Практическое руководство по использованию гиперинфекции с нарезкой для анализа спутниковых изображений

Здесь, в ML6, нас иногда спрашивают, как обнаружить очень маленькие объекты с высоким разрешением, то есть очень большие изображения. Хороший пример - поиск объектов на аэрофотоснимках. Цель этого сообщения в блоге - продемонстрировать практический подход к этой проблеме с использованием Slicing Aided Hyper Inference (SAHI).
Мы рассмотрим набор данных DOTA (v1.0), который содержит аэрофотоснимки с размерами от 800x800 до 20,000x20,000 пикселей. Данные обучения содержат около 1400 изображений. Ниже вы можете увидеть несколько примеров.
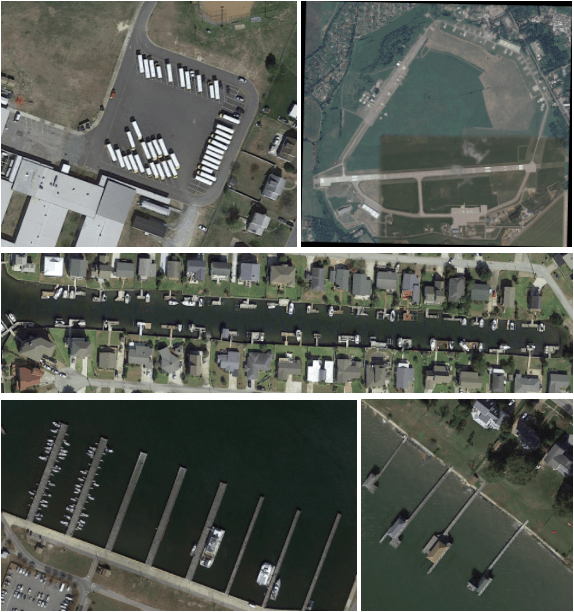
Набор данных содержит аннотации ограничивающих рамок для следующих 15 классов:
Точная настройка предварительно обученного детектора для такой проблемы, например Использование фреймворка mmdetection обычно довольно сложно по двум основным причинам:
- Модели в основном предварительно обучены на средних и крупных объектах
(например, на наборе данных COCO) - Обычно входное изображение масштабируется до довольно небольшого размера, например. (1333, 800), поэтому теряется много информации. В худшем случае мелкие объекты больше не видны на субдискретизированных изображениях, и у модели вообще нет шансов их обнаружить.

Тем не менее, мы рассмотрим способ использования фреймворка mmdetection для точной настройки Faster R-CNN в наборе данных DOTA. Для этого мы должны сначала переформатировать файл аннотации, чтобы он соответствовал стандартам COCO. Затем мы можем выбрать модель из модельного зоопарка и загрузить соответствующую модель и файл конфигурации. Не забудьте также загрузить соответствующие базовые конфигурации, используемые в файле конфигурации, если вы попытаетесь следовать инструкциям. Наконец, измените конфигурации в соответствии с вашими потребностями, особенно расположение каталогов данных и классов.
Чтобы избежать потери мелких объектов из-за изменения размера изображения в конвейере предварительной обработки обучающей модели, мы добавили случайную обрезку в начале конвейера. Фактически, затем мы обучаемся на небольших участках исходных изображений и сохраняем всю информацию в этих участках.
Альтернативой является создание производного набора данных, предварительно нарезав все изображения.
Мы также добавили в конфигурацию ловушку журналирования тензорной доски для визуализации прогресса обучения.
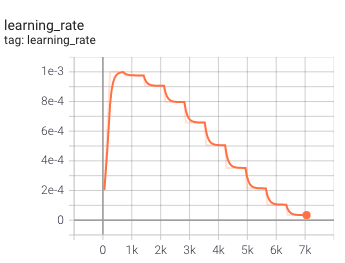
После настройки оптимизатора в файле конфигурации вы можете запустить обучающий сценарий, предоставленный mmdetection. Вот как выглядит тренировочный прогресс для нашего 10-ти эпохального забега:
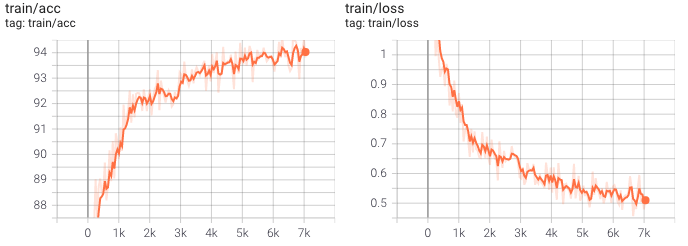
Это уже выглядит неплохо. Теперь мы можем использовать сохраненную модель для вывода.
