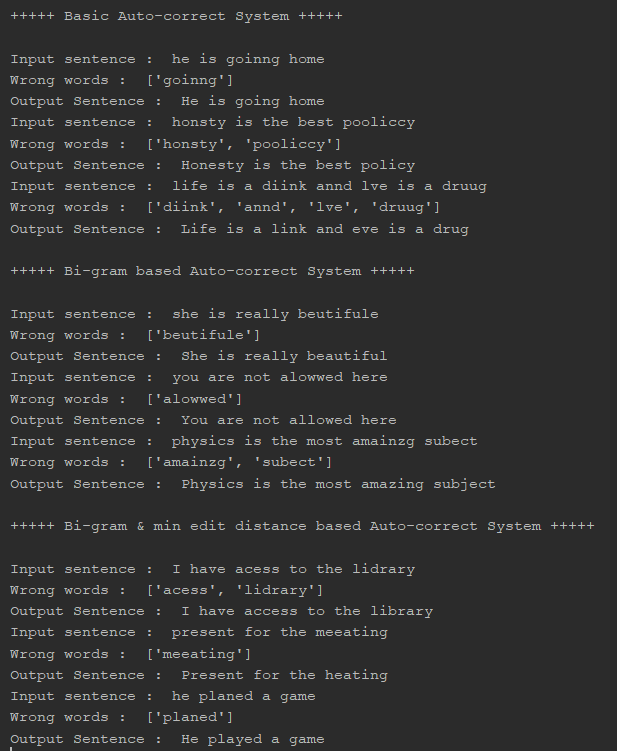
Оценка
Давайте проведем модульное тестирование этой системы, чтобы увидеть, насколько точно она работает.

Вывод
Этот проект представляет собой реализацию системы статистической автокоррекции. Разработанная архитектура дает точность около 52% — 55%. Улучшенная версия этой архитектуры может делать выводы из предыдущих слов, используя вероятности биграмм, а функция минимального расстояния редактирования обеспечивает дальнейшее улучшение. В целом, эта простая система автокоррекции, основанная на вероятности, работала нормально. Чтобы повысить производительность, можно использовать системы автокоррекции, основанные на глубоком обучении.
использованная литература
PS: Спасибо за то, что прочитали это. Приветствуются любые предложения, отзывы, критика, признательность. Если интересно, подписывайтесь на меня в Kaggle, Linked In.