
TLDR
Лучшие способы уменьшить галлюцинации сильно зависят от вашего варианта использования, но есть универсальные методы, которые хорошо работают, когда речь идет об улучшении ответов ChatGPT.
Вы можете уменьшить галлюцинации ChatGPT, используя более низкую температуру, ограниченный охват, особый стиль ответа и ограниченную длину ответа. Вы можете еще больше улучшить результаты, помещая важный контекст на первое место. , запрещая определенные действия, включая пример ответа и угрожая модели негативными последствиями.
Введение
Наиболее очевидным недостатком сегодняшних LLM являются частые галлюцинации — случаи, когда модель «выдумывает», особенно с научными данными и историческими событиями. Они не только вызывают галлюцинации — они усиливают галлюцинации по мере того, как генерируется больше текста.
Хотя простого способа смягчить галлюцинации не существует, есть несколько эффективных методов улучшения поведения ChatGPT.
II. Почему у LLM бывают галлюцинации
В 2023 году большинство больших языковых моделей (LLM), включая ChatGPT, используют архитектуру Transformer, которая отлично подходит для создания текста, похожего на человеческий. Однако эти модели не понимают слова так, как люди. Вместо этого они статистически оценивают наиболее вероятное следующее слово, что иногда может приводить к «галлюцинациям» или фактам, содержащим неверный или бессмысленный текст.
Причины этих галлюцинаций различны, включая ошибки декодирования, пробелы в обучающих данных, двусмысленный контекст, а также исторические и жестко запрограммированные предубеждения.
III. Методы подсказки
Подсказки с несколькими выстрелами
Генерация с несколькими выстрелами в ChatGPT – это подход, при котором модель заполняется несколькими примерами для изучения конкретной задачи, прежде чем генерировать новый ответ.
Несмотря на неполучение явных инструкций, модель использует эти примеры для понимания контекста и создания соответствующих ответов. Исследования показывают, что короткие подсказки эффективно управляют моделью, обеспечивая высококачественные ответы, соответствующие поставленной задаче.
Этот подход использует обширную предварительную подготовку модели на разнообразных данных, что позволяет ей обобщать несколько примеров и выполнять широкий спектр задач точно и творчески.
Сортировка по важности
Эмпирические данные, а также недавняя статья Lost in the Middle: How Language Models Use Long Contexts показывают, чторазмещение соответствующей информации в подсказке существенно влияет на производительность языковых моделей.
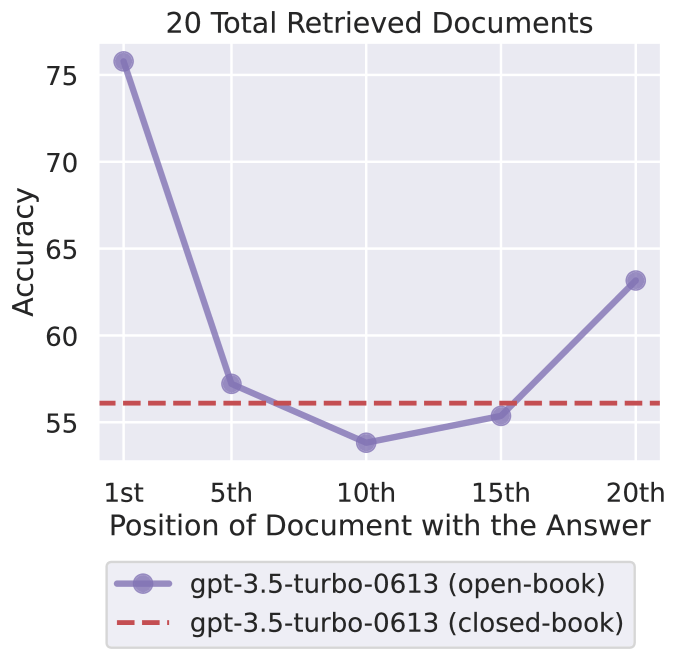
Оптимальные результаты достигаются, когда важные данные расположены в начале или в конце длинного контекста. Модели, как правило, с трудом извлекают релевантные данные из середины расширенных входных данных. Это снижение производительности заметно даже в моделях, специально разработанных для сценариев с длинным контекстом.
