
Временные сверточные сети
Могут ли CNN обрабатывать последовательные данные и поддерживать более эффективную историю, чем LSTM?
В этой статье рассматривается работа Шаоджи Бая, Дж. Зико Колтера и Владлена Колтуна под названием Эмпирическая оценка общих сверточных и рекуррентных сетей для последовательного моделирования.
До появления TCN мы часто связывали RNN, такие как LSTM и GRU, для новой задачи моделирования последовательности. Однако в документе показано, что TCN (временные сверточные сети) могут эффективно обрабатывать задачи моделирования последовательности и даже превосходить другие модели. Авторы также продемонстрировали, что TCN поддерживают более расширенную память, чем LSTM.
Мы обсуждаем архитектуру TCN со следующими темами:
- Последовательное моделирование
- Причинные свертки
- Расширенные свертки
- Остаточные соединения
- Преимущества и недостатки
- Сравнение производительности
Последовательное моделирование
Хотя в данной статье термин TCN используется не впервые, он означает семейство архитектур, использующих свертки для обработки последовательных данных.
Итак, давайте определимся с задачами моделирования последовательности.
Учитывая входную последовательность:

, мы хотим каждый раз прогнозировать соответствующие выходы:

Итак, сеть моделирования последовательности в статье - это функция f, которая отображает вектор элементов T + 1 на другой вектор T + 1 элементы:

Существует ограничение (причинное ограничение): при прогнозировании выходных данных для времени t ‹= T мы можем использовать только входные данные из той же временной точки и более ранних временных точек, например:

И мы не должны использовать входные данные из более поздних временных точек, чем t:
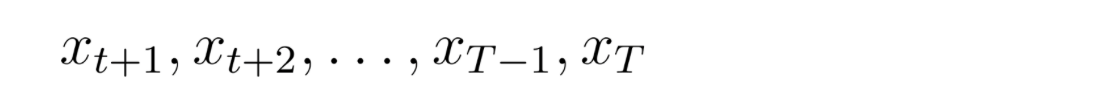
Задача вышеуказанной настройки моделирования последовательности - найти сеть f, которая минимизирует потери между выходными данными меток и прогнозами:
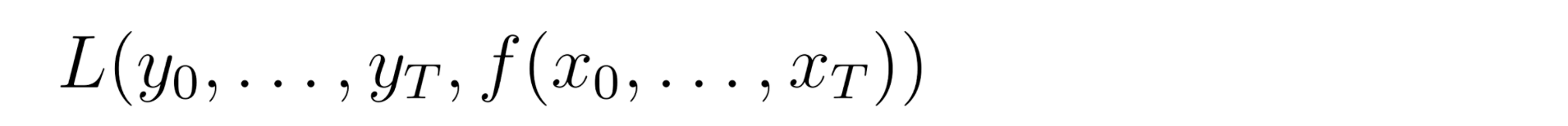
Эта настройка более ограничена, чем общие модели от последовательности к последовательности, такие как машинный перевод, который может использовать всю последовательность для выполнения прогнозов.
Таким образом, TCN является причинным (отсутствие утечки информации из будущего в прошлое) и может отображать любую последовательность в выходную последовательность такой же длины.
Более того, он может использовать очень глубокую сеть с помощью остаточных связей и может заглядывать в очень далекое прошлое, чтобы делать прогнозы с помощью расширенных сверток.
Мы обсудим вышеупомянутые характеристики (случайные, расширенные и остаточные) по очереди.
Причинные свертки
TCN использует архитектуру 1D FCN (одномерная полностью сверточная сеть).
