
Хотите знать, что лучше всего подходит для вашего приложения машинного обучения в Microsoft Azure? Это исследование может помочь вам выбрать наиболее подходящую платформу для ваших целей.
Параметры вычислений в Azure
Azure предоставляет разные вычислительные платформы для разных сценариев использования. Вот список доступных опций в Azure:
Эти платформы созданы, чтобы помочь пользователям быстро наладить работу. Помимо пакетной службы Azure, два других варианта предоставляют пользователям предварительно упакованные программные библиотеки, компоненты и службы. Таким образом, пользователи могут запускать свои приложения со значительно меньшими усилиями и затратами времени. Пользователи могут выбрать наиболее подходящую платформу с учетом необходимых функций и возможностей бюджета.
Стоит отметить, что Служба Azure Kubernetes (AKS) имеет возможность запускать рабочие нагрузки машинного обучения в Azure. В этом исследовании мы не рассматриваем это, поскольку это относится к вычислительным платформам в Azure.
Давайте подробнее рассмотрим каждый из них и сравним их друг с другом.
Лазерные блоки данных
Эта платформа на основе Apache Spark в Azure предоставляет мощное интерактивное рабочее пространство для анализа больших данных в Azure. Типичный конвейер Azure Databrick начинается с приема данных из внешних источников, размещения данных в постоянном хранилище (например, хранилище BLOB-объектов Azure), подготовки и согласования данных и использования данных из обучения машинному обучению. Поскольку объем данных велик, Spark обрабатывает оркестровку, избыточность данных (через RDD) и планирование (с помощью DAG). Данные будут храниться в BLOB-объекте Azure для использования Databricks для подготовки и обучения. Затем модель вывода можно сохранить в любой из баз данных Azure или служб аналитики.

Полная информация о том, как работает Azure Databricks, представлена в документации Azure.
Databricks предоставляет два разных типа кластеров:
- Интерактивный кластер: вычислительная мощность, которая предоставляется заранее и будет работать постоянно.
- Автоматизированный кластер: вычислительная мощность, которая подготавливает кластер по запросу во время отправки задания. Когда работа будет завершена, жизненный цикл кластера завершится и он умрет.
Для работы Databricks требуется как минимум два узла: узел драйвера и рабочий узел. Количество рабочих узлов зависит от задания (заданий). Поэтому для работы всегда требуется более одной машины. Справедливо сказать, что Databricks разработан для массовых параллельных вычислений. Задания будут выполняться параллельно на разных машинах, и Databricks будет обрабатывать выходные данные.
Примечание. Azure Databricks может упаковать форматирование и развертывать модели в Azure ML с помощью MLflow.
Пакетная служба Azure
Пакетная служба Azure также подходит для высокопроизводительных параллельных вычислений. Он выполняет распараллеливание, создавая пул задач и параллельно выполняя их на вычислительных узлах.
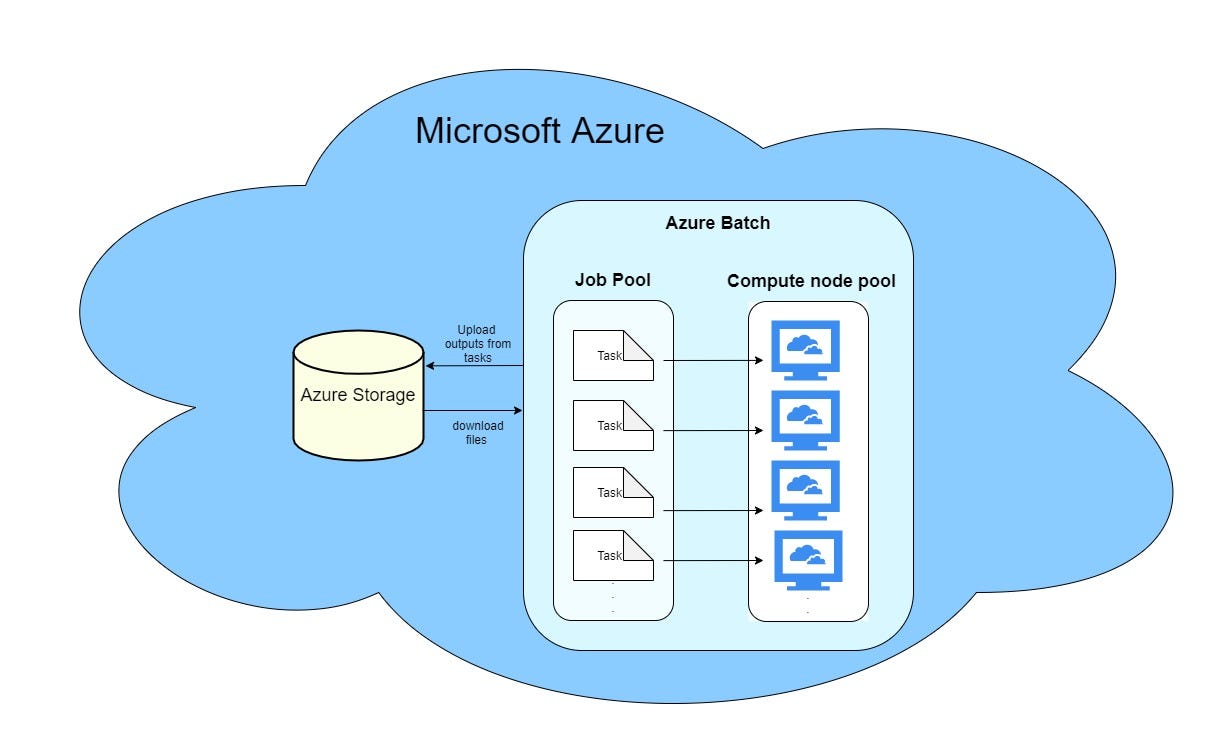
На приведенном выше изображении очень подробно показано, как работает пакетная служба Azure. В сценарии любое приложение может быть подключено к хранилищу Azure для загрузки входных данных и чтения из него выходных данных. Пакетная служба Azure разделяет входные данные на отдельные задачи и выполняет их параллельно в пуле вычислительных узлов, а затем отправляет результаты обратно в хранилище Azure.