Ограничение длины
Установив мягкое ограничение на длину ответа, например, два абзаца или пять предложений, мы можем повысить качество выходных данных моделей больших языков, таких как ChatGPT.
Эта стратегия побуждает модель расставлять приоритеты в жизненно важных мыслях и выражать их более связно. Следовательно, он сокращает второстепенный или бессмысленный контент, улучшая общее качество и релевантность текста.
Механизм отрицательной обратной связи
В Thorium Labs мы сочли очень эффективным включение механизмов отрицательной обратной связи при запросе действий от ChatGPT. Связывая серьезные последствия с действиями, отклоняющимися от предписанных инструкций, мы можем значительно уменьшить количество галлюцинаций в выходных данных модели.
Например, прививая негативную коннотацию, связанную с созданием адресов электронной почты и номеров телефонов, мы смогли уменьшить связанные с этим галлюцинации на впечатляющие 85–90%.
Установив причинно-следственное правило, например, «если вы выполните это действие, последует нежелательный результат», мы обнаружили, что выходные данные модели более точно согласуются с заданными инструкциями.
IV. Технические методы
Если вы используете API OpenAI, у вас есть больший набор инструментов для уменьшения галлюцинаций. Настройка нескольких параметров в настройках может помочь получить лучшие ответы.
Снижение температуры
Эффективной стратегией продвижения более фактического и точного вывода LLM, таких как ChatGPT, является снижение температуры модели для завершения чата. Параметр температуры определяет случайность выходных данных модели. Более низкое значение температуры делает выходные данные более сфокусированными и детерминированными, тем самым повышая вероятность создания фактического и последовательного текста.
Тонкая настройка модели
OpenAI предоставляет возможность тонкой настройки своих моделей через свой API. Хотя включение в модель большего количества фактических данных может быть не самой эффективной стратегией, с ее помощью можно ограничить определенное нежелательное поведение. Это достигается за счет переобучения модели для противодействия такому поведению или подталкивания ее к определенным типам ответов.
Путем тонкой настройки можно адаптировать ответы ChatGPT, чтобы они более точно соответствовали конкретным требованиям, повышая его полезность и уместность в различных контекстах.
Выборка Top-P
Другой заслуживающий внимания метод управления выводом больших языковых моделей (LLM), таких как ChatGPT, — выборка Top-P, также известная как выборка ядра. В отличие от регулирования температуры, которое модулирует случайность модели, выборка Top-p фокусируется на управлении широтой распределения вероятностей, из которого выбирается следующее слово. В выборке Top-p модель рассматривает только наименьший набор наиболее вероятных следующих слов, которые вместе имеют совокупную вероятность, превышающую заданный порог (p).
Что делает этот подход таким мощным, так это его динамичный характер. В зависимости от контекста размер пула выбора может резко меняться. В контекстах, где весьма вероятно следующее конкретное слово, пул сужается, повышая внимание модели и снижая вероятность галлюцинаций. И наоборот, в более неоднозначных контекстах пул расширяется, предоставляя большую творческую свободу. Таким образом, правильная калибровка значения "p" может помочь сбалансировать потребность в фактической точности и творческой гибкости, позволяя LLM генерировать текст более высокого качества, соответствующий контексту.
V. Архитектурные методы
Хотя быстрые инженерные и технические корректировки могут эффективно смягчить галлюцинации в больших языковых моделях (LLM), наиболее надежный подход к подавлению нежелательных результатов — создание более надежной архитектуры.
В этом разделе мы представляем три образца архитектур, которые можно легко интегрировать, предлагая прочную основу для улучшения поведения модели.
Базы знаний
Ответы LLM можно улучшить, интегрировав внешние базы знаний через векторные базы данных и поиск по сходству в соответствующих частях текста.
Основным методом для этого является Расширенная генерация извлечения (RAG), которая включает в модель доверенный контекст.