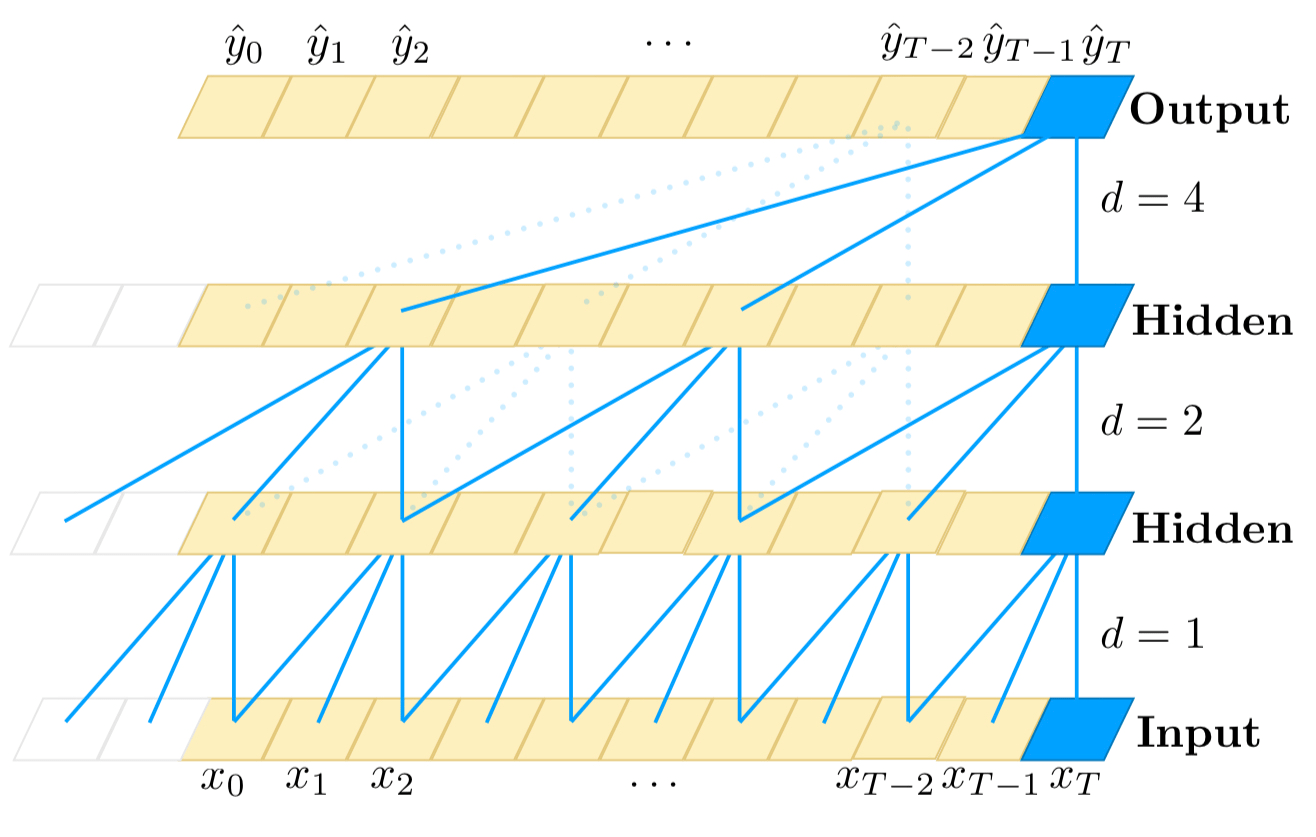
Каждый скрытый слой имеет ту же длину, что и входной, с нулевыми отступами, чтобы гарантировать, что следующий слой имеет такую же длину.
Для вывода во время t причинная свертка (свертка с причинным ограничением) использует входные данные от времени t и ранее на предыдущем уровне (см. Соединения синей линии на внизу диаграммы выше).
Причинная свертка - не новая идея, но в статье используются очень глубокие сети, позволяющие иметь долгую эффективную историю.
Расширенные свертки
Если мы посмотрим назад на последовательные временные шаги, мы сможем вернуться только к количеству слоев в сети.
Чтобы решить эту проблему, они адаптировали расширенные свертки, которые принимают входные данные через каждые d шагов от t:
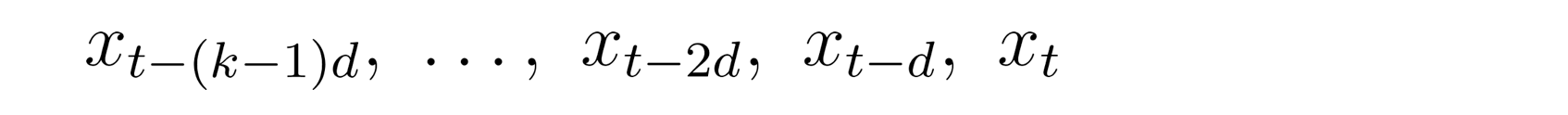
где k - размер ядра.
Идея причинной свертки и расширенной свертки возникла в статье WaveNet, архитектура которой очень похожа на TCN.
