
tl;dr:
- Источники на основе данных и интеллектуальный отбор позволят венчурным капиталистам более эффективно и действенно выявлять наиболее перспективных предпринимателей в нужный момент и в любом месте. География и «теплые вступления» со временем станут неактуальными.
- В среднесрочной перспективе поиск поставщиков станет менее важным отличительным признаком, поскольку инвесторы будут постепенно использовать одни и те же источники идентификации.
- Креативность в отношении новых точек данных на этапе обогащения, последующая разработка функций и (полу) автоматизированная оценка (основанная на машинном обучении или детерминированная) на этапе отбора станут основными.
- Бренд венчурного капитала (фирменный бренд + личный бренд отдельного инвестора) и размер фонда (который может платить более высокую оценку без ущерба для размера портфеля и доли участия) будут приобретать все большее значение, поскольку доступ становится основным отличительным признаком - помимо личной пригодности (которая останется ключевой. )
Начнем с простого наблюдения: конкуренция среди венчурных капиталистов растет. Почему? Что ж, разделение рынка на предложение (стартапы) и спрос (капитал, который нужно инвестировать) делает свое дело. В то время как несколько источников предоставляют доказательства того, что количество стартапов всегда - независимо от экономических условий - было примерно постоянным (источник), капитал, который необходимо разместить, стремительно увеличивался. Например, общая стоимость привлеченных средств венчурного капитала выросла в 4,2 раза с 3,5 млрд долларов США в 2009 году до 14,8 млрд долларов США в 2019 году (источник), что можно отнести к большему количеству привлеченных средств, но также и к более крупным привлеченным средствам (источник). В результате все большему числу венчурных фирм необходимо инвестировать все больший капитал в ограниченное количество активов. Очевидно, этот дисбаланс привел к увеличению оценки стартапов, но, что более интересно, венчурные капиталисты стали более креативными в своем инвестиционном процессе.
