
Для того, чтобы получить здоровое и правильное понимание ваших данных, вам необходимо практическое знание статистики.
Центральная предельная теорема — одна из таких важных концепций, которая формулирует самые основы всей статистики и позволяет глубже погрузиться в нее. Я надеюсь, что у вас есть основные предварительные условия, такие как распределение данных, вероятности и т. д., прежде чем читать эту статью.
Прежде всего, формальное определение CLT гласит, что выборочное распределение выборочных средних следует нормальному распределению, а среднее выборочного распределения средних приближается к среднему значению генеральной совокупности, а дисперсия выборочного распределения средних значений обратно пропорциональна размеру выборки при условии, что совокупность исключена. из которых получена выборка, имеет определенное среднее значение и стандартное отклонение. Что ж, иногда это определение может быть пугающим, мы постараемся упростить его, и по мере продвижения вперед оно станет более интуитивным.
Итак, чтобы получить более неформальный и интуитивный смысл, давайте определим популяцию, поскольку мы имеем дело с популяцией, лучше взять довольно большой набор случайных величин и их частот, и чтобы быть более уверенным, мы возьмем распределение популяции к быть не нормально распределенным, а настолько случайным, насколько это возможно.

Мы создаем набор случайных данных, используя библиотеку random, и строим распределение, используя distplot с диапазоном значений населения от 1 до 10000, используя randint, мы можем ожидать, что значения будут повторяться, учитывая, что население представляет собой довольно большое число.

Приведенные выше данные не являются нормальными ни в каком смысле. На самом деле он мультимодальный. В следующих нескольких шагах мы докажем, что если мы возьмем достаточное количество точек данных в нашей выборке, по крайней мере, 30 из любого случайного распределения, которое имеет определенное среднее значение и дисперсию, и проведем n испытаний, среднее значение этих выборок начнет следовать нормальному распределению и будет стремиться быть более нормальным по своей природе, поскольку мы делаем больше испытаний и меньше точек данных в выборке, это то, что говорит центральная предельная теорема.
В интуитивном смысле мы можем представить, что распределение данных может повлиять на случайный выбор точек данных в выборке, чем выше частота или вероятность того, что конкретное число будет выбрано в нашей выборке, поэтому мы можем ожидать что, если число имеет высокую частоту появления, более вероятно, что оно появится в нашем наборе выборочных данных, и это сходится к идее, что этот набор выборочных данных является хорошим приближением того, как наше население распределено, и независимо от того, как ваши данные распределение среднего значения выборочных наборов данных с большей вероятностью будет собираться вокруг среднего значения совокупности из-за того факта, что среднее значение в неформальном смысле - это то, к чему вы ожидаете, что большинство ваших значений приблизится, хотя это может быть не так во всех случаях. времена, но если вы внимательно читаете между строк определения CLT, оно создано таким образом. Это причина, по которой нормальное распределение всегда проявляется в реальной жизни, будь то отметки учеников в классе или рост людей каждый раз, когда вы визуализируете любое распределение, с которым вы, скорее всего, столкнетесь с выборкой, а не со всем населением.
«Так что быть посредственностью — это совершенно нормально :-)»
Итак, вот функция, которая принимает количество испытаний и размер выборки, вычисляет среднее значение каждой выборки и делает это для указанного количества испытаний и возвращает набор данных среднего значения всех выборок.

Таким образом, вычерчивая среднее значение выборок, мы получаем нормальную кривую, и по мере увеличения количества точек данных в выборке и количества испытаний кривая становится более нормальной.
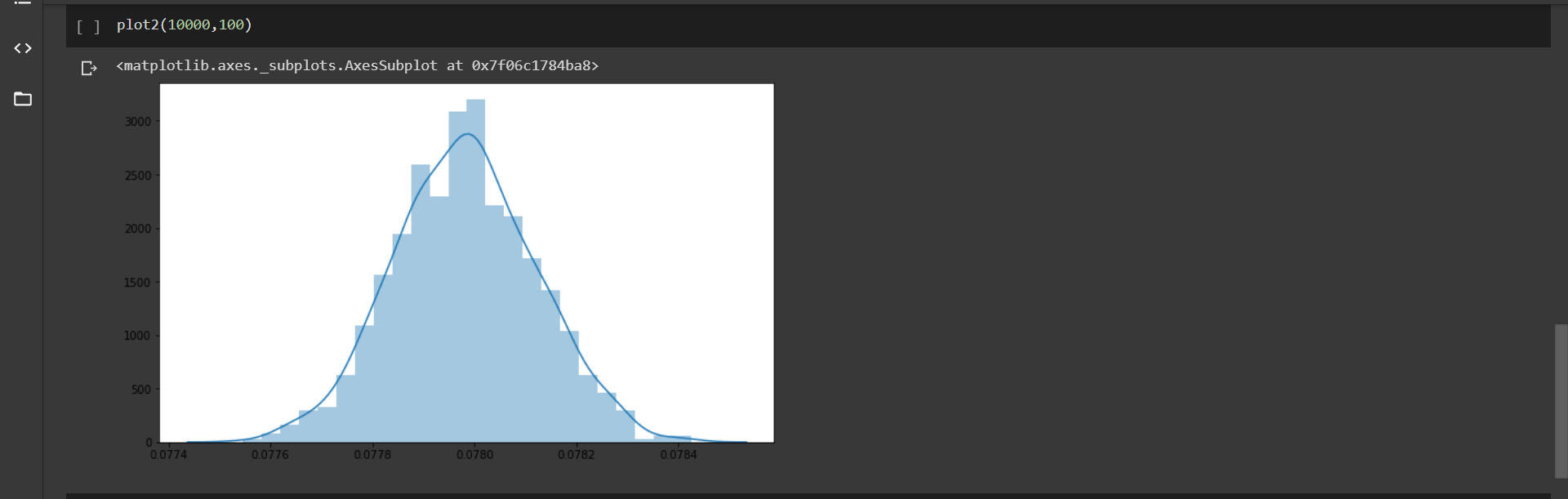
Помимо следования нормальному распределению, набор данных среднего значения выборок имеет среднее значение, близкое к среднему значению генеральной совокупности.

Стандартное отклонение нашего набора данных среднего значения выборок также может быть аппроксимировано как стандартное отклонение совокупности, деленное на квадратный корень из количества точек данных в каждой выборке.

Вы можете сами убедиться в этом, запустив двухстрочный код, а также по мере увеличения количества испытаний он более строго следует нормальной асимметрии и эксцессу.