Pluribus использовал невероятно простые методы искусственного интеллекта, чтобы установить новые рекорды в безлимитном техасском холдеме на шесть игроков. Как это получилось?

Недавно я начал новый информационный бюллетень, посвященный образованию в области искусственного интеллекта. TheSequence - это информационный бюллетень, ориентированный на искусственный интеллект (то есть без рекламы, без новостей и т. Д.), На чтение которого уходит 5 минут. Наша цель - держать вас в курсе проектов, исследовательских работ и концепций машинного обучения. Пожалуйста, попробуйте, подписавшись ниже:
В эти выходные я долго разговаривал с одним из моих коллег о несовершенных информационных играх и глубоком обучении, и напомнил мне статью, которую я написал в прошлом году, поэтому я решил переиздать ее.
Покер остается одной из самых сложных игр в области искусственного интеллекта (ИИ) и теории игр. От создателя теории игр Джона фон Неймана, писавшего о покере в своем эссе Теория салонных игр в 1928 году, до мастерской книги Эдвард Торп Побей дилера и MIT Blackjack Team, стратегии покера были навязчивой идеей. математикам на протяжении десятилетий. В последние годы ИИ добился определенного прогресса в покерной среде с помощью таких систем, как Libratus, победив профессиональных игроков в безлимитном холдеме для двух игроков в 2017 году. В прошлом году команда исследователей ИИ из Facebook в сотрудничестве с Карнеги Университет Меллона достиг важной вехи в завоевании покера, создав Pluribus, ИИ-агента, который победил лучших профессиональных игроков-людей в самом популярном и широко распространенном в мире формате покера: безлимитном техасском холдеме на шесть игроков. .
Причины, по которым Pluribus представляет собой крупный прорыв в системах искусственного интеллекта, могут ввести в заблуждение многих читателей. Ведь за последние годы исследователи искусственного интеллекта добились огромного прогресса в различных сложных играх, таких как шашки, шахматы, го, покер для двух игроков, StarCraft 2 и Dota 2. Все эти игры ограничены только двумя игроками и являются играми с нулевой суммой (это означает, что независимо от того, что один игрок выигрывает, другой проигрывает). Другие стратегии ИИ, основанные на обучении с подкреплением, позволили освоить многопользовательские игры Dota 2 Five и Quake III. Тем не менее, безлимитный техасский холдем на шесть игроков по-прежнему остается одной из самых труднодостижимых задач для систем искусственного интеллекта.
Освоение самой сложной игры в покер в мире
Сложность игры в безлимитный техасский холдем на шесть игроков можно разделить на три основных аспекта:
1) Работа с неполной информацией.
2) Трудность достижения равновесия по Нэшу.
3) Успех требует психологических навыков, таких как блеф.
В теории искусственного интеллекта покер классифицируется как среда с несовершенной информацией, что означает, что игроки никогда не имеют полного представления об игре. Ни одна другая игра не воплощает в себе проблему скрытой информации так, как покер, где у каждого игрока есть информация (его или ее карты), которой не хватает другим. Кроме того, действие в покере сильно зависит от выбранной стратегии. В играх с идеальной информацией, таких как шахматы, можно решить состояние игры (например, конец игры), не зная о предыдущей стратегии (например, дебют). В покере невозможно отделить оптимальную стратегию для конкретной ситуации от общей стратегии покера.
Вторая проблема покера основана на сложности достижения равновесия по Нэшу. Названное в честь легендарного математика Джона Нэша, равновесие по Нэшу описывает стратегию в игре с нулевой суммой, в которой игрок гарантированно выиграет независимо от ходов, выбранных его противником. В классической игре камень-ножницы-бумага стратегия равновесия Нэша заключается в случайном выборе камня, бумаги или ножниц с равной вероятностью. Проблема с равновесием по Нэшу состоит в том, что его сложность возрастает с увеличением числа игроков в игре до уровня, при котором невозможно следовать этой стратегии. В случае покера с шестью игроками достижение равновесия по Нэшу во многих случаях невозможно с вычислительной точки зрения.
Третья проблема безлимитного техасского холдема на шесть игроков связана с его зависимостью от психологии человека. Успех в покере зависит от эффективного рассуждения о скрытой информации, выбора правильных действий и обеспечения непредсказуемости стратегии. Успешный игрок в покер должен уметь блефовать, но слишком часто блеф открывает стратегию, которую можно обыграть. На протяжении всей истории системы ИИ оставалось сложной задачей для овладения такими навыками.
Pluribus
Как и многие другие недавние прорывы в области искусственного интеллекта, Pluribus полагался на модели обучения с подкреплением, чтобы овладеть игрой в покер. Ядро стратегии Pluribus было вычислено посредством самостоятельной игры, в которой ИИ играет против своих копий, без каких-либо данных о человеческой или предыдущей игре ИИ, используемых в качестве входных данных. ИИ начинает с нуля, играя случайным образом, и постепенно улучшается по мере того, как он определяет, какие действия и какое распределение вероятностей по этим действиям приводят к лучшим результатам по сравнению с более ранними версиями его стратегии.