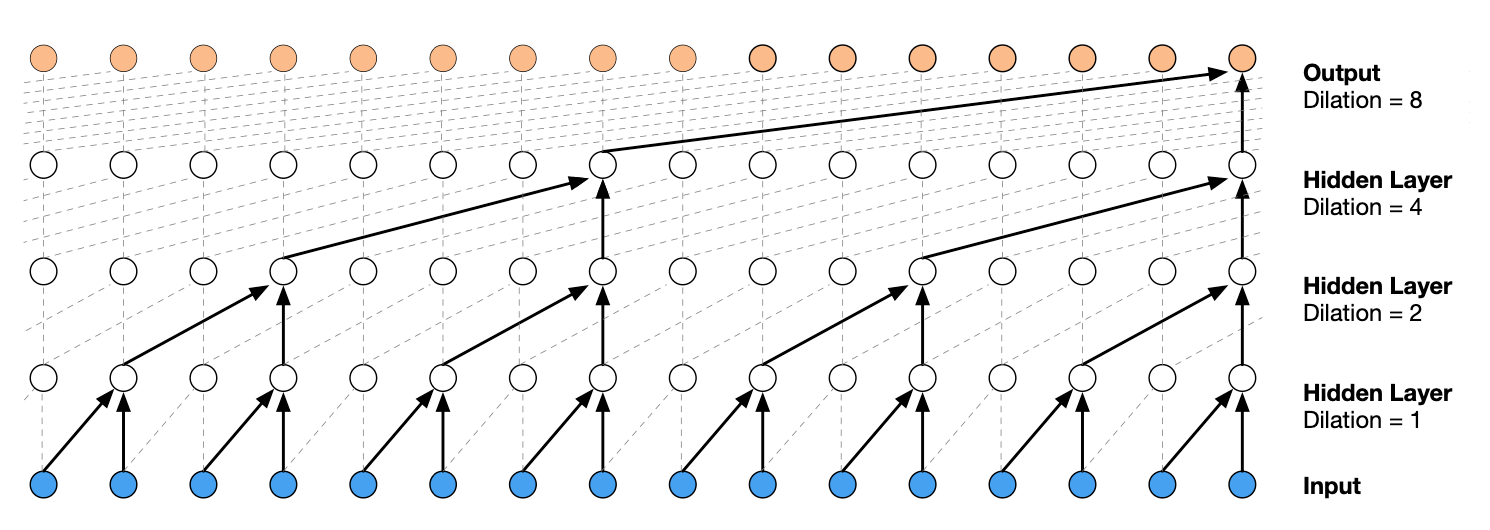
Расширенная свертка позволяет сети искать до (k-1) d временных шагов, обеспечивая экспоненциально большие принимающие поля на количество слоев.
Авторы статьи TCN увеличили d экспоненциально с увеличением глубины сети:

где i означает уровень i сети (i начинается с 0).
Ниже для удобства представлена такая же диаграмма. Расширенная свертка на первом скрытом слое применяется каждые два шага, где i = 1.
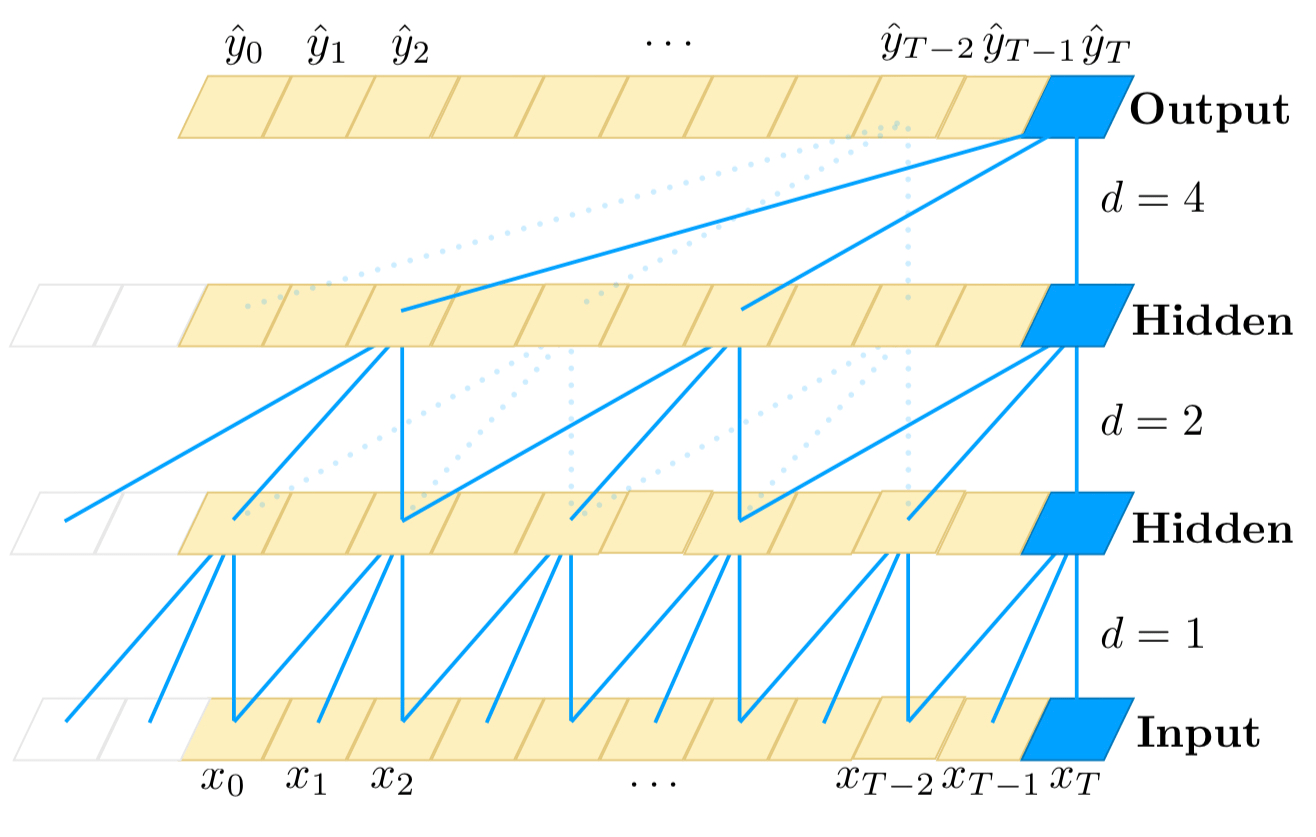
Расположение расширенных сверток гарантирует, что какой-то фильтр попадает на каждый вход в пределах эффективной истории, а также позволяет вести долгую эффективную историю с использованием глубоких сетей.