Если посмотреть на инвестиционный процесс венчурного капитала и характеристики соответствующих этапов, как показано ниже, становится ясно, что мало что изменилось с момента создания класса активов около 80 лет назад. На сегодняшний день этот процесс по-прежнему очень ручной, субъективный, трудоемкий и трудно масштабируемый.
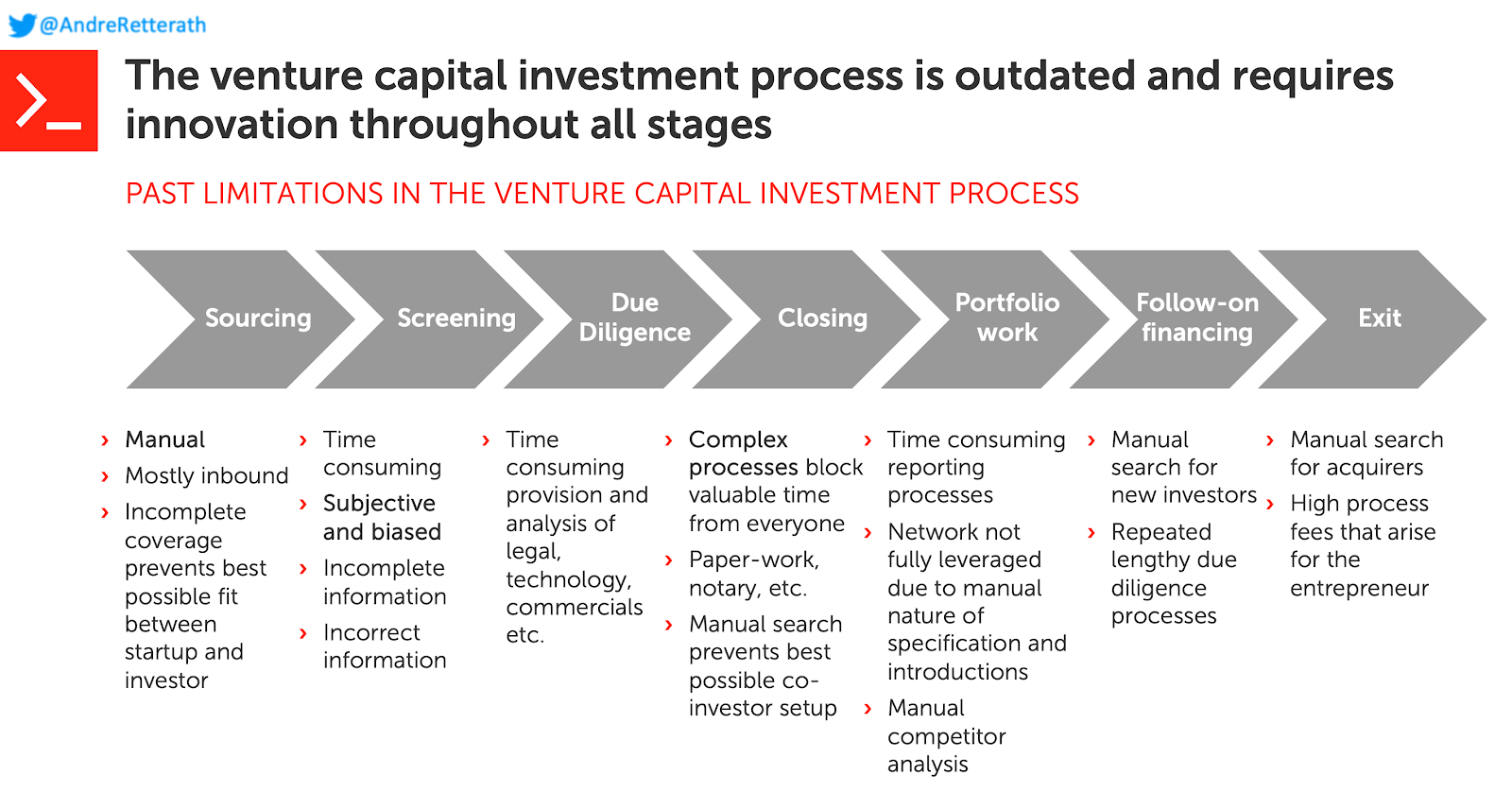
Короче говоря, речь идет о поиске подходящих возможностей, получении доступа / инвестировании и помощи в их росте. Согласно нескольким исследованиям (источник), венчурные капиталисты генерируют около 60% своей общей стоимости на этапах поиска и отбора. В результате обострения конкуренции и того факта, что поиск поставщиков и проверка являются основными рычагами создания стоимости, венчурные капиталисты начали вводить новшества в соответствующие процессы, чтобы выявить наиболее многообещающие возможности раньше, чем это сделают их конкуренты. Как и в большинстве отраслей, данные и интеллектуальные алгоритмы оказались подходящими инструментами для этой задачи.
В результате более 100 интервью с венчурными инвесторами, 2,5 лет исследований на степень доктора философии по теме машинного обучения в венчурном капитале и моего собственного пути по созданию механизма поиска и проверки на основе данных в Earlybird, я придумал следующую структуру, включая некоторые ( более-менее очевидные) примеры:
🛒 ИСТОЧНИК
В своей ментальной модели я разделил поиск источника на два отдельных этапа: идентификация и обогащение.
1) Идентификация (строки в таблице): найдите каждую компанию как можно раньше. Наводящий вопрос: «Где в первую очередь может появиться новая компания?» Это могут быть новые регистрации или раунды финансирования, зарегистрированные в публичных реестрах, таких как Handelsregister или Companies House, репозитории трендов на Github, продукты, запущенные на ProductHunt, или изменение своего описания в LinkedIn на «скрытность» или «Основатель в XYZ». Если предположить, что я пропустил регистрацию компании, я все равно могу поймать их, когда бизнес-ангел или предпосевной / посевной фонд инвестирует, регулярно просматривая веб-сайты их портфелей. Все дело в том, чтобы как можно раньше найти как можно больше компаний, т. Е. Увеличить количество наблюдений (или строк в таблице).
