В большинстве архитектур данных по-прежнему присутствует Hive Metastore. Почему он сохранился и что, наконец, может заменить его в будущем?

Hive & Hadoop - Краткая история
Apache Hive появился в 2010 году как компонент экосистемы Hadoop, когда Hadoop был новым и инновационным способом анализа больших данных.
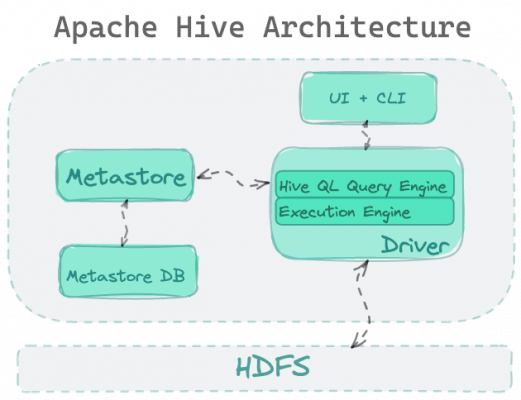
Что сделал Hive, так это реализовал интерфейс SQL для Hadoop. Его архитектура состояла из двух основных сервисов:
- Механизм запросов - отвечает за выполнение оператора SQL.
- Хранилище метаданных - отвечает за виртуализацию коллекций данных в HDFS в виде таблиц.
Концепция, лежащая в основе Hadoop, была революционной. Огромные наборы данных хранятся в распределенной файловой системе (HDFS), работающей на кластерах стандартного оборудования. Вычислительные задания выполняются параллельно с обработкой данных с помощью MapReduce. Распределением этих задач управляет Yarn. Основной интерфейс - это язык программирования, первоначально Java или Scala.
Все компоненты стали общедоступными в рамках Apache Foundation и стали бесплатными. В течение нескольких лет этот набор технологий был стандартом для крупномасштабной аналитики.
Однако по частям стек разбирали с помощью новых технологий…
HDFS уступила место хранилищам объектов во главе с S3. MapReduce был свергнут Spark, который со временем также уменьшил свою зависимость от Hadoop. Пряжа заменяется такой технологией, как Kubernetes. Компонент механизма запросов Hive превзошел по производительности и принятию Presto / Trino.
Несмотря на эту эволюцию, большинство организаций, использующих озера данных, все еще имеют активное развертывание Hive Metastore как часть своей архитектуры. По сравнению с аналогами Hadoop у вас может возникнуть вопрос: «Что делает Hive Metastore таким особенным?»
Чтобы ответить на этот вопрос, давайте подробнее рассмотрим, какие функции Hive Metastore предоставляет сегодня и какие технологии появились на его замену.
Что делает Hive Metastore
Когда новые данные сохраняются в хранилище объектов, мы регистрируем их в Hive Metastore, вызывая API хранилища метаданных из кода любого приложения для обработки данных или инструмента оркестровки. На этом декларативном этапе набор объектов в хранилище объектов сопоставляется с таблицей, предоставляемой Hive. Часть регистрации включает определение схемы таблицы, содержащейся в файле, с некоторыми метаданными, описывающими столбцы.
Использование Hive Metastore таким образом дает четыре основных преимущества, связанных с:
- Виртуализация
- Обнаруживаемость
- Развитие схемы
- Производительность
Обсудим это подробнее!
Виртуализация
Аналитики данных, использующие SQL, обычно не интересуются деталями хранилища объектов и схемами доступа к ним. Им просто хотелось бы иметь свои столики, пожалуйста!
Эта динамика является движущей силой, которая делает Hive Metastore незаменимым, в то время как другие компоненты Hadoop были заменены. Каждая новая технология, которая была представлена, обеспечивала поддержку Hive Metastore, чтобы избежать нарушения критически важных аналитических рабочих процессов, зависящих от объектов таблиц, определенных в Hive.
Обнаруживаемость
Hive Metastore естественным образом становится каталогом всех коллекций, хранящихся в хранилище объектов, когда открытие новых данных сопровождается их обновлением. При хорошем обслуживании это позволяет обнаруживать наборы данных, доступные для запроса.
Кроме того, в хранилище метаданных можно сохранить дополнительную информацию, чтобы предоставить полезную информацию о данных, например о частоте обновления, владельце и т. Д.
