
В серии графических процессоров RTX появилась возможность использовать высокоскоростное соединение между графическими процессорами NVLink в пользовательском сегменте. С тех пор, как я увидел эту новость, я не мог не думать о том, чтобы ее получить. У меня было слишком много вопросов о некоторых функциях и производительности этой технологии. Можно ли использовать удаленные атомарные операции? Где кэшируются удаленные доступы? Как должно выглядеть общение через NVLink, если между графическими процессорами нет прямого соединения?
К тому времени, как я получил ответы на эти вопросы, я понял, что мне нужно систематизировать свои знания программирования на нескольких GPU в целом. Этот пост - попытка сделать это. Поэтому я выделю некоторые общие принципы программирования с использованием нескольких графических процессоров, прежде чем углубляться в детали коммуникации.
Основы программирования на нескольких GPU
Избегайте поддержки нескольких графических процессоров
Прежде всего, почему и когда вам нужно тратить свое время на поддержку нескольких графических процессоров? Нет причин тратить ваше время, если вам не нужно ускорять конкретный экземпляр вашего приложения. Еще одна причина для программирования с несколькими графическими процессорами - это ограничения памяти. Если отдельный экземпляр приложения не помещается в память одного графического процессора, это случай программирования для нескольких графических процессоров.
Другими словами, если у вас есть набор относительно небольших задач, вам лучше запускать их независимо на разных графических процессорах. Для запуска нескольких экземпляров приложения с одним графическим процессором на разных графических процессорах вы можете использовать переменную среды CUDA CUDA_ VISIBLE_ DEVICES. Переменная ограничивает выполнение определенным набором устройств. Чтобы использовать его, просто установите CUDA_ VISIBLE_ DEVICES в список идентификаторов GPU, разделенных запятыми. Для этого я написал вспомогательный сценарий.
Он запускает исполняемый файл на нескольких графических процессорах с разными входами. Хотя я использовал CUDA_ VISIBLE_ DEVICES, чтобы избежать программирования с несколькими GPU, его можно было использовать для облегчения этого. Приложению с поддержкой нескольких графических процессоров может потребоваться эта переменная, если оно не поддерживает топологии с частичным подключением. С помощью CUDA_VISIBLE_ DEVICES можно ограничить выполнение графическими процессорами, подключенными к NVLink. Я расскажу вам, почему это так важно, позже.
Потратьте время на оптимизацию до поддержки нескольких графических процессоров
В этой части я хотел бы показать, что можно добиться такого же повышения производительности за счет оптимизации кода вместо поддержки нескольких GPU. Результат такой оптимизации выгоден как для сред с несколькими, так и с одним графическим процессором. Чтобы продемонстрировать свою точку зрения, я начну с простой задачи обработки изображений. Нам дается изображение в градациях серого, которое мы должны изменить, разделив значение каждого пикселя на некоторое число.

Начнем с простого ядра. Я присвоил каждому потоку один пиксель. Хотя этот код работает лучше, чем код многопоточного процессора, он далек от оптимального. Это позволяет использовать лишь небольшую часть памяти. Здесь нет смысла тратить время на поддержку нескольких графических процессоров. Вместо этого давайте попробуем его оптимизировать.
Чтобы улучшить использование памяти, я назначил несколько последовательных пикселей одному потоку и изображению площадки, чтобы упростить проверки. Благодаря этим изменениям новое ядро полностью использовало память. Он более чем в два раза быстрее предыдущего.
Уверяю вас, что оптимизация зачастую проще, чем поддержка нескольких графических процессоров. Кроме того, вы будете знать, чего ожидать от дальнейшей оптимизации, определив узкие места в вашем коде. На этом этапе производительность оптимизированной версии ограничена пропускной способностью памяти графического процессора. Самое время переключиться на несколько графических процессоров.
Написание приложения с несколькими GPU
Самый простой способ ускорить выполнение предыдущей задачи в среде с несколькими графическими процессорами - разделить изображение на части. Назначив каждый фрагмент другому графическому процессору, мы сможем ускорить обработку. Этот метод называется декомпозицией домена.