Дополнительное примечание для предпосевных / посевных инвесторов: вот почему в конечном итоге может иметь смысл правильный веб-сайт портфолио;) - инвесторы следующего этапа будут всегда благодарны 🙏🏻.

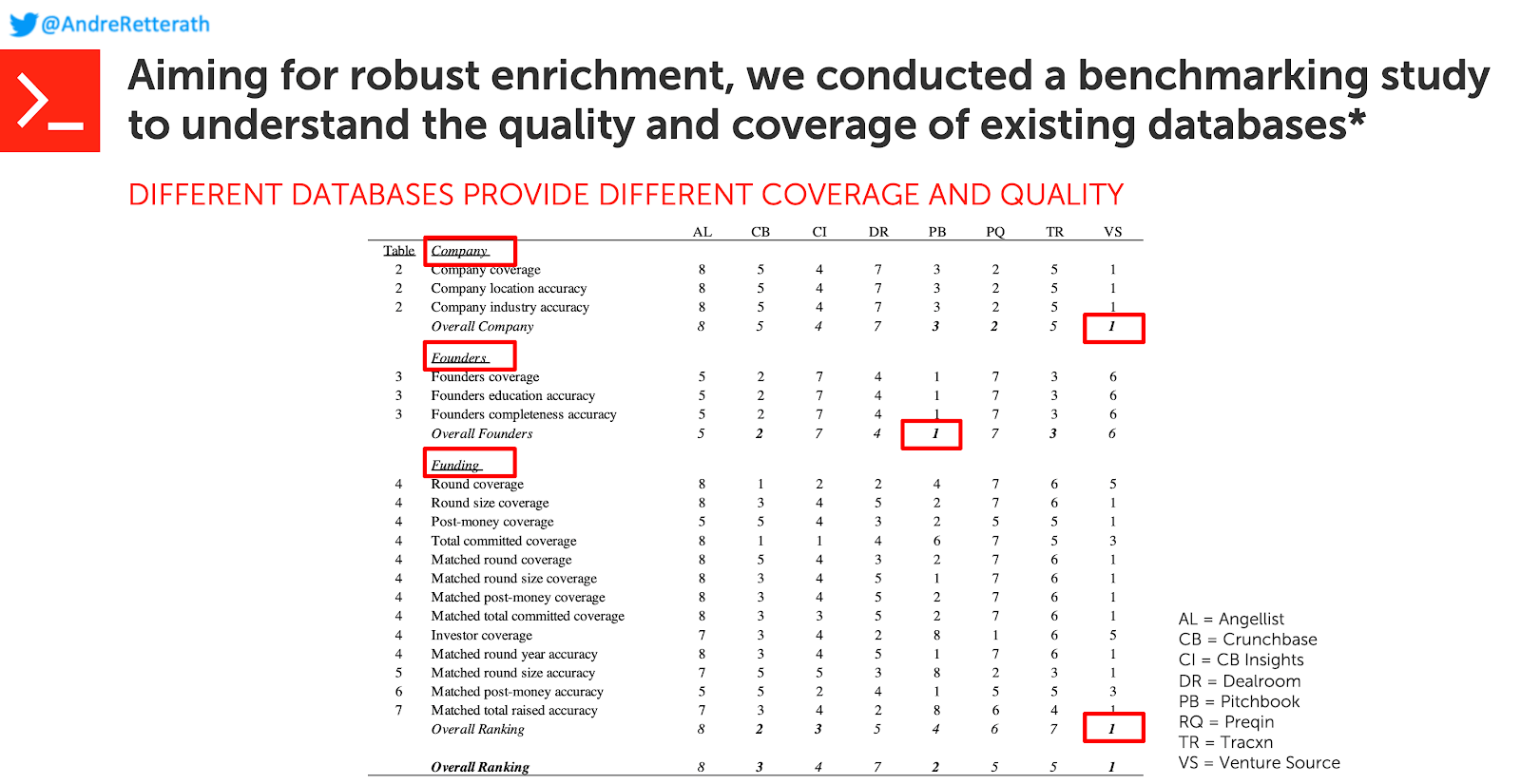
2) Обогащение (столбцы на вашем листе): после определения я стараюсь собрать как можно больше информации для создания всеобъемлющего профиля компании, т. е. увеличивая количество функций (или столбцов в вашем листе). .) Я беру имя и URL-адрес в качестве уникального идентификатора и передаю его API-интерфейсам различных поставщиков коммерческих баз данных, чтобы узнать, собрали ли они уже некоторую информацию о компании. Если да, то отлично! Я собираю всю статическую информацию, такую как описание компании, отраслевую классификацию или головной офис, из базы данных, которая показывает самый высокий охват и качество в соответствующих измерениях. Для подробного сравнения охвата и качества данных по Angellist, Crunchbase, CB Insights, Dealroom, Pitchbook, Preqin, Tracxn и VentureSource (которые недавно были приобретены CB Insights) см. Сводную таблицу ниже и более подробный отчет о моем сравнительном исследовании. "здесь".