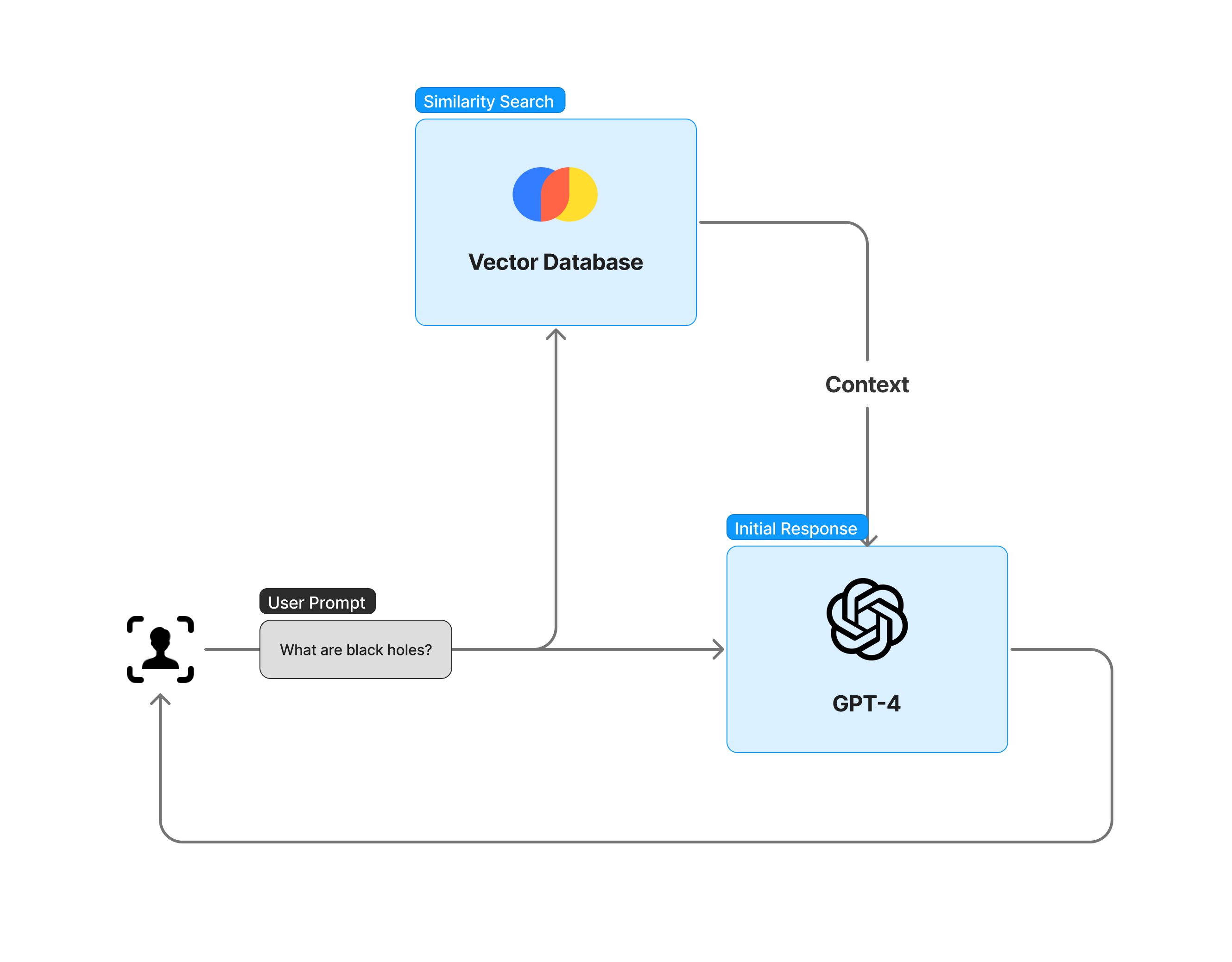
Интеграция пользовательского ввода, полученного сегмента информации из базы знаний и системных директив облегчает создание более точных и контекстуально точных ответов.
Оценка ответа
Эффективным методом минимизации галлюцинаций в моделях большого языка (LLM) является оценка реакции. Этот процесс включает отбрасывание сгенерированных ответов, которые не соответствуют установленным критериям. Адекватное выполнение этой стратегии может быть облегчено, используя функцию вызова функции API OpenAI.

Исходный ответ в сочетании с этими стандартами ответов возвращается в модель путем вызова функции оценки. Если сгенерированный результат не соответствует указанным критериям, он впоследствии отбрасывается. Этот итеративный процесс значительно повышает актуальность и точность выходных данных модели.
