
Советы по программированию
12 способов применить функцию к каждой строке в Pandas DataFrame
Как профилировать производительность и сбалансировать ее с простотой использования
Применение функции ко всем строкам в Pandas DataFrame - одна из самых распространенных операций во время обработки данных. Функция Pandas DataFrame apply - наиболее очевидный выбор для этого. Он принимает функцию в качестве аргумента и применяет ее вдоль оси DataFrame. Однако это не всегда лучший выбор.
В этой статье вы оцените эффективность 12 альтернатив. С помощью сопутствующей лаборатории Code Lab вы можете попробовать все это в своем браузере. Не нужно ничего устанавливать на вашу машину.
Проблема
Недавно я анализировал данные о поведении пользователей для приложения электронной коммерции. В зависимости от того, сколько раз пользователь выполнял текстовый и голосовой поиск, я назначил каждого пользователя одной из четырех когорт:
- Без поиска: пользователи, которые вообще не выполняли поиск.
- Только текст: пользователи, которые выполняли только текстовый поиск.
- Только голосовой поиск: пользователи, которые выполняли только голосовой поиск.
- Оба: пользователи, которые выполняли как текстовый, так и голосовой поиск.
Это был огромный набор данных от 100 тыс. До миллиона пользователей в зависимости от выбранного временного интервала. Вычисление его с помощью функции Pandas apply было мучительно медленным, поэтому я оценил альтернативы. Эта статья - извлеченные из этого уроки.
Я не могу поделиться этим набором данных. Поэтому я выбираю еще одну похожую проблему, чтобы показать решения: метод Эйзенхауэра.

В зависимости от важности и срочности задачи метод Эйзенхауэра помещает ее в одну из 4 ячеек. У каждого бункера есть связанное действие:
- Важно и срочно: Сделайте прямо сейчас
- Важно, но не срочно: Запланировать на потом
- Не важно, но срочно: делегировать кому-то другому
- Ни важно, ни срочно: Удалите траты времени.
Мы будем использовать логическую матрицу, показанную на рисунке рядом. Логические значения важности и срочности создают двоичное целочисленное значение для каждого действия: DO (3), SCHEDULE (2), DELEGATE (1), DELETE (0).
Мы профилируем выполнение сопоставления задач с одним из действий. Мы определим, какая из 12 альтернатив займет меньше всего времени. И мы построим график производительности для до миллиона задач.
Пришло время открыть компаньон Code Lab. Если вы хотите увидеть код в действии, вы можете выполнять ячейки в Code Lab по мере чтения. Идем дальше, выполняем все ячейки в разделе Настройка.
Данные испытаний
Faker - удобная библиотека для генерации данных. В Code Lab он используется для создания DataFrame с миллионом задач. Каждая задача - это строка в DataFrame. Он состоит из имени_задачи (str), даты_ выполнения (datetime.date) и приоритета (str). Приоритет может быть одним из трех значений: LOW, MEDIUM, HIGH.

Оптимизировать хранилище DataFrame
Мы минимизируем размер хранилища, чтобы исключить его влияние на любую из альтернатив. DataFrame с ~ 2 миллионами строк занимает 48 МБ:
>>> test_data_set.info() <class 'pandas.core.frame.DataFrame'> RangeIndex: 2097153 entries, 0 to 2097152 Data columns (total 3 columns): # Column Dtype --- ------ ----- 0 task_name object 1 due_date object 2 priority object dtypes: object(3) memory usage: 48.0+ MB
Вместо str приоритет можно сохранить как Pandas categorical типа:
priority_dtype = pd.api.types.CategoricalDtype( categories=['LOW', 'MEDIUM', 'HIGH'], ordered=True ) test_data_set['priority'] = test_data_set['priority'].astype(priority_dtype)
Давайте теперь проверим размер DataFrame:
>>> test_data_set.info() <class 'pandas.core.frame.DataFrame'> RangeIndex: 2097153 entries, 0 to 2097152 Data columns (total 3 columns): # Column Dtype --- ------ ----- 0 task_name object 1 due_date object 2 priority category dtypes: category(1), object(2) memory usage: 34.0+MB
Размер уменьшен до 34 МБ.