Схема эволюции
Одна из проблем управления наборами данных с течением времени - их изменчивость. Записи могут изменяться со временем по отношению к существующим столбцам, описывающим их атрибуты. Или сам набор атрибутов меняется со временем, в результате чего меняется схема таблицы.
Описанный выше процесс регистрации обеспечивает запись схемы для каждого дополнительного файла данных, принадлежащего таблице. Это означает, что если схема изменилась в какой-то момент времени, она будет записана в хранилище метаданных Hive. При доступе к данным к ним можно получить доступ с помощью соответствующей схемы.
Это также обеспечивает хорошую основу для проверки схемы, если она не должна была изменяться, и предупреждения об этом. Hive содержит информацию для создания такого теста.
Представление
Поскольку Hive Metastore сопоставляет таблицу с базовым объектом, он позволяет представлять разделы в соответствии с первичным ключом, поддерживаемым хранилищем объектов. Степень детализации разделов может быть установлена пользователем, и если разделы сбалансированы и их количество является разумным, это сопоставление позволяет улучшить производительность запросов.
Это часто называют сокращением раздела, которое позволяет механизму запросов определять файлы данных, которые можно пропустить.
Переживет ли улей следующую революцию?
Нет кандидатов на прямую замену хранилища метаданных, но он может устареть, если некоторые существующие тенденции закрепятся и будут хорошо сочетаться.
Давайте посмотрим на ведущих преемников.
Форматы открытых таблиц
Айсберг, Худи и Дельта Лейк - три игрока в этой категории. Каждый из них был создан для удовлетворения различных потребностей, но со временем все они сходятся, чтобы охватить набор функций, которые позволяют:
- Изменчивость (Hudi, Delta)
- Эффективность доступа к большим таблицам (Айсберг)
- Применение и развитие схемы (Delta).
При использовании приложений, поддерживающих эти форматы, данные могут обрабатываться приложением как таблица без каких-либо промежуточных звеньев. Не все приложения в экосистеме поддерживают эти форматы, и их использование в некоторых случаях снижает производительность.
Поскольку Hive Metastore - это общий интерфейс, поддерживаемый всеми приложениями, организации, использующие формат открытой таблицы, по-прежнему полагаются на Hive для виртуализации и / или для других случаев использования, не охватываемых форматами.
Каталоги данных
За последний год с лишним мы стали свидетелями блиц из более чем 10 инструментов обнаружения с открытым исходным кодом, выпущенных лидерами в области инженерии данных, что указывает на необходимость в каталоге данных на уровне организации. Эти новички присоединяются к другим существующим коммерческим каталогам данных, таким как Allation.
Каталоги поддерживают отображение хранилища объектов вместе с большинством используемых сегодня баз данных. Многие инструменты обнаружения по возможности используют данные, уже находящиеся в Hive Metastore, в противном случае - в хранилище объектов. Неудивительно, что эти инструменты являются хорошими кандидатами на замену функции каталогизации Hive Metastore со временем.
Инструменты наблюдения
Основная цель инструментов наблюдения - оперативный мониторинг качества конвейеров данных и самих данных. Некоторые инструменты ориентированы на первое (например, Databand), а другие - на второе (Большие надежды или Монте-Карло. ). Если инструмент наблюдения реализуется на протяжении всего жизненного цикла данных, он может динамически обновлять каталог данных и заменять Hive Metastore в качестве каталога.
Последние мысли
Ряд технологий начал сокращаться для улучшения функциональности Hive. Но ни один из них еще не стал достаточно зрелым, и не было достигнуто консенсуса по поводу комбинации, которая позволила бы успешно удалить Hive Metastore с изображения.
Это не означает, что он должен или останется частью архитектур данных. Фактически, он страдает очевидными недостатками как в удобстве использования, так и в производительности. В частности, Hive Metastore:
- Сложен в установке и обслуживании.
- Без облачной архитектуры, что усложняет реализацию управляемых услуг.
- Имеет ограничения масштабируемости из-за зависимости от реляционной БД.
Все эти факторы в совокупности позволяют нам предсказать, что Hive Metastore не переживет следующую эволюцию архитектур данных. Это не произойдет автоматически - для этого требуется импульс, который нужно создать внутри сообщества. Мы надеемся, что вы сотрудничаете с нами во имя лучшего будущего!
Этот пост был впервые опубликован 9.09.21 Эйнат Орр, доктор философии, соавтором lakeFS, и отредактировал Пол Сингман , адвокат разработчиков в lakeFS.