Автор: Ник Спрагг и Ник Рахмел
Введение
За последний год мы начали персонализировать домашнюю страницу iPlayer в гораздо большей степени, чем раньше - вместе с этим произошла реорганизация API.
Все данные, которые требуются любому из клиентов iPlayer для отображения полной домашней страницы, будь то в браузере, на телевизоре или в мобильном приложении, можно запросить одним запросом к базовому API GraphQL.
Каждый ответ персонализирован для пользователя - он включает в себя их текущие просмотренные передачи, их «добавленный» список и рекомендации, адаптированные к их поведению при просмотре.

Проблема
Вся эта персонализация делает каждый ответ уникальным и трудным для кэширования на граничном уровне кэширования.
Если раньше мы могли использовать простой слой кэша, созданный с использованием Varnish, для нескольких сотен различных вариантов домашней страницы, то с новой архитектурой это стало невозможным.
Вычислительные накладные расходы для каждого запроса значительно увеличились, что требует от нас сделать наш код как можно более эффективным и оптимизировать любые задачи, интенсивно использующие ЦП. На начальном этапе разработки мы не достигли ожидаемого уровня производительности прототипа для обработки 3000 запросов в секунду без ущерба для банка, поэтому мы начали выяснять, в чем заключаются наши узкие места.

Благодаря отличным функциям отладки, предоставляемым в текущих версиях Node.js (мы запускаем проект TypeScript на Node.js 8) и инструментам отладки Javascript в Chrome, простое профилирование определило задачу, которая в среднем занимает больше всего процессорного времени. Запросы: Переводы.
Переводы уже давно являются частью iPlayer - веб-сайт локализован на английский, валлийский, шотландский и ирландский гэльский, с сотнями предустановленных строк перевода, и все они применяются в зависимости от пользователя в модуле переводов. этого API.
Модуль переводов
В iPlayer API мы используем модуль перевода для преобразования текста (или частей текста) на указанный язык. Это достигается с помощью шаблонных строк. Например, шаблонная строка типа «# {available-for} 26 # {days}» станет «Доступен в течение 26 дней» на английском языке или «Ar gael am 26 o ddyddiau» на валлийском.
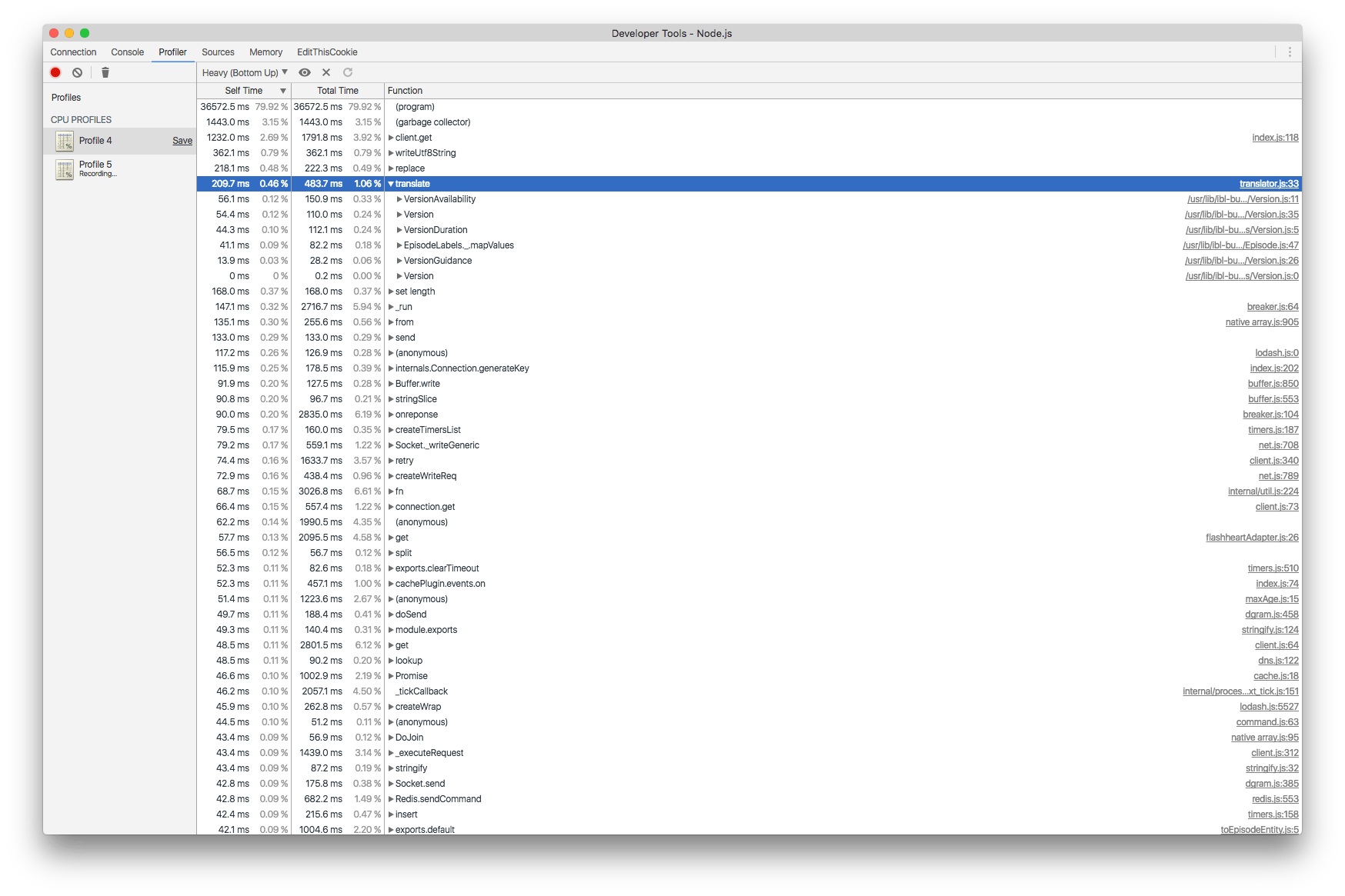
Модуль для этого относительно прост. Он экспортирует функцию translate, которая принимает шаблонную строку и код языкового стандарта. Translate анализирует строку на наличие ключей перевода и ищет каждый ключ в соответствующем поиске перевода. Например, уэльский перевод (cy), «available-for» соответствует «Ar gael am». Есть примерно 100 переводов на каждый язык.
Ключи перевода в строке представлены с использованием следующего синтаксиса: $ {example-translation-key}.
Вот пример английского и валлийского:
const templatedString = '#{available-for} 26 #{days}';
const toEnglish = translate(template, 'en');
console.log(toEnglish) // "Available for 26 days"
const toWelsh = translate(template, 'cy');
console.log(toWelsh) // "Ar gael am 26 o ddyddiau"
Учитывая уровни кэширования в архитектуре iPlayer, такие модули часто писались с учетом простоты, тестируемости и точности, а не производительности.
Вот исходная функция перевода:
const TRANSLATIONS = loadTranslations();
const KEY_REGEX = /#{(.*?)}/g;
function translate(value, language = 'en') {
let translated = value;
Object.keys(TRANSLATIONS[language]).forEach((key) => {
const translation = TRANSLATIONS[language][key];
const re = new RegExp(`#{${key}}`, 'g');
translated = translated.replace(re, translation);
});
return translated;
}