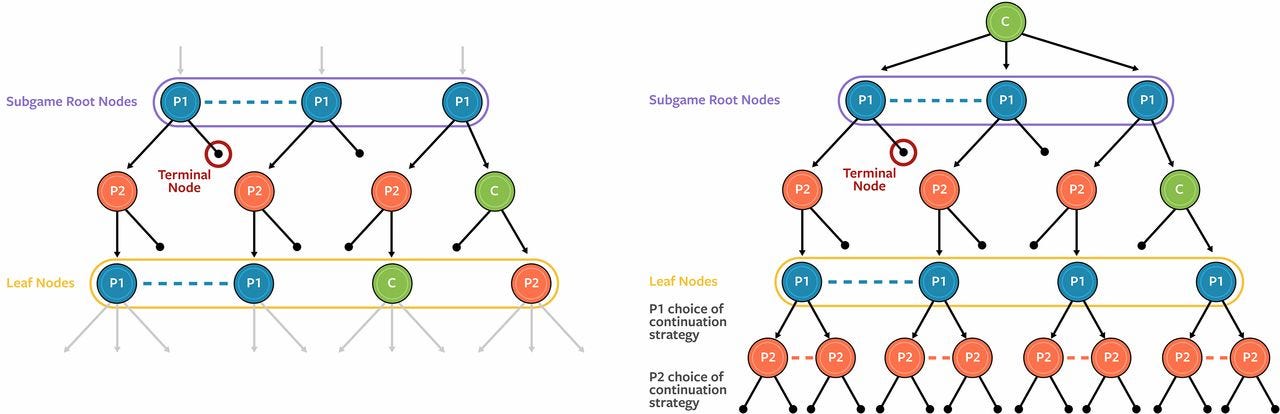
В отличие от других многопользовательских игр, любая позиция в безлимитном техасском холдеме на шесть игроков может иметь слишком много точек принятия решений, чтобы обдумывать их индивидуально. Pluribus использует технику, называемую абстракцией, чтобы сгруппировать похожие действия вместе и исключить другие, уменьшая объем решения. Текущая версия Pluribus использует два типа абстракций:
· Абстракция действий: этот тип абстракции сокращает количество различных действий, которые ИИ должен учитывать. Например, ставка 150 или 151 доллар может не иметь значения с точки зрения стратегии. Чтобы уравновесить это, Pluribus учитывает только несколько размеров ставок на любом этапе принятия решения.
· Информационная абстракция: этот тип абстракции группирует точки принятия решений на основе обнаруженной информации. Например, стрит со старшей десяткой и стрит со старшей девяткой - разные руки, но, тем не менее, стратегически они похожи. Pluribus использует абстракцию информации только для рассуждений о ситуациях в будущих раундах ставок, но никогда о раунде ставок, в котором он находится на самом деле.
Чтобы автоматизировать самостоятельное обучение, команда Pluribus использовала версию итеративного алгоритма Монте-Карло CFR (MCCFR). На каждой итерации алгоритма MCCFR назначает одного игрока «проходящим», текущая стратегия которого обновляется на итерации. В начале итерации MCCFR имитирует покерную комбинацию на основе текущей стратегии всех игроков (которая изначально является полностью случайной). После того, как смоделированная рука завершена, алгоритм просматривает каждое решение, принятое обходчиком, и исследует, насколько лучше или хуже он мог бы его сделать, выбирая вместо этого другие доступные действия. Затем ИИ оценивает достоинства каждого гипотетического решения, которое было бы принято после этих других доступных действий, и так далее. Разница между тем, что получил бы проходящий за выбор действия, и тем, что проходил бы фактически достигнутое (в ожидании) на итерации добавляется к ложному сожалению о действии. В конце итерации стратегия обходчика обновляется, так что действия с более высоким уровнем контрфактического сожаления выбираются с большей вероятностью.

Результаты обучения MCCFR известны как стратегия проекта. Используя эту стратегию, Pluribus смог освоить покер за восемь дней на 64-ядерном сервере и потребовал менее 512 ГБ оперативной памяти. Графические процессоры не использовались.
Стратегия проекта слишком дорога, чтобы использовать ее в покере в реальном времени. Во время реальной игры Pluribus совершенствует стратегию чертежей, проводя поиск в реальном времени, чтобы определить лучшую и более детальную стратегию для своей конкретной ситуации. Традиционные стратегии поиска очень сложно реализовать в играх с несовершенной информацией, в которых игроки могут менять стратегии в любой момент. Pluribus вместо этого использует подход, в котором искатель явно считает, что любой или все игроки могут перейти к другим стратегиям за пределами конечных узлов подигры. В частности, вместо того, чтобы предполагать, что все игроки играют в соответствии с единственной фиксированной стратегией за пределами конечных узлов, Pluribus предполагает, что каждый игрок может выбрать одну из четырех различных стратегий для игры до конца игры, когда будет достигнут конечный узел. Этот метод приводит к тому, что поисковик находит более сбалансированную стратегию, которая обеспечивает более высокую общую производительность.