После сбора статических данных я сосредотачиваюсь на потенциально изменяющейся информации, такой как LinkedIn, Twitter или обзоры продуктов, и отслеживаю это изменение до исходных источников. Я называю эти функции «метриками роста» и буду ссылаться на них еще раз в дальнейшем. Для простого обогащения я собираю абсолютные показатели, такие как фактическое количество сотрудников в компании, количество твитов, подписчиков и т. Д. Или количество и рейтинг отзывов о продуктах. Более того, я дополняю профили компаний, собирая данные о платежах, посещаемости веб-сайтов, упоминания в Новостях Google, информацию из магазина приложений и многие другие данные в Интернете. Сопоставление одной и той же точки данных в разных источниках часто помогает проверить или удалить неверную информацию.

Очевидно, что цель этапа поиска поставщиков - как можно раньше увидеть как можно больше компаний, а затем собрать как можно больше информации. Похоже, здесь нет никаких недостатков, и, следовательно, чем больше источников, тем лучше. Каждый источник увеличивает потенциал для поиска другой компании, и креативность становится ключевым моментом. К сожалению, когда я разговаривал с более чем 100 венчурными инвесторами и внешними поставщиками данных, которые работали над этой темой, кое-что мне стало ясно: хотя сегодня выбор источников данных на основе данных может быть отличительным признаком, существует лишь очень много доступных источников идентификации, и большинство из них можно определить с помощью довольно очевидных методов, описанных выше. Следовательно, я предполагаю, что в среднесрочной и долгосрочной перспективе фокус и главный рычаг сместятся с поиска поставщиков на отбор.

🧐 СКРИНИНГ
Предполагая всесторонний охват стартапов и широкий спектр информации по каждой компании, моя команда и я создали инструмент поиска в Earlybird, который дает более 30 тысяч потенциальных возможностей в год только в Европе (включая неинтегрированные концепции, бета-продукты и т. Д.). , у нас не было ресурсов, чтобы рассмотреть их все по отдельности, и поэтому нам нужно было автоматизировать процесс проверки. Я написал специальную статью на эту тему здесь и разделил скрининг на детерминированный и случайный / основанный на ML подходы.
1) Детерминированный
Простые в реализации, но очень эффективные детерминированные системы показателей помогают мне получить подробную оценку, основанную на описанных выше «показателях роста». Как описано на этапе 2) Расширение, я собираю эти показатели роста, чтобы составить первоначальный профиль компании. Что касается детерминированного скрининга, то я собираю их на регулярной основе, чтобы перейти от статических данных к динамическим и измерить изменения между t1 и t2. В результате я получаю показатели абсолютного роста, такие как количество сотрудников, подскочивших с 13 в t1 до 20 в t2, а также относительный рост в процентах, например 53% в описанном примере. Сочетая абсолютные цифры с их относительным ростом, я уже получаю мощные сигналы, указывающие на интересные компании. По мере увеличения количества показателей роста и расчета различных сигналов становится все труднее интерпретировать их все вручную. Поэтому я создал систему оценок, в которой определенное значение (на основе нашего опыта) придается различным показателям роста, что приводит к единой оценке. Хотя этот подход переносит эффективность в другую сферу, он все еще очень субъективен, поскольку основан на нашем собственном опыте в отношении индивидуальных весов.