Функция действия Эйзенхауэра
Учитывая важность и срочность, eisenhower_action вычисляет целое значение от 0 до 3.
def eisenhower_action(is_important: bool, is_urgent: bool) -> int: return 2 * is_important + is_urgent
В этом упражнении мы предположим, что задача с ВЫСОКИМ приоритетом является важной. Если срок выполнения приходится на следующие два дня, значит задача срочна.
Действие Эйзенхауэра для задачи (т.е. строка в DataFrame) вычисляется с использованием столбцов due_date и priority:
>>> cutoff_date = datetime.date.today() + datetime.timedelta(days=2) >>> eisenhower_action( test_data_set.loc[0].priority == 'HIGH', test_data_set.loc[0].due_date <= cutoff_date ) 2
Целое число 2 означает, что необходимо действие по РАСПИСАНИЮ.
В оставшейся части статьи мы рассмотрим 12 альтернатив применения функции eisenhower_action к строкам DataFrame. Сначала мы измерим время для выборки из 100 тыс. Строк. Затем мы измерим и построим график времени для миллиона строк.

Метод 1. Цикл по всем строкам фрейма данных
Самый простой способ обработать каждую строку в старом добром цикле Python. Очевидно, что это наихудший способ, и никто в здравом уме никогда этого не сделает.
def loop_impl(df):
cutoff_date = datetime.date.today() + datetime.timedelta(days=2)
result = []
for i in range(len(df)):
row = df.iloc[i]
result.append(
eisenhower_action(
row.priority == 'HIGH', row.due_date <= cutoff_date)
)
return pd.Series(result)
Как и ожидалось, на это уходит ужасное количество времени: 56,6 секунды.
%timeit data_sample['action_loop'] = loop_impl(data_sample) 1 loop, best of 5: 56.6 s per loop
Он устанавливает верхнюю границу производительности для наихудшего случая. Поскольку его стоимость линейна, то есть O (n), он обеспечивает хорошую основу для сравнения других альтернатив.
Профилирование на линейном уровне
Давайте выясним, что занимает так много времени, с помощью line_profiler, но для меньшей выборки из 100 строк:
%lprun -f loop_impl loop_impl(test_data_sample(100))
Его результат показан на следующем рисунке:

Извлечение строки из DataFrame (строка № 6) занимает 90% времени. Это понятно, потому что хранилище Pandas DataFrame является главным столбцом: последовательные элементы в столбце сохраняются в памяти последовательно. Так что сборка элементов в ряд обходится дорого.
Даже если мы уберем эти 90% стоимости с 56,6 с для 100 тыс. Строк, это займет 5,66 с. Это еще много.

Метод 2. Обход строк с помощью функции iterrows
Вместо обработки каждой строки в цикле Python давайте попробуем функцию Pandas iterrows.
def iterrows_impl(df):
cutoff_date = datetime.date.today() + datetime.timedelta(days=2)
return pd.Series(
eisenhower_action(
row.priority == 'HIGH', row.due_date <= cutoff_date)
for index, row in df.iterrows()
)
Это занимает 9,04 секунды, прибл. четверть времени, затрачиваемого на петлю:
%timeit data_sample['action_iterrow'] = iterrows_impl(data_sample) 1 loop, best of 5: 9.04 s per loop
Метод 3. Обход строк с помощью функции itertuples
У Pandas есть другой метод itertuples, который обрабатывает строки как кортежи.
def itertuples_impl(df):
cutoff_date = datetime.date.today() + datetime.timedelta(days=2)
return pd.Series(
eisenhower_action(
row.priority == 'HIGH', row.due_date <= cutoff_date)
for row in df.itertuples()
)
Его производительность преподнесла сюрприз, потребовалось всего 211 миллисекунд.
%timeit data_sample['action_itertuples'] = itertuples_impl(data_sample) 1 loops, best of 5: 211 ms per loop
Метод 4. Pandas apply Функция для каждой строки
Функция Pandas DataFrame apply довольно универсальна и пользуется популярностью. Чтобы заставить его обрабатывать строки, вы должны передать аргумент axis=1.
def apply_impl(df):
cutoff_date = datetime.date.today() + datetime.timedelta(days=2)
return df.apply(
lambda row:
eisenhower_action(
row.priority == 'HIGH', row.due_date <= cutoff_date),
axis=1
)
Это тоже стало для меня сюрпризом. Прошло 1,85 секунды. В 10 раз хуже, чем itertuples!