Вы можете проследить синие линии от верхнего к нижнему слоям, чтобы увидеть, что они достигают всех входов внизу, что означает, что прогноз вывода (для времени T в качестве примера) использует все входы в пределах действующей истории.
Остаточные соединения
Остаточный блок (первоначально из ResNet) позволяет каждому слою изучать модификации отображения идентичности и хорошо работает с очень глубокими сетями.
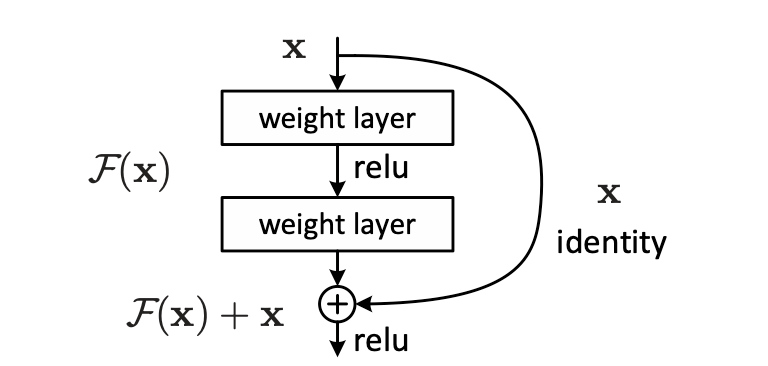
Рисунок 2 из ResNet paper
Остаточная связь важна для обеспечения долгой эффективной истории. Например, если прогноз зависит от длины истории, равной 2 в степени 12, нам нужно 12 уровней для обработки такого большого воспринимающего поля.