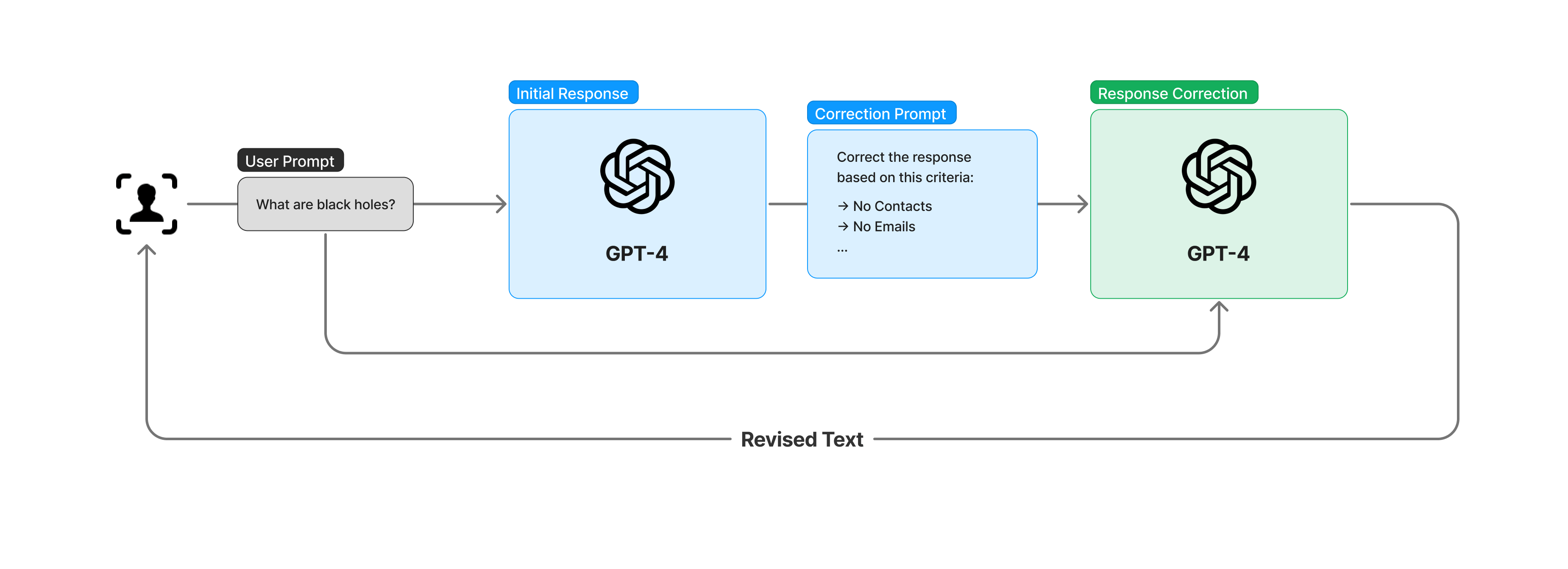
Исправление ответа
Архитектура коррекции отклика — это итеративный подход, улучшающий конечные результаты. Подобно оценке ответов, этот метод использует функцию вызова функций OpenAI API, но вместо того, чтобы отбрасывать неподходящие ответы, он уточняет их.
Дополнительный вызов API гарантирует, что первоначальный ответ будет оценен и, если окажется недостаточным, соответствующим образом изменен. Этот повторяющийся процесс уточнения обеспечивает предоставление точных и контекстуально релевантных выходных данных.
Заключение
В заключение можно сказать, что использование таких стратегий, как стратегическое оперативное проектирование, наряду с техническими и архитектурными улучшениями, может значительно смягчить галлюцинации в ChatGPT.
Мы должны подчеркнуть, что использование API OpenAI, а не пользовательского интерфейса ChatGPT, дает больше возможностей для настройки. Следовательно, сочетание этих методов, адаптированных к контексту, может максимизировать производительность модели, обеспечивая согласованные и надежные результаты.
👋 Хотите узнать, как ваш бизнес может расти с помощью генеративного ИИ? Закажите бесплатную консультацию на сайте thoriumlabs.ai, чтобы узнать, как ваша компания может использовать машинное обучение быстрее и эффективнее, чем ваши конкуренты.