%timeit data_sample['action_impl'] = apply_impl(data_sample) 1 loop, best of 5: 1.85 s per loop
Метод 5. Понимание списка Python
Столбец в DataFrame - это серия, которую можно использовать как список в выражении понимание списка:
[ foo(x) for x in df['x'] ]
Если необходимо несколько столбцов, то zip можно использовать для создания списка кортежей.
def list_impl(df):
cutoff_date = datetime.date.today() + datetime.timedelta(days=2)
return pd.Series([
eisenhower_action(priority == 'HIGH', due_date <= cutoff_date)
for (priority, due_date) in zip(df['priority'], df['due_date'])
])
Это тоже преподнесло сюрприз. Прошло всего 78,4 миллисекунды, даже лучше, чем itertuples!
%timeit data_sample['action_list'] = list_impl(data_sample) 10 loops, best of 5: 78.4 ms per loop
Метод 6. Функция карты Python
Функция Python map, которая принимает функции и итерации параметров и дает результаты.
def map_impl(df):
cutoff_date = datetime.date.today() + datetime.timedelta(days=2)
return pd.Series(
map(eisenhower_action,
df['priority'] == 'HIGH',
df['due_date'] <= cutoff_date)
)
Это сработало немного лучше, чем понимание списка.
%timeit data_sample['action_map'] = map_impl(data_sample) 10 loops, best of 5: 71.5 ms per loop
Метод 7. Векторизация.
Настоящая мощь Pandas проявляется в векторизации. Но для этого нужно распаковать функцию как векторное выражение.
def vec_impl(df):
cutoff_date = datetime.date.today() + datetime.timedelta(days=2)
return (
2*(df['priority'] == 'HIGH') + (df['due_date'] <= cutoff_date))
Это дает лучшую производительность: всего 20 миллисекунд.
%timeit data_sample['action_vec'] = vec_impl(data_sample) 10 loops, best of 5: 20 ms per loop
Векторизация, в зависимости от сложности функции, может потребовать значительных усилий. Иногда это может быть даже неосуществимо.
Метод 8. NumPy vectorize Функция
NumPy предлагает альтернативы для перехода с Python на Numpy посредством векторизации. Например, у него есть vectorize() функция, которая векторзирует любую скалярную функцию для приема и возврата массивов NumPy.
def np_vec_impl(df):
cutoff_date = datetime.date.today() + datetime.timedelta(days=2)
return np.vectorize(eisenhower_action)(
df['priority'] == 'HIGH',
df['due_date'] <= cutoff_date
)
Неудивительно, что его производительность уступает только векторизации Pandas: 35,7 миллисекунды.
%timeit data_sample['action_np_vec'] = np_vec_impl(data_sample) 10 loops, best of 5: 35.7 ms per loop
Метод 9. Декораторы Numba.
Пока использовались только пакеты Pandas и NumPy. Но есть и другие альтернативы, если вы открыты для дополнительных зависимостей пакетов.
Numba обычно используется для ускорения применения математических функций. Он имеет различные декораторы для JIT-компиляции и векторизации.
import numba @numba.vectorize def eisenhower_action(is_important: bool, is_urgent: bool) -> int: return 2 * is_important + is_urgent def numba_impl(df): cutoff_date = datetime.date.today() + datetime.timedelta(days=2) return eisenhower_action( (df['priority'] == 'HIGH').to_numpy(), (df['due_date'] <= cutoff_date).to_numpy() )
Его декоратор vectorize похож на функцию NumPy vectorize, но обеспечивает лучшую производительность: 18,9 миллисекунды (аналогично векторизации Pandas). Но он также выдает предупреждение о кешировании.
%timeit data_sample['action_numba'] = numba_impl(data_sample) The slowest run took 11.66 times longer than the fastest. This could mean that an intermediate result is being cached. 1 loop, best of 5: 18.9 ms per loop
Метод 10. Многопроцессорность с pandarallel
Пакет pandarallel использует несколько процессоров и разбивает работу на несколько потоков.
from pandarallel import pandarallel
pandarallel.initialize()
def pandarallel_impl(df):
cutoff_date = datetime.date.today() + datetime.timedelta(days=2)
return df.parallel_apply(
lambda row: eisenhower_action(
row.priority == 'HIGH', row.due_date <= cutoff_date),
axis=1
)
На двухпроцессорной машине это заняло 2,27 секунды. Накладные расходы на разделение и бухгалтерию, похоже, не окупаются за 100 тыс. Записей и 2 процессора.