Однако проблема того, как выполнить вывод для крупномасштабных входных изображений, остается. Мы решили эту проблему на тренировках, тренируясь только на случайных культурах. Но очевидно, что это не жизнеспособный подход для вывода. Именно здесь вступает в игру гиперинфекция с нарезкой (Slicing-Aided Hyper Inference, SAHI). Срезанные прогнозы SAHI разбивают входное изображение на слегка перекрывающиеся фрагменты, выполняют прогноз для каждого фрагмента и, наконец, объединяют аннотации для каждого фрагмента, чтобы визуализировать их на исходном изображении.
Пример кода ниже показывает, насколько легко использовать SAHI для вывода.
И вот как выглядят результаты по сравнению с простым разрешением модели изменить размер входных данных. Вы должны увеличить изображения, чтобы увидеть ограничивающие рамки и метки, предсказанные моделью. Интересно, что прогнозы на обоих изображениях сделаны одной и той же моделью, но результаты сильно различаются.
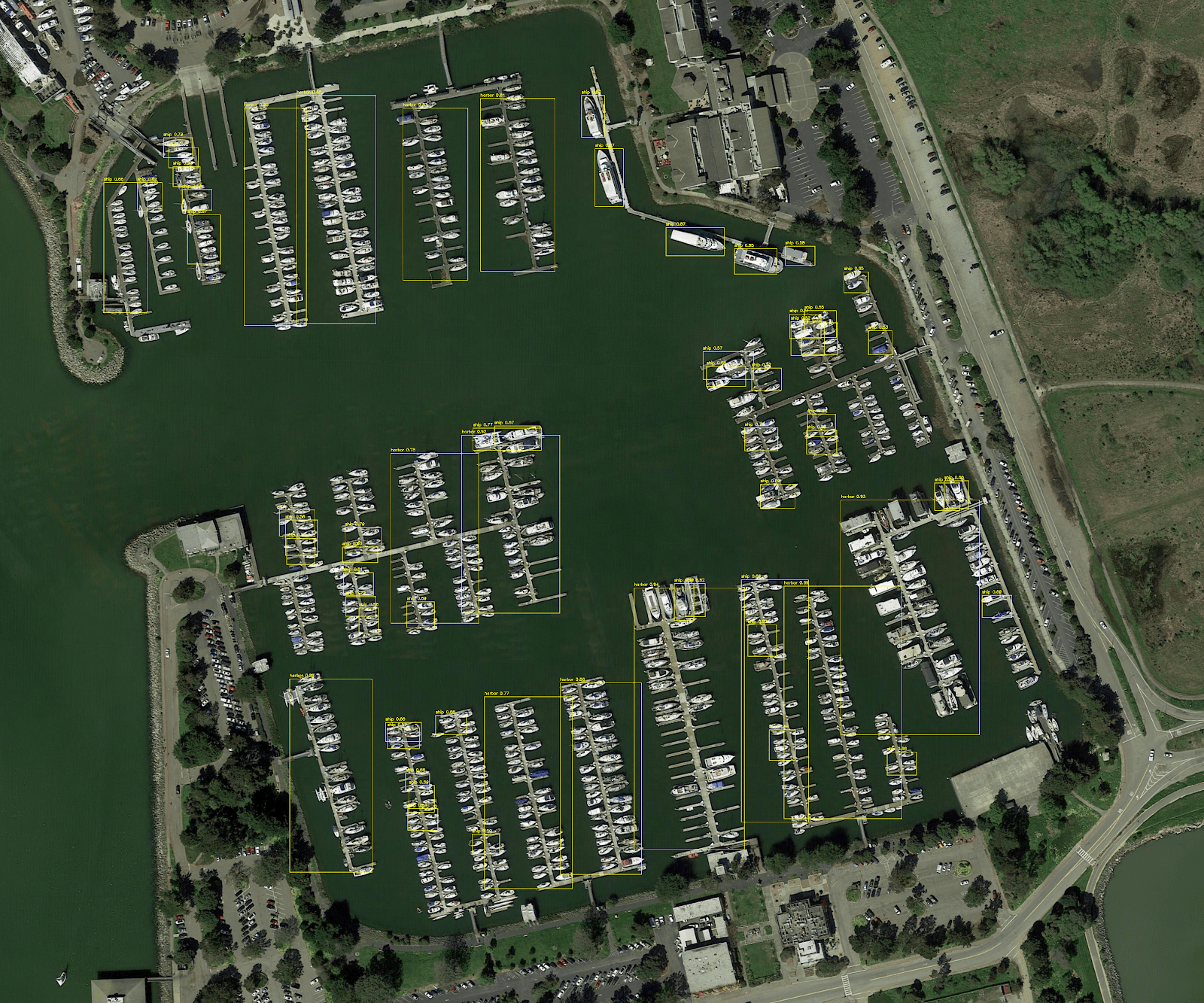
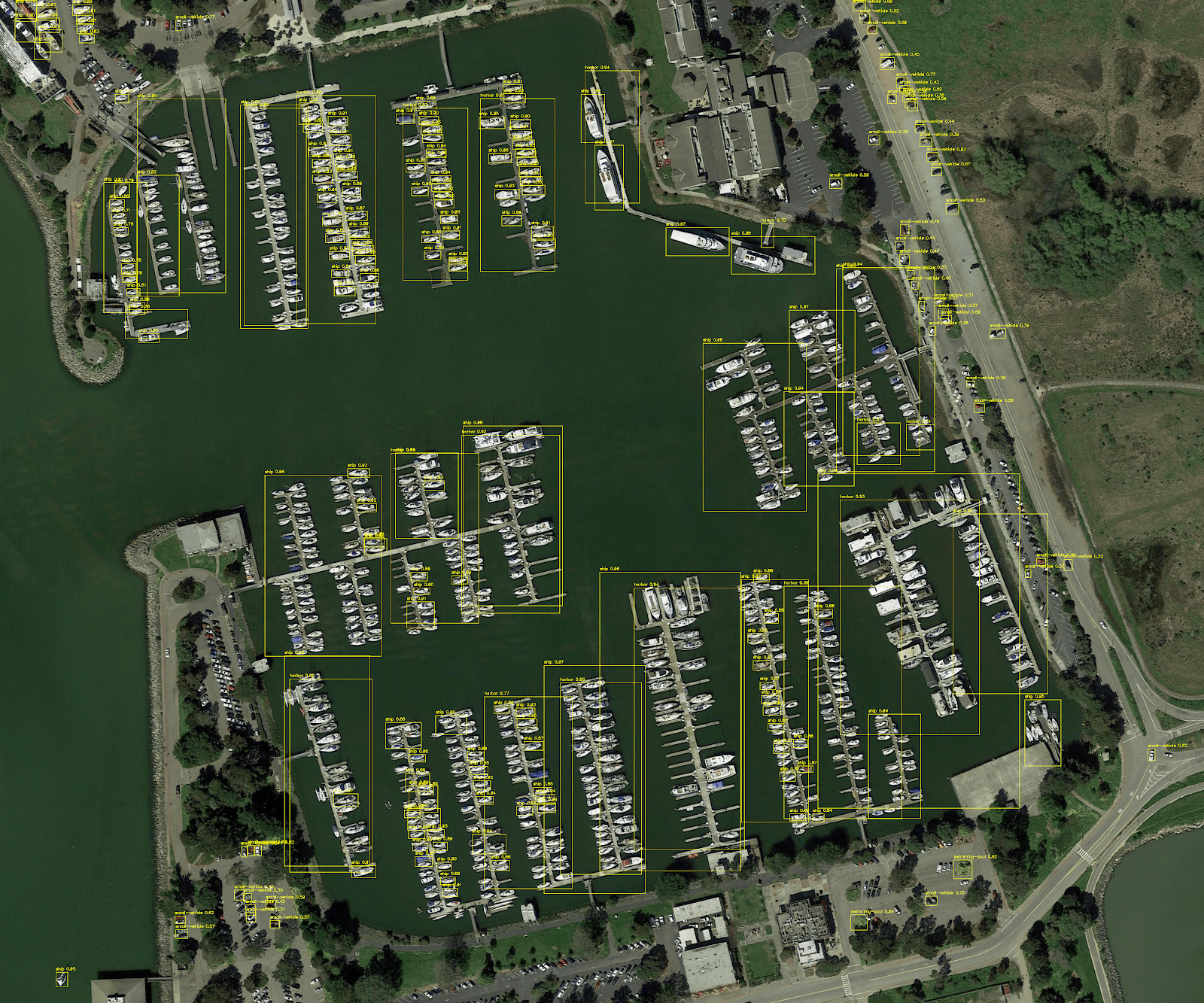





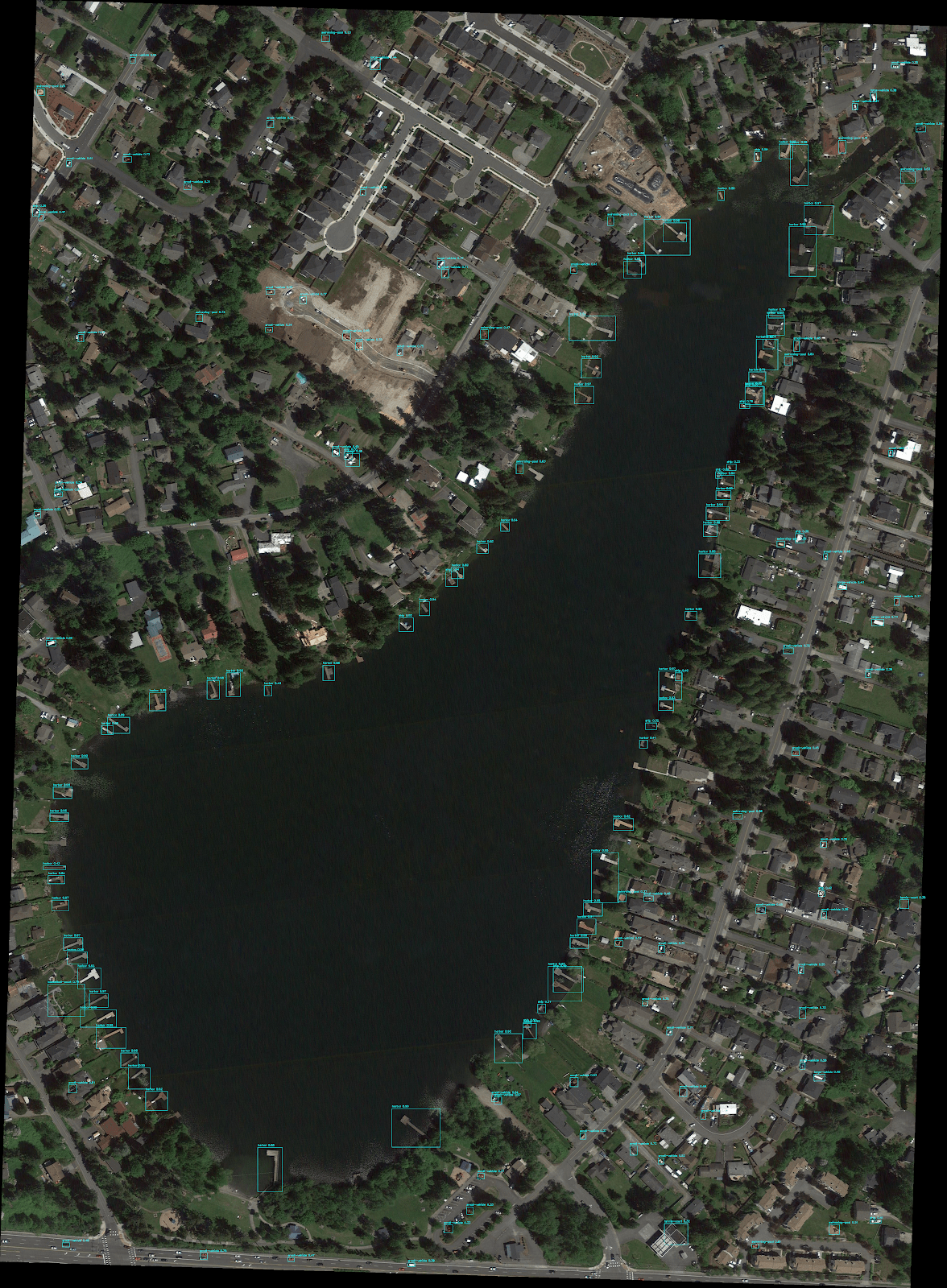
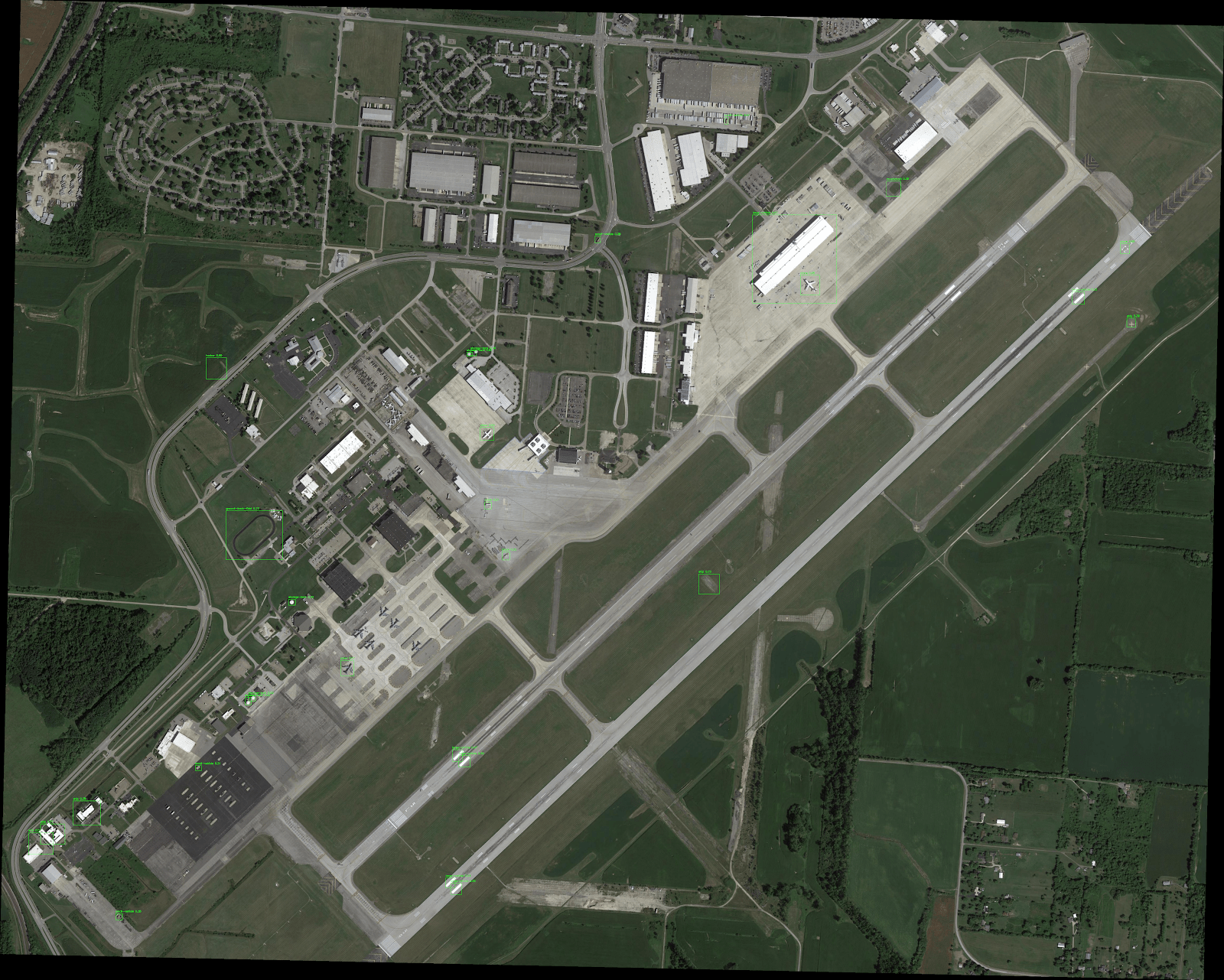


Наконец, в настоящее время SAHI работает "из коробки" с любой моделью mmdetection. Используя более мощную модель, такую как Cascade R-CNN, с некоторыми дополнительными усилиями, вложенными в обучение и настройку гиперпараметров, этот подход имеет большой потенциал для получения высококачественных результатов обнаружения небольших объектов на изображениях с высоким разрешением. Однако цель этого сообщения в блоге заключалась в том, чтобы просто показать, как можно эффективно решить эту проблему с помощью логического вывода на основе фрагментов.