2) На основе машинного обучения
Как описано в моем посте здесь, подходы на основе машинного обучения могут решить эту проблему, поскольку они устраняют субъективность. Подобно тому, как Handelsblatt недавно написал об этом в своем обзоре моего исследования: Вместо того, чтобы указывать алгоритму предоставлять стартапы, которые соответствуют определенным критериям, я переворачиваю его и показываю алгоритму несколько успешных стартапов и прошу его выбрать похожие ". Я обучил несколько контролируемых алгоритмов машинного обучения делать именно это. Чтобы сравнить их эффективность с текущим положением дел (проверка венчурными капиталистами), я провел сравнительный анализ 111 европейских венчурных инвестиций. профессионалы и полученные алгоритмы. Мои результаты показывают, что классификатор XGBoost работает по крайней мере так же хорошо, как лучший VC, на 25% лучше, чем средний VC, и на 29% лучше, чем средний VC в тестовой выборке. (Если вы пропустили, прочтите «здесь.)

Похоже на идеальное решение. Почти. К сожалению, есть одна серьезная проблема с подходом на основе машинного обучения: алгоритмы необходимо обучать на исторических данных, которые могут не содержать шаблонов, которые помогут идентифицировать будущие успешные случаи. То, что могло быть примером успеха для корпоративного программного обеспечения или потребительских компаний в прошлом, может оказаться неверным для стартапов в области квантовых вычислений в будущем. Предполагая, что венчурные капиталисты будут полагаться исключительно на алгоритмы скрининга, обученные на исторических данных, они будут отражать прошлое в будущее без учета потенциальных изменений. также будет катастрофой для меньшинств, которые еще не получили финансирование или добились успеха только в прошлом, поскольку такие модели предполагают, что это не изменится в будущем. Чтобы смягчить эту проблему, мы могли бы повторно ввести детерминированные правила, которые отменяют важность функции на основе машинного обучения в некоторых измерениях. Например, хотя классификатор XG может отменить выбор компании с миноритарным учредителем для дальнейшего выбора, мы все равно можем включить ее и автоматически выбрать для дальнейшей оценки.
Таким образом, наиболее многообещающий подход к скринингу выглядит как гибрид подходов на основе машинного обучения, которые необходимо выборочно корректировать с помощью детерминированных правил. (Не) к счастью, в компьютерах отсутствует - по крайней мере, на сегодняшний день - один важный компонент: (реальный) человеческий фактор. Венчурные капиталисты инвестируют в предпринимателей, и большинство людей согласны с тем, что в конечном итоге все сводится к команде, их мотивации, их упорству, духу и многим другим нематериальным активам, к которым мы, люди, можем получить доступ лучше, чем машины. Следовательно, чтобы использовать все сильные стороны для наиболее эффективного и действенного взаимодействия, я предлагаю расширенный подход.