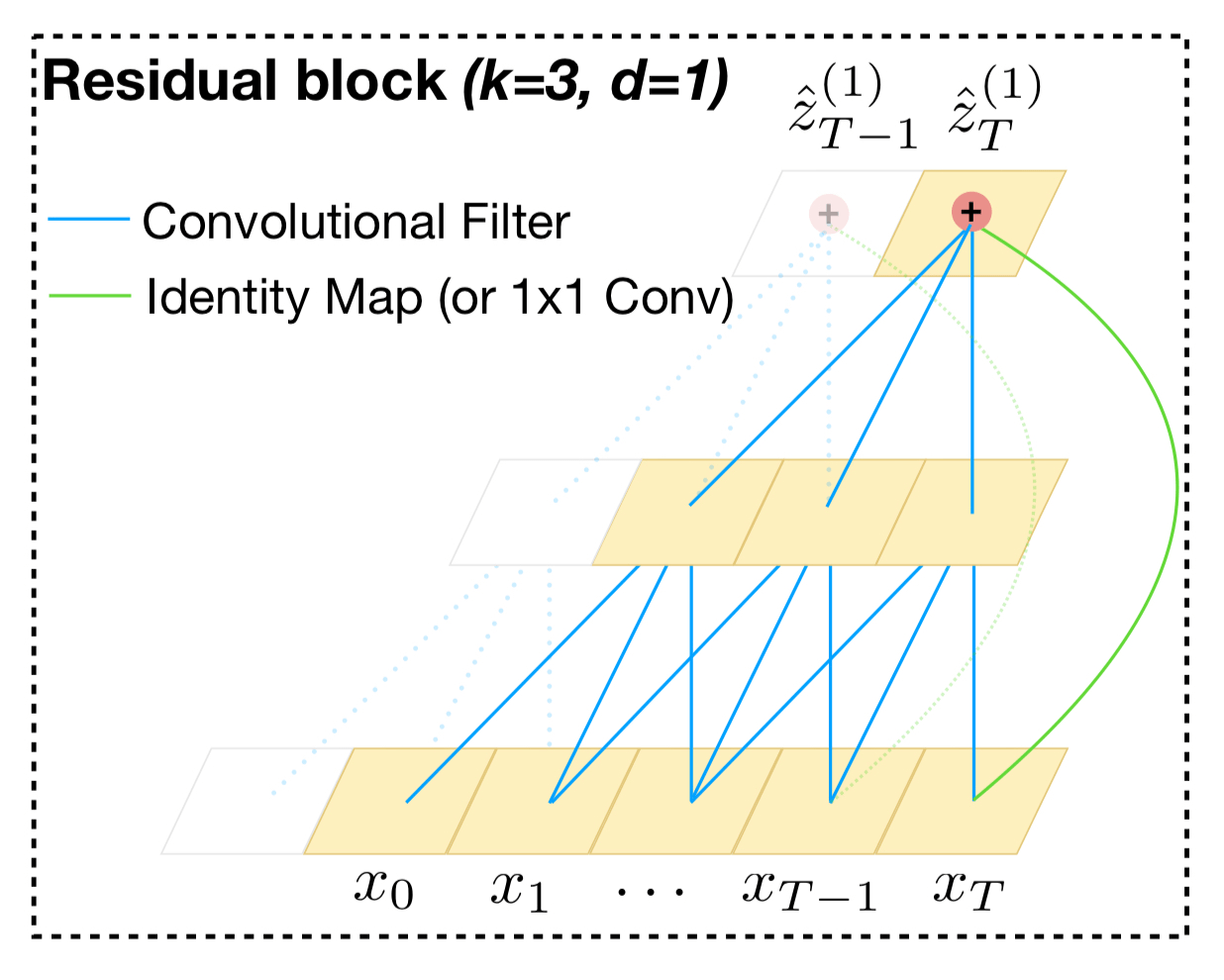
Ниже приведен остаточный блок базового TCN.
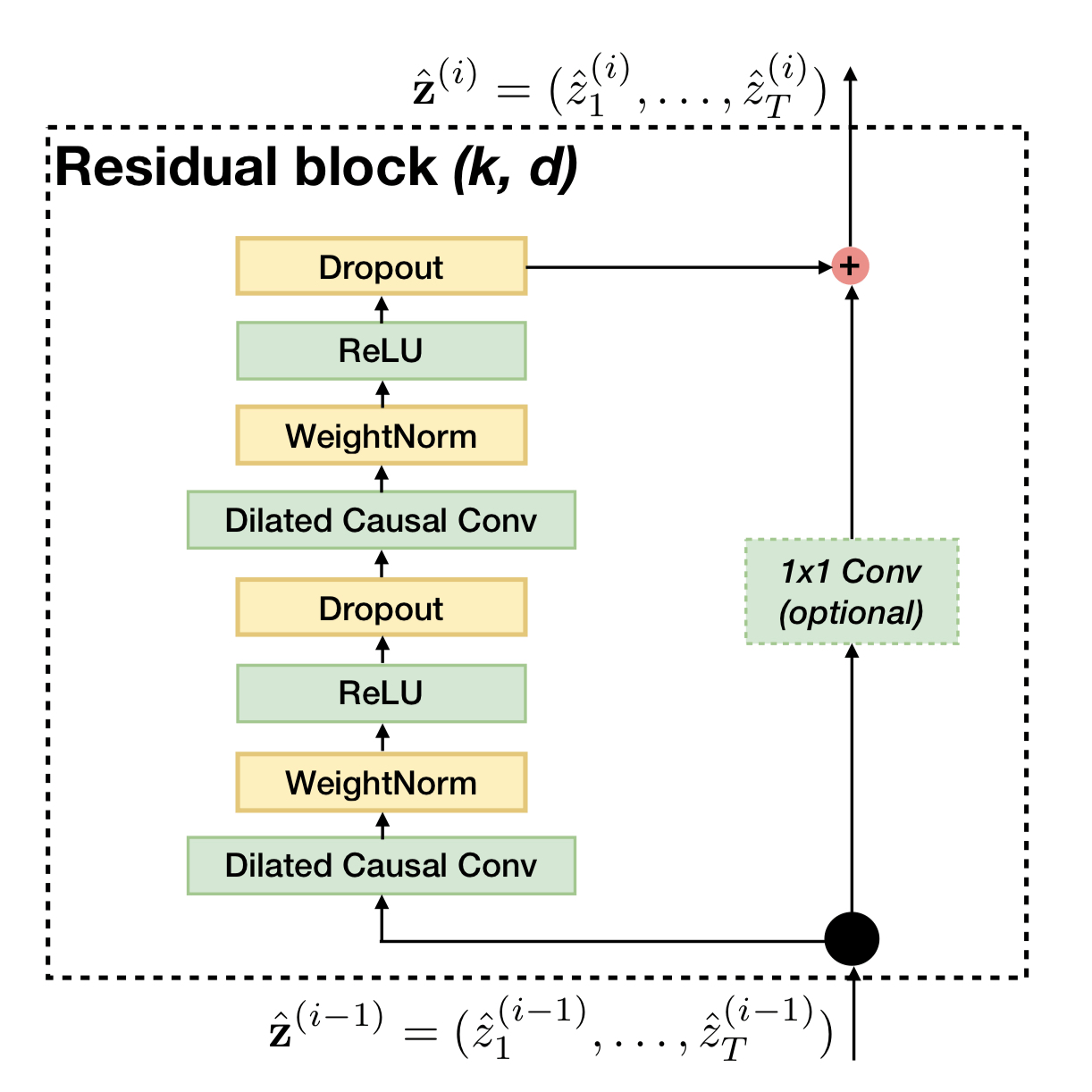
Остаточный блок имеет два уровня расширенной причинной свертки, нормализации веса, активации ReLU и выпадения.
Существует необязательная свертка 1x1, если количество входных каналов отличается от количества выходных каналов из расширенной причинной свертки (количества фильтров второй расширенной свертки).
Он предназначен для обеспечения работы остаточного соединения (поэлементного сложения вывода и ввода свертки).
Преимущества и недостатки
В итоге,
TCN = 1D FCN + Расширенные причинные свертки
, который представляет собой очень простую и понятную структуру по сравнению с другими моделями последовательностей, такими как LSTM.
Помимо простоты, существуют следующие преимущества использования TCN по сравнению с RNN (LSTM и GRU):
- В отличие от RNN, TCN могут использовать преимущества параллелизма, поскольку они могут выполнять свертки параллельно.
- Мы можем регулировать размеры воспринимающего поля по количеству слоев, факторам расширения и размерам фильтров, что позволяет нам контролировать размер памяти модели для различных требований домена.
- В отличие от RNN, градиенты не во временном направлении, а в направлении глубины сети, что имеет большое значение, особенно когда длина ввода очень велика. Таким образом, градиенты в TCN более стабильны (также благодаря остаточным связям).
- Требования к памяти ниже, чем у LSTM и GRU, потому что на каждом уровне есть только одно ядро. Другими словами, общее количество ядер зависит от количества слоев (а не от входной длины).
Есть два заметных недостатка:
- Во время оценки TCN принимают необработанную последовательность до требуемой длины истории, тогда как RNN могут отбрасывать фрагмент фиксированной длины (часть входных данных) по мере их потребления и сохранять только сводку в форме скрытого состояния. Следовательно, во время оценки для TCN может потребоваться больше памяти, чем для RNN.
- Перенос домена может не работать с TCN, особенно при перемещении из домена, требующего короткой истории, в другой домен, требующий долгой истории.