%timeit data_sample['action_pandarallel'] = pandarallel_impl(data_sample) 1 loop, best of 5: 2.27 s per loop
Метод 11. Распараллеливание с помощью Dask
Dask - это библиотека для параллельных вычислений, которая поддерживает масштабирование NumPy, Pandas, Scikit-learn и многих других библиотек Python. Он предлагает эффективную инфраструктуру для обработки огромного количества данных в многоузловых кластерах.
import dask.dataframe as dd
def dask_impl(df):
cutoff_date = datetime.date.today() + datetime.timedelta(days=2)
return dd.from_pandas(df, npartitions=CPU_COUNT).apply(
lambda row: eisenhower_action(
row.priority == 'HIGH', row.due_date <= cutoff_date),
axis=1,
meta=(int)
).compute()
На двухпроцессорной машине это заняло 2,13 секунды. Как и pandarallel, выплаты имеют смысл только при обработке большого количества данных на многих машинах.
%timeit data_sample['action_dask'] = dask_impl(data_sample) 1 loop, best of 5: 2.13 s per loop
Метод 12. Оппортунистическое распараллеливание с помощью Swifter.
Swifter автоматически решает, что быстрее: использовать параллельную обработку Dask или применить простую Pandas. Это очень просто использовать: всего одно слово о том, как использовать Pandas, применить функцию: df.swifter.apply.
import swifter
def swifter_impl(df):
cutoff_date = datetime.date.today() + datetime.timedelta(days=2)
return df.swifter.apply(
lambda row: eisenhower_action(
row.priority == 'HIGH', row.due_date <= cutoff_date),
axis=1
)
Его производительность для этого варианта использования, как ожидается, довольно близка к векторизации Pandas.
%timeit data_sample['action_swifter'] = swifter_impl(data_sample) 10 loops, best of 5: 22.9 ms per loop+
Производительность графика по размеру фрейма данных
Построение графиков помогает понять относительную эффективность альтернатив в зависимости от размера входных данных. Perfplot - удобный инструмент для этого. Требуется установка для генерации входных данных заданного размера и список реализаций для сравнения.
kernels = [ loop_impl, iterrows_impl, itertuples_impl, apply_impl, list_impl, vec_impl, np_vec_impl, numba_impl, pandarallel_impl, dask_impl, swifter_impl ] labels = [str(k.__name__)[:-5] for k in kernels] perfplot.show( setup=lambda n: test_data_sample(n), kernels=kernels, labels=labels, n_range=[2**k for k in range(K_MAX)], xlabel='N', logx=True, logy=True, #equality_check=None )