С точки зрения программирования, существуют разные способы использования нескольких графических процессоров. Мы начнем с самого простого, чтобы показать, как эта простота влияет на производительность. Однако большая часть дальнейшего описания характерна для любой модели.
Как вы могли заметить, в CUDA API нет такого параметра, как идентификатор графического процессора. Для запуска ядер, передачи данных, создания потоков, создания и записи событий этого не требуется. Это из-за дизайна API CUDA, который подразумевает концепцию текущего графического процессора. Все вызовы CUDA API выполняются в текущем графическом процессоре. Можно изменить текущий графический процессор с помощью вызова функции cudaSetDevice, которая получает идентификатор графического процессора. Идентификаторы графических процессоров всегда находятся в диапазоне [0, количество графических процессоров). Вы можете получить количество графических процессоров с помощью cudaGetDeviceCount.
Как вы знаете, вызовы ядра и функции асинхронного копирования памяти не блокируют поток ЦП. Поэтому они не блокируют переключение графических процессоров. Вы можете отправить столько неблокирующих вызовов в очередь GPU, сколько захотите, а затем переключиться на другой GPU. Вызовы к следующему графическому процессору будут выполняться одновременно со всеми остальными.
Например, представьте, что мы хотим отправить кусок нашего изображения на графический процессор, обработать его, получить результат и переключиться на другой графический процессор. Я намеренно использовал инструкции по блокировке, чтобы показать результат неправильного использования CUDA API в среде с несколькими графическими процессорами.
Приведенный выше код не обеспечивает улучшения производительности по сравнению с одним графическим процессором. Причина такого поведения представлена ниже. Поток просто не ставит в очередь дальнейшие вызовы, пока не завершит блокировку вызовов cudaMemcpy.

Очевидное решение этой проблемы - использовать cudaMemcpyAsync вместо cudaMemcpy. К сожалению, это не решит проблему. Асинхронная версия cudaMemcpy является асинхронной по отношению к потоку ЦП. Существует множество ограничений, которые могут заставить среду выполнения CUDA использовать блокирующую версию cudaMemcpy внутри. Один из них - требование закрепления памяти хоста. Из приведенного выше профилирования видно, что я использовал страничную память. Хотя вызов cudaMemcpyAsync не блокирует поток ЦП, с точки зрения времени выполнения CUDA нет никакой разницы между использованием cudaMemcpy и cudaMemcpyAsync в выгружаемой памяти. Использование закрепленной памяти с помощью cudaMemcpyAsync позволяет выполнять cudaSetDevice без блокировки очереди второго графического процессора. Результат обсуждаемых изменений представлен ниже. Обратите внимание, что копирование памяти здесь только для того, чтобы проиллюстрировать проблемы однопоточного программирования с несколькими GPU. Я скоро избавлюсь от них.

Еще одна важная вещь, которую следует отметить, - это то, что потоки и события CUDA рассчитаны на каждый графический процессор. Вызовы к потоку могут быть выполнены только при текущем GPU. У каждого графического процессора есть собственный поток по умолчанию. Это ясно из приведенного выше профилирования. Я вызвал ядра и операции с памятью, используя поток по умолчанию обоих графических процессоров. Если бы поток по умолчанию был один на процесс, я бы наблюдал некоторую сериализацию.
Хотя событие может быть записано только в том случае, если его графический процессор является текущим, его можно запрашивать и синхронизировать, когда другой графический процессор является текущим. Эта функция широко используется для синхронизации с графическим процессором. Оно нам понадобится позже.