Сравнение производительности
Авторы сравнили производительность LSTM, GRU, RNN и TCN, используя различные задачи моделирования последовательности:
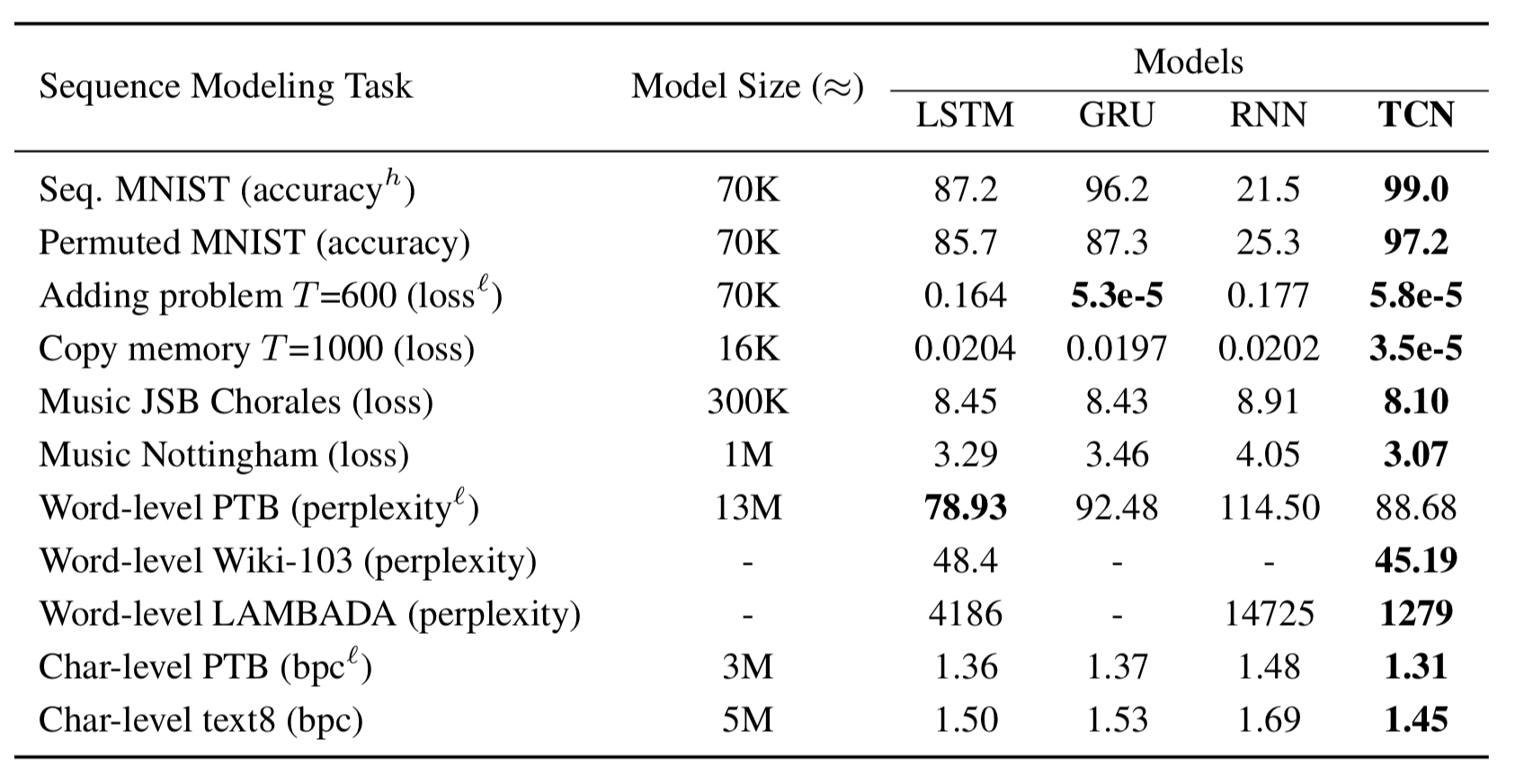
Как видите, TCN лучше других моделей выполняет большинство задач.
Одним из интересных экспериментов является задача копирования памяти, которая исследует способность модели сохранять информацию в течение разного периода времени.