🤖 ДОПОЛНИТЕЛЬНЫЙ ВК 👱🏻♀️
Я определяю расширенный подход как гибрид между людьми и машинами. Инструменты поиска на основе данных помогают венчурным капиталистам приблизиться к всеобъемлющему охвату, а инструменты проверки на основе машинного обучения сужают верхнюю - постоянно растущую - часть воронки сделки до постоянного числа инвестиционных возможностей. В результате специалисты по инвестициям могут значительно сэкономить время, потраченное на менее многообещающие возможности, которые затем могут быть сосредоточены на правильной оценке предварительного отбора перспективных. Они могут использовать высвободившиеся ресурсы для налаживания более тесных отношений с выбранными предпринимательскими командами и занять более выгодные позиции для заключения наиболее конкурентоспособных сделок. Вместо того, чтобы расширяться и ограничиваться, выделяя ограниченные ресурсы для постоянно растущего числа возможностей, использование инструментов скрининга на основе машинного обучения высвобождает время и позволяет венчурному капиталисту углубляться и ограничиваться выбранным числом возможностей, при этом гарантируя, что многообещающие сделки не остаются без внимания. Это беспроигрышный вариант как для предпринимателей, так и для инвесторов, поскольку обе стороны могут лучше узнать друг друга. В Earlybird моя команда и я реализовали такой расширенный подход в соответствии со следующей структурой.
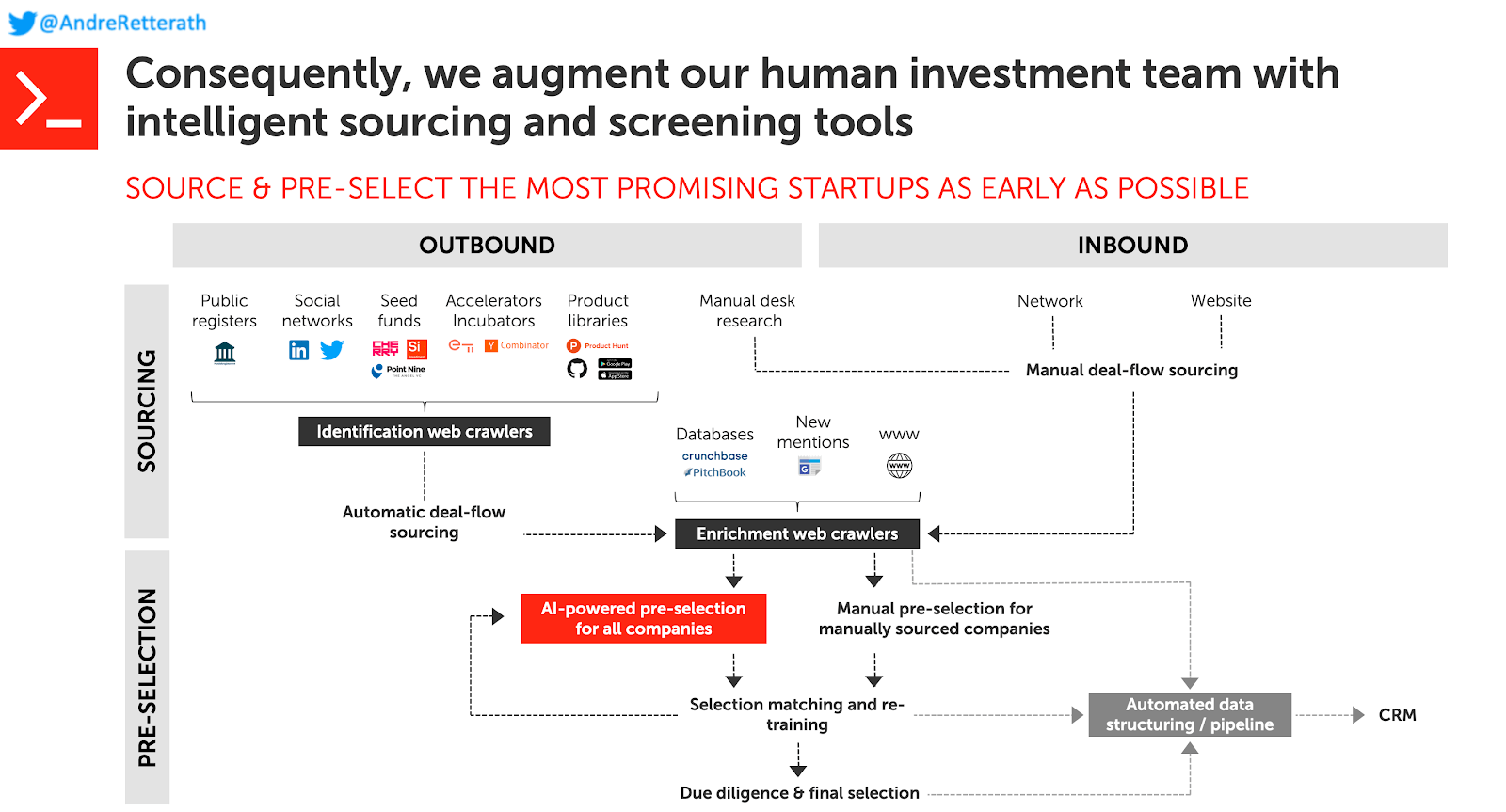
Основываясь на результатах и отзывах предпринимателей и LP, наш подход сегодня является явным отличием. Это позволяет нам более эффективно и действенно определять наиболее перспективных предпринимателей в нужный момент времени и в любом месте. География и «теплые вступления через эксклюзивные сети» в конечном итоге потеряют актуальность (хотя это может занять некоторое время ...)