Pluribus в действии
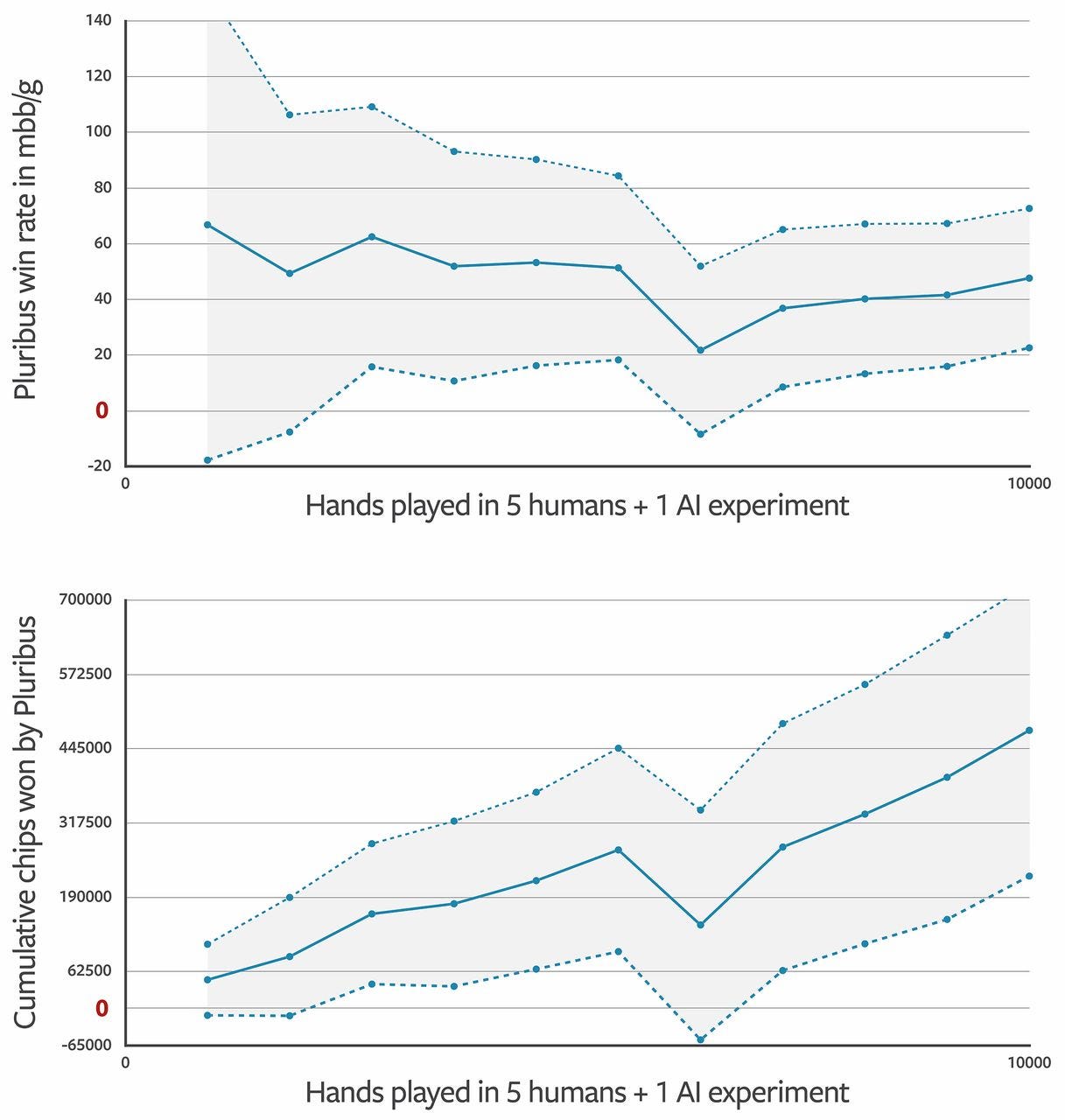
Facebook оценил Pluribus, играя против элитной группы игроков, в которую входили несколько чемпионов World Series of Poker и World Poker Tour. В одном эксперименте Pluribus сыграл 10 000 рук в покер против пяти человек, выбранных случайным образом из пула. Винрейт Pluribus оценивается примерно в 5 больших блайндов на 100 рук (5 bb / 100), что считается очень сильной победой над его элитными оппонентами-людьми (прибыльно при p-value 0,021). Если бы каждая фишка стоила доллар, Pluribus выигрывал бы в среднем около 5 долларов за руку и заработал бы около 1000 долларов в час.
На следующем рисунке показаны результаты Pluribus. На верхнем графике сплошные линии показывают процент побед плюс или минус стандартная ошибка. Нижняя диаграмма показывает количество выигранных фишек в ходе игр.
Pluribus представляет собой один из главных прорывов в современных системах искусственного интеллекта. Несмотря на то, что изначально Pluribus был реализован для покера, общие методы могут быть применены ко многим другим многоагентным системам, которые требуют как искусственного интеллекта, так и навыков человека. Подобно тому, как AlphaZero помогает улучшить профессиональные шахматы, интересно посмотреть, как игроки в покер могут улучшить свои стратегии на основе уроков, извлеченных из Pluribus.