На данный момент этой информации должно быть достаточно, чтобы перейти к следующей функции. Чтобы продемонстрировать это, я извлек дорогостоящие передачи вне цикла вызова ядра. Прежде чем рассматривать эту функцию, давайте подумаем о производительности при запуске с несколькими графическими процессорами. Хотя не всегда ясно, какого ускорения следует ожидать от графического процессора, с корпусом с несколькими графическими процессорами все становится проще. Время выполнения для ядра выше примерно 0,026 с на моем RTX 2080 для изображения 8000x6000. Я ожидал, что мой код для нескольких графических процессоров будет завершен за половину этого времени (0,013 с). К сожалению, код получается медленнее, чем ожидалось - 0,015 с. Это число соответствует эффективности 86%. Но почему? Чтобы ответить на этот вопрос, необходимы системы NVIDIA Nsight. Профилирование показывает нам, что наши ядра начинаются с огромного пробела. Эта потеря производительности является результатом переключения графического процессора в одном потоке ЦП.

Чтобы решить эту проблему, нам нужно отказаться от модели программирования с одним потоком и несколькими графическими процессорами. Давайте назначим каждому графическому процессору отдельный поток. Делая это, мы движемся к модели программирования с несколькими потоками и несколькими GPU. Кроме того, я написал оболочку для блока, чтобы уменьшить лишний код и собрать данные для каждого графического процессора в одном объекте. Вызов функции запуска просто записывает события для измерения времени и вызывает ядро. Вызов функции синхронизации синхронизируется с записанным событием.
Новая модель программирования с несколькими графическими процессорами работает отлично. Истекшее время для приведенного выше кода близко к ожидаемым значениям (0,013 с). Значение соответствует 100% эффективности работы с несколькими GPU.

На этом этапе мы обсудили наиболее важные особенности программирования с несколькими графическими процессорами для простого случая независимых ядер. Обсуждаемые изменения обеспечили 100% -ное использование системы с несколькими графическими процессорами. Тем не менее, во многих приложениях невозможно избежать обмена данными между графическими процессорами. Например, явные численные алгоритмы решения уравнений в частных производных требуют доступа к соседним ячейкам. Техника декомпозиции доменов подразумевает, что некоторые соседние ячейки хранятся в памяти другого графического процессора. Чтобы вычислить граничные ячейки текущего графического процессора, их соседи должны быть получены из памяти других графических процессоров. Другой пример - решатели линейных систем. В решении линейных систем часто используются коллективные коммуникации, такие как редукция.
Как вы понимаете, мы приближаемся к самому интересному - multi-GPU коммуникациям. Прежде чем погрузиться в код, я опишу технологии, которые используются для связи между графическими процессорами.
Связь с несколькими GPU
Большинство алгоритмов, на результат которых влияют результаты других графических процессоров, требуют связи с несколькими графическими процессорами. Часто можно переписать задачу с несколькими графическими процессорами как последовательность независимых задач, выполняемых на нескольких графических процессорах, за которыми следует коллективное взаимодействие. Например, вы можете выполнить сложный алгоритм сжатия на каждом графическом процессоре. После этого вы можете использовать примитив связи all-gather, чтобы собрать результаты друг друга. Если ваша задача подходит для этой схемы, вам может быть интересна библиотека коллективных коммуникаций NVIDIA (NCCL). NCCL предоставляет примитивы коллективной связи с несколькими GPU и многоузловыми топологиями. Вы можете найти оптимизированные версии многих примитивов, таких как all-gather, all-reduce, broadcast, reduce и reduce-scatter. Если вас не устраивает производительность извлечения сообщений, вам нужно понимать лежащие в основе технологии, чтобы писать эффективные программы с несколькими GPU. В этом случае следующий материал для вас.
Существует множество способов передачи данных. Например, данные могут передаваться между графическими процессорами через буфер памяти хоста. Хотя это самый медленный из возможных способов, я опишу его, чтобы продемонстрировать некоторые функции программирования с несколькими графическими процессорами.