Он генерирует график, подобный показанному ниже.
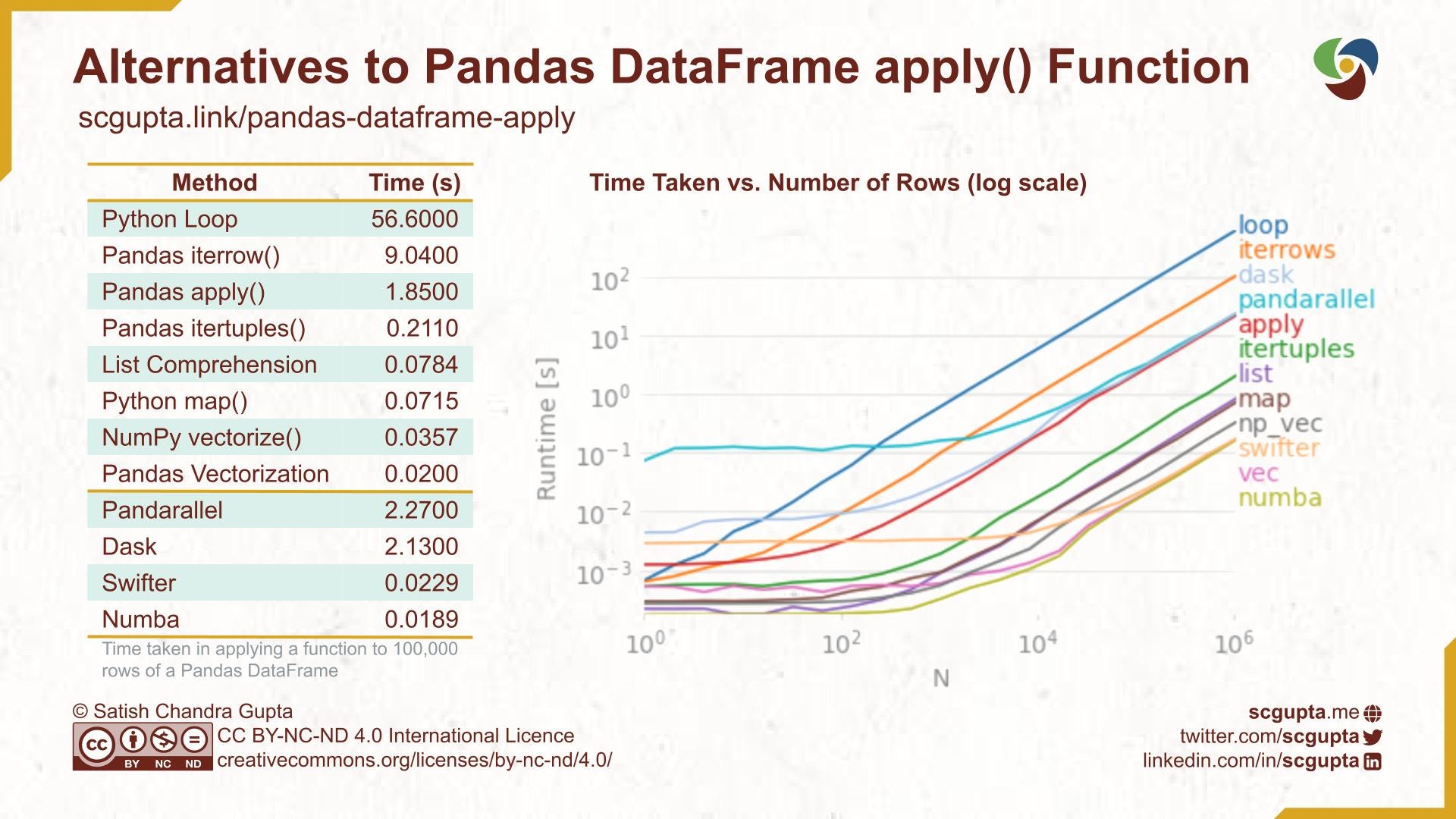
Вот несколько наблюдений из сюжета:
- Для этого варианта использования порядок асимптотической производительности стабилизируется на уровне примерно 10 тыс. Строк в DataFrame.
- Поскольку все линии на графике становятся параллельными, разница в производительности может не быть очевидной на графике в масштабе log-log.
itertuplesтак же прост в использовании, как иapply, но его производительность в 10 раз выше.- Понимание списков примерно в 2,5 раза лучше, чем
itertuples, хотя может быть многословным при написании сложной функции. - NumPy
vectorizeв 2 раза лучше, чем понимание списка, и так же прост в использовании, как функцииitertuplesиapply. - Векторизация Pandas примерно в 2 раза лучше, чем NumPy
vectorize. - Накладные расходы на параллельную обработку окупаются только тогда, когда огромное количество данных обрабатывается на многих машинах.
Рекомендации
Часто требуется выполнение операции независимо для всех строк Pandas. Вот мои рекомендации:
- Векторизация выражения DataFrame: всегда делайте это.
- NumPy
vectorize: Его API не очень сложный. Не требует дополнительных пакетов. Он предлагает почти лучшую производительность. Выберите это, если векторизация DataFrame невозможна. - Понимание списков. Выбирайте эту альтернативу, когда нужны только 2–3 столбца DataFrame, а векторизация DataFrame и векторизация NumPy по какой-то причине невозможны.
- Функция Pandas
itertuples: ее API похож наapplyфункцию, но обеспечивает в 10 раз лучшую производительность, чемapply. Это самый простой и читаемый вариант. Он предлагает разумную производительность. Сделайте это, если предыдущие три не сработали. - Numba или Swift: используйте это, чтобы использовать распараллеливание без сложности кода.
Понимание стоимости различных альтернатив имеет решающее значение для принятия осознанного выбора. Используйте timeit, line_profiler и perfplot для измерения производительности этих альтернатив. Обеспечьте баланс между производительностью и простотой использования, чтобы выбрать лучшую альтернативу для вашего варианта использования.
Если вам это понравилось, пожалуйста:



Поделитесь этим с помощью этой инфографики:
