Наука о данных
Интуиция для независимых и одинаково распределенных
Понимание ключевого допущения в статистике и его последствий
Основная цель науки о данных в целом и машинного обучения в частности - использовать прошлое для предсказания будущего. Помимо конкретных предположений различных статистических моделей, неизбежным является предположение о том, что будущее можно предсказать на основе прошлых событий.

Мы предполагаем, что существует некоторая функция, которую мы можем описать, которая принимает наши наблюдаемые данные и выводит вероятность какого-то будущего события - P (Y | X), вероятность Y. вывод с заданными входами X. Мы должны тщательно строить нашу модель, чтобы гарантировать, что информация, предоставленная X, является полезной и надежной для прогнозирования Y. Помимо ложной корреляции, мы выбираем функции, которые прямо или косвенно информируют Y.
Идентично распределены
Предположим, мы хотим предсказать шансы вытащить Пиковую даму из колоды карт при первом розыгрыше - очень окольным путем, путем моделирования ... математически это всего лишь 1/52 шанс, но подыгрывайте.
Каждое наблюдение или ряд будет одной попыткой, когда мы случайным образом вытащим карту из колоды. Мы сделаем это 10 000, 100 000 или миллион раз. При N → ∞ наша вероятность выпадения пиковой дамы при первом розыгрыше должна приближаться к 1/52!
Но это при условии, что все колоды одинаковые! Это наше одинаково распределенное предположение. Мы должны предположить, что в каждой колоде карт есть все 13 карт каждой масти от туза до короля. Что, если в каждой третьей колоде всего 50 карт? Или если в колоде отсутствуют все пики? Наша вероятность изменится непредсказуемо. А что, если после того, как мы скомпилировали все эти обучающие данные, мы обнаружим, что на самом деле предсказываем вероятность вытащить Пиковую даму из колоды euchre! Который идет только от 9 до туза (старшего), всего 25 карт! Мы хотим, чтобы наши данные для обучения и тестирования поступали из одного и того же распределения.
Независимый
Мы также предположили, что каждая колода и пул независимы от всех остальных. Например, если мы отбираем колоду без замены, это означает, что после того, как мы вытянули карту, которая не является Пиковой дамой, мы не кладем ее обратно в колоду, в конечном итоге нам придется вытягивать Пиковая дама! Наша вероятность будет обновляться после каждого розыгрыша, с 1/52… 1/51… 1/50 до 1/1 (если Пиковая дама является последней картой в колоде).
Независимость удовлетворяется, когда исход одного события не зависит от результата другого события. В этом примере результат второго розыгрыша зависит от первого, потому что в нашей колоде на одну карту меньше! Вот почему мы предполагаем независимость и, как правило, выборку с заменой.
Существует мера для количественной оценки разницы между выборкой с заменой и без нее, ковариация: совместная изменчивость двух случайных величин. В проектах машинного обучения ковариация - это определенно то, о чем вы должны знать и исследовать в своих данных. [1]
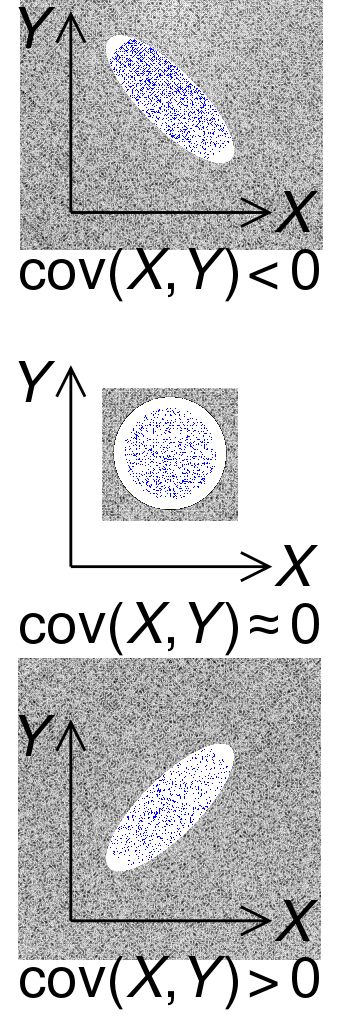
Если ковариация равна нулю, то две переменные независимы и не влияют друг на друга. Если переменные имеют тенденцию показывать аналогичное поведение, например, увеличение одной соответствует увеличению другой, они имеют положительную ковариацию. Нормализованная ковариация дает коэффициент корреляции, который определяет величину этой связи.
Подразумеваемое
Если предположить, что I.I.D. (независимый, одинаково распределенный) важен для использования нашей модели для прогнозирования, поскольку мы предполагаем, что прошлое - наши существующие данные X - будут представлять проблемное пространство и точно прогнозировать будущее Y .
Существуют также специальные методы, предполагающие наличие I.I.D., такие как модели агрегирования (загрузки) бутстрапа или перекрестная проверка. В частности, пакетирование, как и случайные леса, использует случайные подвыборки данных для создания множества различных моделей, которые затем объединяются или усредняются вместе для уменьшения дисперсии и переобучения. Если данные не I.I.D. тогда каждая подвыборка будет сильно различаться и не будет описывать основное распределение набора данных.
Алгоритм упаковки специально выполняет выборку с заменой, чтобы гарантировать независимость от новых обучающих наборов. Для моделей, которые легко переоснащаются, таких как нейронные сети и деревья решений, пакетирование - отличный инструмент для уменьшения дисперсии / повышения стабильности.
Как говорит Нейт Сильвер, «очень легко переобучить модель, думая, что вы уловили сигнал, когда вы просто описываете шум». [2]
Вы можете прочитать о Центральной предельной теореме здесь и Бэггинг здесь.
Соединять
Я всегда ищу возможности познакомиться и изучить другие проекты! Вы можете подписаться на меня на GitHub или LinkedIn, а другие мои истории - на Medium. Еще у меня есть Твиттер!
Источники
[1] Стефани Глен. Выборка с заменой / Выборка без замены от StatisticsHowTo.com: элементарная статистика для всех нас! Https://www.statisticshowto.com/sampling-with-replacement-without/
[2] Сильвер Н., Сигнал и шум: почему так много прогнозов не оправдываются, а некоторые - нет (2012).