Однако если подумать о среднесрочном будущем, количество венчурных капиталистов, использующих аналогичные наборы инструментов, будет увеличиваться. Венчурные капиталисты больше не будут ждать, пока на их стол появятся лучшие инвестиционные возможности, а обратятся к учредителям раньше, чем это сделают их конкуренты. Следовательно, поток сделок сместится с в основном входящей (основатели обращаются к венчурным капиталистам) в прошлом к модели все более и более исходящей (венчурные капиталисты активно обращаются к учредителям) в будущем.
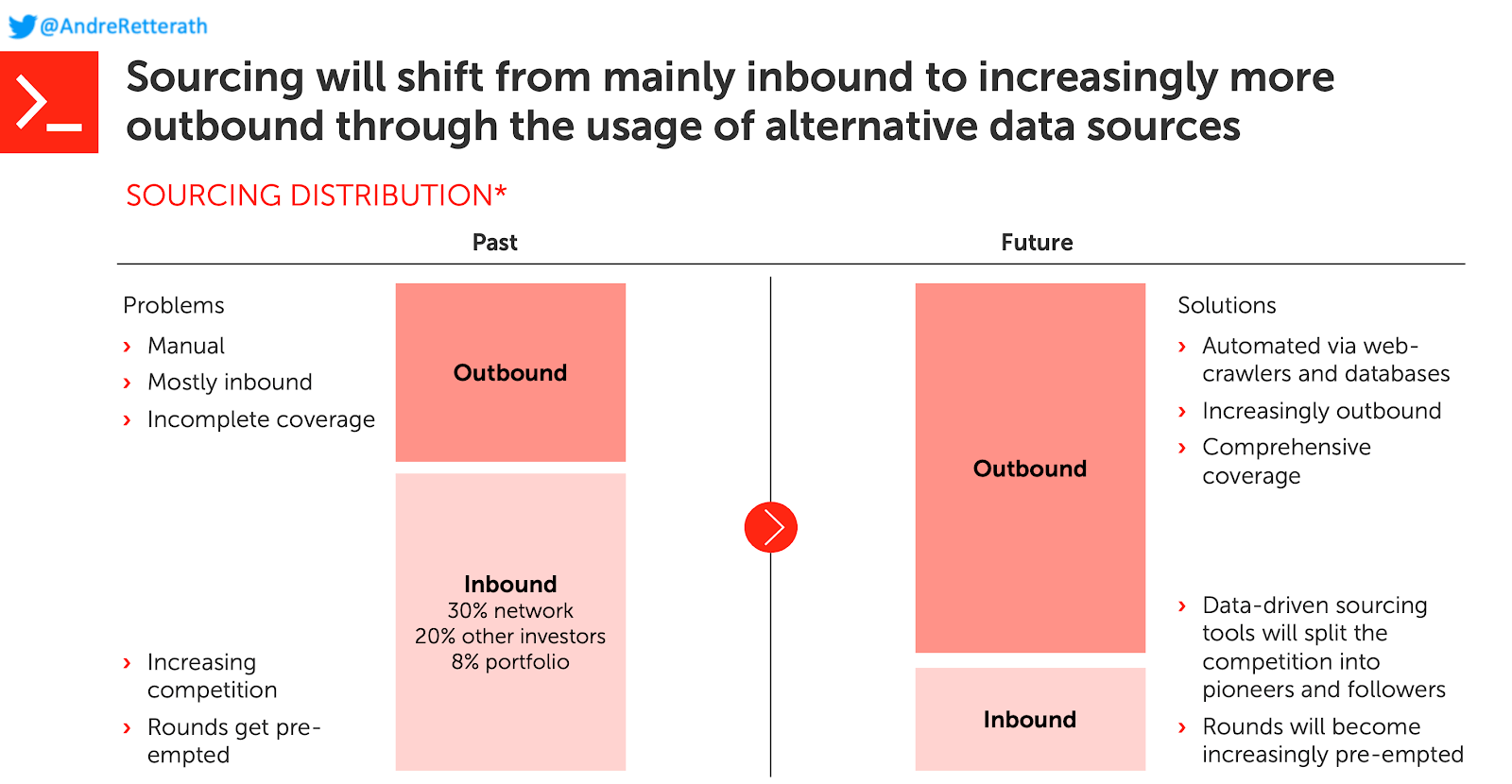
Итак, каковы могут быть долгосрочные последствия? Я ожидаю, что их будет три:
- Поиск поставщиков станет менее важным отличительным признаком, поскольку инвесторы будут постепенно использовать одни и те же поисковые роботы для идентификации.
- Креативность в отношении новых источников данных на этапе обогащения, в последующем проектировании функций и в (полу) автоматизированной оценке (основанной на машинном обучении или детерминированной) станет ключевой.
- Время между сигналом роста и первой встречей в отрасли сократится. Многообещающий сигнал роста, будь то скачок звезд на Github или голоса за / «Охота дня» на ProductHunt, может привести к нескольким автоматическим «Привет, основатель, давай поговорим! Выберите слот в моем Calendly здесь »- электронные письма от венчурных капиталистов. В этом экстремальном (но ИМХО вероятном) сценарии доступ к сделкам будет становиться все более важным, поскольку большинство инвесторов будут конкурировать за очень небольшое количество потенциальных сделок - в (более или менее) в одно и то же время. Понятно, что не все из них смогут инвестировать. Хотя исторически лучшие венчурные капиталисты могли выбирать, с какими учредителями они хотят работать, сегодня и тем более в будущем, все будет наоборот: лучшие основатели могут выбирать, с какими венчурными инвесторами они хотят работать. По мере того, как отрасль венчурного капитала становится более эффективной, основными станут два «компонента доступа»: доступность капитала (который венчурная компания может заплатить наивысшую оценку) и бренд венчурного капитала ( фирменный бренд + личный бренд индивидуального инвестора) - помимо персональной подгонки (которая останется ключевой)! Глядя на наших друзей в США, это кажется правдой уже сегодня.
У венчурного капитала светлое будущее, и я уверен, что описанные выше усилия - это только начало трансформации нашей отрасли. Дальнейшие усилия, вероятно, будут включать в себя более поздние этапы процесса, начиная от комплексной проверки до выхода. Посмотрим, какое будущее ждет! 🚀🚀
Вы - основатель, отраслевой эксперт, венчурный инвестор или исследователь, интересующийся сферами поиска источников на основе данных, искусственного интеллекта, инструментов разработчика или бизнес-моделей с открытым исходным кодом? Я был бы более чем счастлив узнать о вашей работе, поэтому не стесняйтесь обращаться по адресу [email protected].
Понравилась эта статья?
›› Подпишитесь на меня в twitter, чтобы узнать больше об искусственном интеллекте, инструментах разработки и венчурном капитале.