Документация по пакетной службе Azure содержит все подробности того, как это работает. Поэтому мы не будем вдаваться в подробности в этом разделе.
Вычисления машинного обучения Azure
Вычислительные ресурсы машинного обучения Azure являются частью службы машинного обучения Azure, где мы предоставляем полный набор услуг для машинного обучения. Такие сервисы, как записная книжка, эксперименты, конвейер и инструменты мониторинга. В документации Azure для вычислений машинного обучения основные преимущества использования вычислительного экземпляра хорошо объяснены, и мы не будем подробно останавливаться на этом в этом разделе.
Упрощенная история конвейера в Azure ML Compute может выглядеть следующим образом:
- Получить данные из места хранения, можно в контейнере в Учетной записи хранения Azure.
- Подготовьте набор данных
- Обработка данных
- Переместите вывод в специальный контейнер для выходов.

Здесь у вас могут быть вычислительные экземпляры или вычислительный кластер. Они будут предоставлены ML Compute по запросу, загрузят задание, выполнят его, а затем уничтожат вычислительную мощность.
Примечание. Конвейер вычислений машинного обучения может иметь Azure Databricks в качестве вычислительной цели t.
Теперь, когда мы обсудили три платформы на очень высоком уровне, давайте перейдем к сравнению с разных сторон. После этого вы сможете выбрать наиболее подходящую платформу для своего проекта.
Основная цель
Azure Databricks
Вычислительная платформа для масштабирования данных и потоковой обработки данных, где требуется избыточность данных. Он объединяет общий набор библиотек DataBrick для анализа данных, машинного обучения, обработки данных (с Dataframe и SparkSQL).
Пакетная служба Azure
Запуск приложений для высокопроизводительных вычислений (HPC), в которые инженеры приносят свои собственные библиотеки и инструменты для параллельного выполнения больших заданий.
Вычисления машинного обучения Azure
Azure ML Compute включает в себя необходимые инструменты и библиотеки, предназначенные для машинного обучения. Он упакован как часть службы машинного обучения Azure.
Поддерживаемые языки
Azure Databricks
Databricks поддерживает несколько языков, что упрощает работу. Поддерживаемые языки - Python, Scala, R, SQL и Java.
Пакетная служба Azure
Использует следующие пакеты SDK Azure для запуска и управления рабочими нагрузками пакетной службы Azure - REST, .NET, Python, Node и Java.
Сама задача может быть написана на любом языке, если она исполняемая и зависимости доступны в узле.
Вычисления машинного обучения Azure
Поддерживаемые языки: Python и R.
Расходы
Azure Databricks
Цены на Azure Databricks немного отличаются от двух других платформ. Это означает, что помимо виртуальных машин, пользователь должен заплатить еще одну стоимость за Databricks Units (DBU).
Пакетная служба Azure
Пакетная учетная запись бесплатна и изменяется в зависимости от количества виртуальных машин в пуле и размера виртуальной машины. Его можно рассматривать как недорогой и универсальный вариант вычислений. Эта опция предоставляет низкоприоритетные виртуальные машины для выполнения пакетных рабочих нагрузок, что снижает стоимость.