Эта функция переведет ноль или более шаблонов переводов в заданную строку. Это работает, и это очень просто, но неэффективно. Любые идеи? Что ж, для указанного языка он пытается перевести каждый ключ в поиске перевода. В зависимости от того, как этот модуль в настоящее время используется в iPlayer, каждый вызов будет переводить от 0 до 3 переводов. В худшем случае он попытается сделать примерно 100 переводов шаблонов, даже если в строке их нет.
Потенциальная оптимизация состоит в том, чтобы выполнить необходимое количество переводов только для данной строки:
const TRANSLATIONS = loadTranslations();
const KEY_REGEX = /#{(.*?)}/g;
function translate(value, language = 'en') {
if (!value) {
return value;
}
let translated = value;
let match;
while ((match = (KEY_REGEX.exec(value)))) {
if (match) {
const translation = TRANSLATIONS[language][match[1]];
if (translation === undefined) {
continue;
}
const key = "#{" + match[1] + "}";
translated = translated.replace(key, translation);
}
}
return translated;
}
Из строк, содержащих от 0 до 3 переводов, тесты показали, что выборочная замена ключей перевода оказалась значительно быстрее. Конечно, у него есть пара недостатков. Во-первых, хотя это и не ракетостроение, оно добавляет дополнительную сложность. Во-вторых, из-за цикла while производительность падает, когда строка имеет 4 или более ключей.
Дальнейшая проверка сигнатуры метода замены строки Javascript показала, что в качестве второго параметра может быть указана функция замены. Эта функция замены будет вызываться после того, как будет найден каждый перевод.
Вот вариант функции перевода с использованием «string.replace» с предоставленной функцией замены:
const TRANSLATIONS = loadTranslations();
const KEY_REGEX = /#{(.*?)}/g;
function translate(value, language = 'en') {
if (!value) {
return value;
}
return value.replace(KEY_REGEX, (a, b) => {
const translation = TRANSLATIONS[b];
if (translation === undefined) {
return a;
}
return translation;
});
}
Возможно более элегантное решение. Как показывает практика, многократное использование стандартных библиотек или надежных сторонних решений часто приносит свои плоды, а не развертывание собственных решений. Талантливые инженеры уже потратили время на оптимизацию и повышение надежности кода. Кроме того, стандартные библиотеки официально поддерживаются и будут хорошо протестированы.
Это было очевидно по тестам; это решение оказалось таким же быстрым (приблизительно), как первая оптимизация для 0–3 переводов, но значительно быстрее для 4 или более.
Проверка
Когда дело доходит до такой оптимизации, одной из основных целей является удобство работы пользователей и максимально быстрое обслуживание большинства запросов.
Чтобы проверить наши изменения, мы запускаем нагрузочные тесты в контролируемой тестовой среде. Наряду с описанным выше профилированием, это информирует нас о приоритетах потенциальных оптимизаций.
Первая итерация
Для нашей первоначальной проверки нам нужно было найти текущий предел. Мы используем G atling в качестве инструмента нагрузочного тестирования со сценарием, который может делать персонализированные запросы для любого количества профилей пользователей и конфигураций клиентов. Мы можем выбирать для тестирования с репрезентативным разделением аудитории, в основном предпочитающим английский язык, или даже с разделением всех поддерживаемых нами языков.
Поскольку наша цель заключалась в улучшении затрат ЦП на переводы, а не в том, как мы храним или кэшируем результаты, это в значительной степени не имеет значения, и мы тестировали с равномерным разделением языков. Мы выбрали 2 экземпляра относительно небольшого типа машины и относительно небольшого количества пользователей, 30; каждый делает до 1 запроса в секунду.
Глядя на время отклика с течением времени, мы получаем следующий график:

Здесь мы видим, что время отклика вначале стабильное и с небольшими вариациями времени отклика, но к тому времени, когда мы достигаем 20 или около того пользователей, они достигают более одной секунды, что приводит к тому, что мы не достигаем нашей цели 30 оборотов в секунду, поскольку каждый пользователь должен ждать их просьбу завершить, прежде чем они смогут сделать новую. Однако полностью API не вываливается - в районе 12:00:20 наблюдается гораздо более заметное замедление, но оно само восстанавливается.
Улучшения
С нашей первой итерацией улучшений алгоритма мы получаем гораздо более стабильный график с той же тестовой настройкой:

Есть мгновенные всплески времени отклика для верхних процентилей, которые связаны с некоторыми обновлениями кеша и не имеют отношения к этому. Мы внесли улучшения! Но каков наш новый предел?
Для нашего второго раунда тестирования мы меняем настройку теста: сейчас мы используем только одну машину для запуска API, и мы увеличиваем количество пользователей итеративно, пока не найдем новый предел. Это график для 50 пользователей:

Мы можем снова игнорировать минутные всплески, как и раньше.
Как и раньше, когда мы набираем около 40 пользователей, замедление становится очень заметным, и, глядя на профилирование, кажется, что мы можем внести еще несколько улучшений - translate по-прежнему занимает большую часть процессорного времени для наших ответов, и мы бы хотелось бы выжать из этого каждую каплю производительности.
Окончательные результаты
После второго раунда улучшений с той же настройкой теста наш график выглядит следующим образом:

Похоже, что он снова начинает замедляться у 20 пользователей, но если мы посмотрим на левую ось Y, мы увидим, что диапазон замедлений намного ниже и находится в допустимом диапазоне для этого нагрузочного теста.
Профилирование теперь показывает нам, что перевод - не самая большая нагрузка на ЦП, и в сочетании с приведенным выше графиком пора посмотреть, откуда берутся некоторые закономерности в пиках. Но это уже для другого поста!