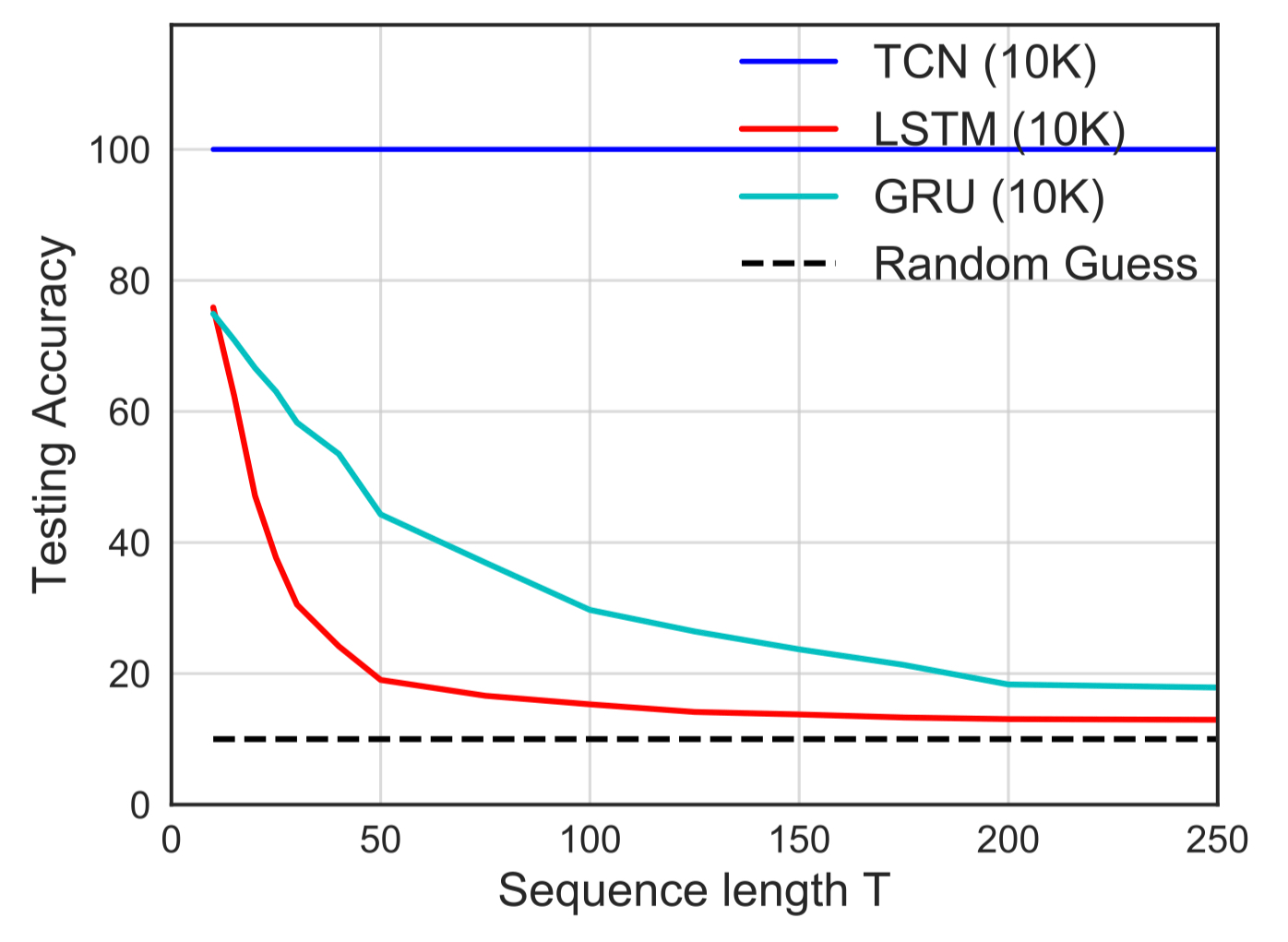
TCN достиг 100% точности в задаче копирования памяти, тогда как LSTM и GRU вырождаются к случайному угадыванию по мере того, как время T увеличивается. Это может быть очевидно, учитывая сетевую структуру TCN, которая имеет прямую сверточную архитектуру.
В целом, TCN очень хорошо работают по сравнению с LSTM. Об уверенности авторов свидетельствует следующая цитата из статьи:
Превосходство повторяющихся сетей в моделировании последовательностей может быть в значительной степени наследием истории. До недавнего времени, до появления архитектурных элементов, таких как расширенные свертки и остаточные соединения, сверточные архитектуры действительно были слабее. Наши результаты показывают, что с этими элементами простая сверточная архитектура более эффективна для решения разнообразных задач моделирования последовательности, чем повторяющиеся архитектуры, такие как LSTM. Из-за сопоставимой ясности и простоты TCN мы пришли к выводу, что сверточные сети следует рассматривать как естественную отправную точку и мощный инструментарий для моделирования последовательности.
Они предоставили исходный код в своем репозитории на GitHub, так что вы можете попробовать и убедиться в этом сами.
Использованная литература:
Эмпирическая оценка общих сверточных и рекуррентных сетей для моделирования последовательностей
Шаоцзе Бай, Дж. Зико Колтер, Владлен Колтун
WaveNet: Генеративная модель для Raw Audio
Аарон ван ден Оорд, Сандер Дилеман, Хейга Зен, Карен Симонян, Ориол Виньялс, Алекс Грейвс, Нал Калчбреннер, Эндрю Старший, Корай Кавукчуоглу
Глубокое остаточное обучение для распознавания изображений
Каймин Хэ, Сянюй Чжан, Шаоцин Жэнь, Цзянь Сунь