Вычисления машинного обучения Azure
На основе экземпляра ВМ. Стоимость различных виртуальных машин указана на сайте Azure. Эта опция также предоставляет низкоприоритетные виртуальные машины, которые могут снизить стоимость еще больше.
Поддержка CI / CD
Azure Databricks
CI / CD полностью поддерживается Azure Databricks. Настройки могут быть разными в зависимости от требований проекта. Вот ссылка на обзор типичного CI / CD в Azure Databricks.
Пакетная служба Azure
Пакетная служба Azure также поддерживает CI / CD. Вот ссылка на статью, в которой объясняются шаги по его настройке. Однако по сравнению с двумя другими методами этот относительно сложнее настроить.
Вычисления машинного обучения Azure
CI / CD полностью поддерживается через Операции машинного обучения (MLOps), основанные на DevOps.
Тестовая поддержка
Azure Databricks
Тестирование полностью поддерживается Azure Databricks. Есть разные способы добавить тестовую среду. Например, Nutter упростил тестирование Azure Databricks.
Пакетная служба Azure
Так как сама задача может быть написана на любом языке, отдельно для каждой может быть свой тест, модуль / интеграция, реализованный в приложении. Таким образом, не требуются простые и многократные проводки.
Вычисления машинного обучения Azure
Цели развертывания в Azure ML Compute имеют свои собственные системы тестирования и отладки.
Минимальное количество требуемых узлов
Azure Databricks
Databricks работает таким образом, что есть главный узел и рабочие узлы "один ко многим". Следовательно, минимальное количество узлов, необходимое для этого, - два узла. Мы видим, что Databricks могут быть очень дорогими для небольших процессов.
Пакетная служба Azure
Для запуска пакетной службы Azure требуется минимум один узел.
Вычисления машинного обучения Azure
Для работы вычислений машинного обучения Azure требуется минимум один узел.
Интеграция Azure Data Lake Storage (ADLS) Gen2
Azure Databricks
Возможность подключения учетной записи Azure Data Lake Storage Gen2 к файловой системе Databricks (DBFS) с аутентификацией с использованием принципала службы и OAuth 2.0. Монтирование - это указатель на хранилище озера данных, поэтому данные никогда не синхронизируются локально.
Пакетная служба Azure
Пакетная служба Azure включает встроенную поддержку доступа к хранилищу BLOB-объектов Azure, и задачи могут загружать файлы на вычислительные узлы во время выполнения задач. Более подробную информацию о поддерживаемых Azure Batch учетных записях хранения можно найти в документации Azure.
Вычисления машинного обучения Azure
Поддерживает несколько типов хранилищ данных, включая ADLS Gen 2, в качестве хранилища данных для вычислений машинного обучения.
Возможность планирования
Azure Databricks
Azure Databricks имеет встроенные возможности планирования заданий. Фабрика данных Azure может вызывать преобразование Databricks.
Пакетная служба Azure
Он имеет те же возможности, что и Azure Databricks, собственные возможности планирования заданий. Фабрика данных Azure может вызывать пакетную службу Azure.
Вычисления машинного обучения Azure
Как и два других, это встроенные возможности планирования заданий.
Обработка паркетного файла
Azure Databricks
Parquet - это формат файла Apache, который изначально поддерживается Azure Databricks.
Пакетная служба Azure
Не поддерживается напрямую. Однако об этом можно позаботиться в приложении до запуска заданий в пакетном режиме Azure.
Вычисления машинного обучения Azure
Он поддерживает табличные наборы данных, следовательно, поддерживает паркетные файлы.
Автоматическое масштабирование
Azure Databricks
Поддерживает автомасштабирование. Это зависит от того, как вы определяете размер кластера, он может быть фиксированным или иметь минимальное и максимальное количество узлов.
Пакетная служба Azure
Поддерживает автомасштабирование. Его можно определить для динамического назначения узлов.
Вычисления машинного обучения Azure
Поддерживает автомасштабирование. В момент создания кластера вы можете определить минимальное и максимальное количество узлов. По умолчанию он имеет 0 узлов для минимального значения и 4 узла для максимального количества узлов.
Возможность развертывания в выделенной виртуальной сети
Azure Databricks
Поддерживает это за счет того, что все выделенные ресурсы, включая виртуальную сеть (Vnet), заблокированы в группе ресурсов, которая используется всеми кластерами.
Пакетная служба Azure
Поддерживает его, выделяя пул в подсеть, которая находится в выделенной виртуальной сети.
Вычисления машинного обучения Azure
Поддерживает это, выполняя задания в выделенном Vnet.