PCIe
Если вы не являетесь пользователем Summit, для передачи данных между хостом и устройством используется PCIe (Peripheral-Component-Interconnect-Express-Bus). PCIe - это стандарт высокоскоростной последовательной шины. Соединение PCIe состоит из одной или нескольких полос. Каждая полоса состоит из двух пар проводов, одна для приема, а другая для передачи. Возможно, вы заметили метки x1, x4, x8, x16 в выводе nvidia-smi -q (PCI - Информация о ссылке на GPU - Ширина канала). Эти числа представляют количество линий PCIe. Пропускная способность линейно масштабируется в зависимости от количества ссылок. Одна линия PCIe 3.0 имеет пропускную способность, равную 985 МБ / с. В режиме x16 он должен обеспечивать 15 ГБ / с.

Тест пропускной способности на моей конфигурации показывает 13 ГБ / с. Как вы могли заметить из результатов профилирования выше, передача данных на мой второй графический процессор заняла гораздо больше времени. Причина в том, что второй GPU связан с PCIe x4. Это дает мне 3,3 ГБ / с для второго графического процессора (ожидаемое замедление).

Важно помнить приблизительное положение точек насыщения. Это около 512 КБ для первого GPU и 128 КБ для второго. Как использовать эти числа? Во-первых, если у вас много мелких транзакций, вы не перегружаете шину PCIe. Например, если у вас есть 512 сообщений размером 1 КБ, лучше собрать их и отправить как одну транзакцию размером 512 КБ. Чтобы измерить разницу, вы можете запустить приведенный ниже код. На моей машине пакетная отправка 512 КБ выполняется в 130 раз быстрее.
Теперь давайте попробуем скопировать данные между двумя графическими процессорами, используя центральный процессор в качестве промежуточного. Чтобы скопировать данные с одного графического процессора на другой через процессор с шиной PCIe, достаточно вызвать функцию cudaMemcpy с флагом cudaMemcpyDeviceToDevice. Важно отметить, что копирование между памятью разных графических процессоров не запускается до тех пор, пока не будут выполнены все команды, ранее выданные любому графическому процессору. Кроме того, команды в любом из графических процессоров не могут быть запущены, пока не завершится копирование между ними, отправленное в поток по умолчанию. Другими словами, поток по умолчанию расширяет семантику синхронизации на случай нескольких GPU.
Можно использовать указатели на память другого графического процессора благодаря Унифицированной виртуальной адресации (UVA). UVA поддерживается только в 64-битных процессах. UVA поддерживает единое виртуальное адресное пространство для всех устройств и память хоста, выделенную с помощью CUDA API. Это позволяет CUDA API определить реальное устройство, просто взглянув на указатель.
Интересно, что вы также можете определить устройство по указателю. Для этого вам нужно вызвать cudaPointerGetAttributes. Вот вспомогательная функция для этой цели.
Если поддерживается UVA (т.е. ваш код находится в 64-битном приложении), вы можете забыть об указании типа передачи памяти и везде использовать cudaMemcpyDefault. Это также работает для указателей хоста, не выделенных через CUDA. По какой-то причине UVA изображается как непрерывные диапазоны виртуальных адресов для каждого устройства. Если бы это было так, можно было бы реализовать cudaPointerGetAttributes как средство проверки диапазона. Ясно, что это не может быть правдой. Чтобы проверить это, вы можете запустить приведенный ниже код.
Если вы запустите код, вы увидите картинку с рисунка ниже. Блок виртуальных адресов не назначается конкретному графическому процессору.

Для дальнейших примеров требуется поддержка UVA. Если вам нужно работать с 32-битными приложениями, для вас есть явные функции. Такие функции, как cudaMemcpyPeer и cudaMemcpyPeerAsync, имеют дополнительные аргументы, указывающие идентификаторы исходного и целевого графического процессора. Для их использования не требуется UVA.
Результаты копирования данных через CPU могут быть значительно улучшены. На рисунке ниже показано, что плато пропускной способности достигается гораздо дальше, чем в случае передачи на второй графический процессор. К счастью, есть способ исключить CPU из передач GPU-GPU.

Выбрасывание CPU из передач памяти GPU-GPU
Если несколько графических процессоров подключены к одной и той же иерархии PCIe, можно избежать использования процессора в предыдущей схеме. Давайте посмотрим на пример топологии PCI, которая позволяет осуществлять прямую передачу данных между некоторыми графическими процессорами. На изображении ниже вы можете увидеть упрощенную версию топологии PCI станции DGX-2. Топология состоит из двух деревьев PCIe, соединенных друг с другом с помощью QPI.
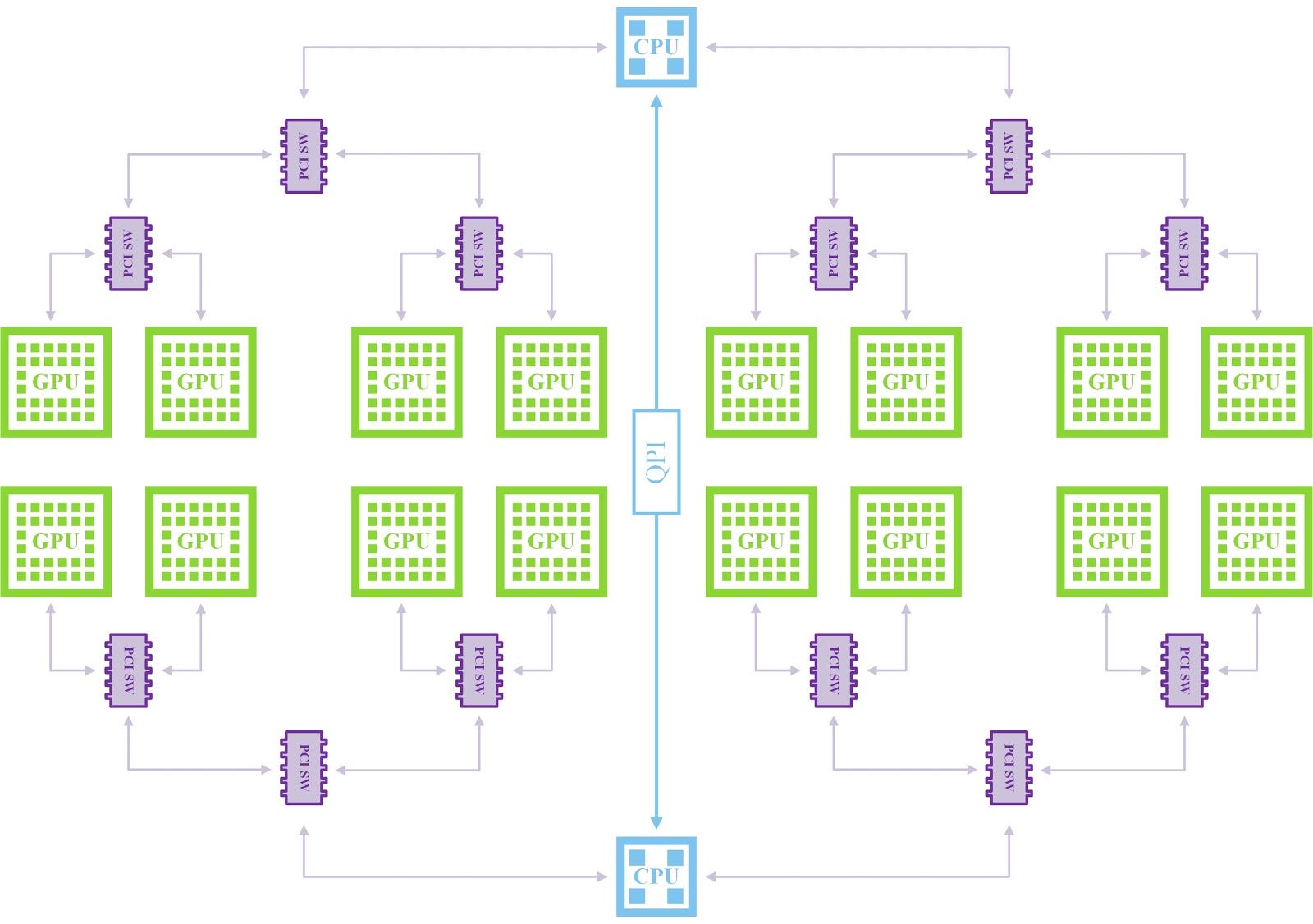
Судя по всему, привязка GPU к потоку с другого узла NUMA приводит к трафику QPI. Если вы не можете извлечь трафик хост-устройство из горячего пути вашего приложения, есть хорошие новости. Можно разделить графические процессоры в зависимости от наилучшего соответствия ЦП (nvmlDeviceGetCpuAffinity) или привязать поток к наиболее подходящему узлу NUMA (nvmlDeviceSetCpuAffinity). Эти функции предоставляются NVIDIA Management Library (NVML) и работают только в системах Linux. К сожалению, невозможно полностью избежать эффектов NUMA при передаче GPU-GPU, потому что один из GPU может иметь другое сродство. Чтобы избежать этой головной боли и обсудить ускорение, лучше исключить CPU из передач GPU-GPU. Для этого PCIe имеет достойную поддержку для выполнения прямого доступа к памяти (DMA) между двумя устройствами на шине. Согласно спецификации PCI любое устройство PCI может инициировать транзакцию, поэтому в некоторых случаях нам здесь не нужен ЦП. Поэтому тип транзакции называется одноранговой (P2P).
Одноранговый доступ к памяти
В зависимости от свойств системы устройства могут обращаться к памяти друг друга без необходимости использования основной памяти в качестве временного хранилища или использования ЦП для перемещения данных. P2P-коммуникации PCIe значительно сокращают задержку связи. Например, ядро может разыменовать указатель на память другого устройства. Для этого должен быть включен P2P-доступ между графическими процессорами. Позже в этом посте мы будем использовать ядра, которые разыменовывают указатели удаленной памяти. А пока я больше сосредоточусь на функции DMA P2P-транзакций с точки зрения функций копирования памяти.
Самая большая проблема со спецификацией PCI заключается в том, что она не требует пересылки транзакций между доменами иерархии. В PCIe каждый корневой порт определяет отдельный домен иерархии. P2P поддерживается только в том случае, если все задействованные конечные точки находятся за одним и тем же доменом иерархии PCI. CUDA предоставляет функцию cudaDeviceCanAccessPeer для проверки наличия доступа P2P между двумя графическими процессорами. CUDA API не отличает PCIe от NVLink P2P, поэтому cudaDeviceCanAccessPeer возвращает true, если два графических процессора не принадлежат одному домену PCIe, но могут обращаться друг к другу через NVLink.
Если P2P-доступ доступен между двумя графическими процессорами, это не означает, что он используется. Сопоставление выделений с целевым графическим процессором требуется для обеспечения доступа P2P к текущему графическому процессору. Для этого есть два возможных пути. Самый простой способ - вызвать cudaDeviceEnablePeerAccess. Это просто, потому что это позволяет получить доступ ко всем предыдущим выделениям на текущем графическом процессоре для целевого графического процессора. Более того, он заставляет все будущие выделения также сопоставляться с целевым графическим процессором. В приведенном ниже коде показан простой случай копирования с поддержкой P2P между двумя графическими процессорами.
Руководство по программированию NVIDIA заявляет, что в системах без поддержки NVSwitch каждое устройство может поддерживать до восьми одноранговых соединений в масштабе всей системы.
Хотя с cudaDeviceEnablePeerAccess довольно легко разрабатывать программы для нескольких GPU, это может вызвать некоторые проблемы. Основная проблема - потеря производительности при выделении памяти. Сложность выполнения вызова cudaMalloc составляет около O (lg (n)), где N - количество предшествующих выделений на текущем графическом процессоре. После вызова cudaDeviceEnablePeerAccess cudaMalloc должен сопоставить свои выделения со всеми устройствами с включенным одноранговым доступом. Этот факт изменяет сложность cudaMalloc на O (D * lg (N)), где D - количество устройств с одноранговым доступом. Вы можете проверить разницу во времени с помощью кода ниже. На моей машине с двумя графическими процессорами у меня было 0,23 секунды после включения однорангового доступа вместо 0,1 секунды без него.
Помимо проблем с производительностью, лучше иметь строгий контроль над доступом к памяти между графическими процессорами. Я хотел бы получить ошибку времени выполнения в случае доступа к памяти, который не подразумевался как P2P.
Обе проблемы могут быть решены с помощью нового великолепного API для низкоуровневого управления виртуальной памятью. API был представлен в CUDA 10.2. Он включает функции cuMemCreate, cuMemAddressReserve, cuMemMap и cuMemSetAccess для выделения физической памяти, резервирования диапазона виртуальных адресов, отображения памяти и управления доступом соответственно. Эти функции могут использоваться одновременно с функциями времени выполнения CUDA. Я создал несколько оболочек RAII для этих функций, чтобы не тратить ваше время на эту тему. Остановлюсь только на контроле доступа. В приведенном ниже коде показан новый интерфейс для управления доступом. Как видите, это для каждого сопоставления. Поэтому нам больше не нужно использовать cudaDeviceEnablePeerAccess. Теперь можно разрешить P2P доступ к определенной памяти. Более того, для некоторых графических процессоров можно предоставить доступ только для чтения.
Кроме того, теперь можно выделить физическую память для каждого графического процессора и сопоставить ее с непрерывным диапазоном виртуальных адресов. Одним из вариантов использования этой функции может быть умножение разреженной матрицы на вектор для нескольких GPU. В предыдущем API мы были ограничены двумя подходами. Первым способом его реализации было хранение всего вектора на всех устройствах. Второй способ заключался в сжатии добавленных строк в памяти. Теперь можно выделить отдельные части вектора для каждого графического процессора, сопоставить их с одним диапазоном виртуальных адресов и получить доступ к удаленной памяти без каких-либо различий в коде.
Я не буду останавливаться на достигнутом, чтобы показать результаты тестов для PCIe P2P, потому что впереди нас ждет кое-что более интересное. Достаточно сказать, что в обсуждаемой конфигурации пропускная способность между устройствами была ограничена вторым графическим процессором и равнялась 3,3 ГБ / с. Немного. К счастью, в моей конфигурации есть NVLink.
NVLink
NVLink - это общее название семейства скоростных мостов. NVLink поддерживает соединение CPU-GPU или GPU-GPU. Он двунаправленный, поэтому каждая ссылка состоит из двух вложенных ссылок - по одной для каждого направления. Каждая подссылка дополнительно содержит восемь полос. NVLink можно рассматривать как кабель с двумя заглушками. Графический процессор включает в себя несколько слотов NVLink. Несколько кабелей можно использовать вместе для увеличения пропускной способности за счет соединения одних и тех же конечных точек. В этом случае полоса пропускания линейно масштабируется. Например, графический процессор Pascal-P100 имеет четыре слота NVLink. Таким образом, можно подключить два графических процессора с четырьмя каналами NVLink, чтобы получить пропускную способность в 4 раза по сравнению с одним каналом. С другой стороны, эти слоты можно использовать для создания сложных топологий для соединения большего количества графических процессоров.
Еще одна полезная функция - поддержка атомарных операций. Но, конечно же, главная особенность NVLink - это пропускная способность. Прежде чем углубляться в тесты, давайте познакомимся с членами семьи этих мостов.
Первый NVLink называется NVLink 1.0. Он используется в графических процессорах P100. Каждый NVLink обеспечивает пропускную способность около 20 ГБ / с в каждом направлении. Эта технология была улучшена во втором поколении NVLink - NVLink 2.0, которое увеличивает пропускную способность канала на 25% (25 ГБ / с в каждом направлении). Каждый графический процессор V100 имеет шесть слотов NVLink. И, наконец, архитектура Тьюринга включает в себя мост на базе NVLink-SLI - NVLink 2.0. Он может соединять два графических процессора с одним каналом NVLink 2.0. NVLink 3.0 был анонсирован недавно. Он должен удвоить пропускную способность NVLink 2.0 и обеспечить 50 ГБ / с на канал в каждом направлении. В этой статье я рассмотрю NVLink-SLI. Разница между пропускной способностью NVLink-SLI P2P и PCIe представлена на рисунке ниже.

Помимо более высокой пропускной способности, NVLink-SLI дает нам меньшую задержку, чем PCIe. Это примерно 1,3 микросекунды по сравнению с 13 микросекундами PCIe. Вы можете получить доступ к некоторым счетчикам производительности NVLink из своего кода. Для этого вам необходимо использовать API NVML. Интерфейс изменился в CUDA 11, поэтому я покажу вам две версии. Приведенный ниже код работает для любой версии CUDA до 11.
А вот версия для CUDA 11. Если вам не нужны такие подробные измерения, вы можете использовать nvidia-smi nvlink -gt d до и после запуска приложения.
Эти показатели могут дать вам интересную информацию. Я пытался понять цифры, которые мне дали, когда я понял, что atomicAdd для всего варпа фактически скомпилирован в __ballot_sync и по одной атомарной операции на деформацию (godbolt). Кстати, чтобы проверить, что NVLink действительно поддерживает атомарные операции, вы можете использовать приведенный ниже код. Здесь я передаю указатели на массивы на разных графических процессорах. В этом случае оба графических процессора работают с одними и теми же данными одновременно. После достаточного количества итераций полученные значения проверяются и сравниваются с ожидаемыми.
Он отвечает на вопрос, который я задал в начале этого поста. NVLink поддерживает удаленные атомарные операции. Пора перейти ко второму вопросу. Где кэшируются удаленные доступы? Что ж, измерить доступ к памяти всегда непросто. Нам нужно исключить все инструкции, которые не являются операциями с памятью. Для этого конкретного случая есть классический прием, который называется погоней за указателем.
Погоня за указателем включает в себя повторяющуюся серию нерегулярных обращений к памяти, которые требуют, чтобы данные, к которым осуществлялся доступ, определяли следующий адрес указателя, к которому необходимо получить доступ. В приведенном выше коде я передаю указатель на связанный список. Затем я перемещаю текущий указатель на следующий узел в списке 64 раза. Управляя перемещением узлов в памяти, я могу контролировать доступ к памяти и, следовательно, анализировать эффекты кэширования. Чтобы проанализировать эффекты кэширования, я запустил вышеприведенное ядро разными способами. Передав указатель на собственную память графического процессора, я смог измерить глобальную задержку памяти. Чтобы измерить задержку доступа к удаленной памяти через NVLink, я передал указатель на удаленную память. Из рисунка ниже видно, что задержка доступа к NVLink-SLI примерно равна двум доступам к глобальной памяти.

Здесь вы можете увидеть еще две строки. Прежде чем описывать их, мне нужно более подробно остановиться на архитектуре графического процессора. Наша цель - понять базовое оборудование. Первый шаг в этом путешествии состоит в понимании роли кэша L1 в операциях с памятью NVLink. Как вы знаете, кэш L1 находится в многопроцессорном потоковом режиме (SM). Чтобы показать, кэширует ли доступ через NVLink, я скомпилировал ядро выше с параметром -Xptxas -dlcm = cg. Параметр -dlcm обозначает модификатор загрузки кеша по умолчанию. Его значение по умолчанию - ca, что означает кэшировать на всех уровнях. Я использовал cg, что означает кэш на уровне L2 и ниже, а не на уровне L1. Также можно использовать "cv", что означает "не кэшировать и не получать при каждой загрузке". Снижение производительности с -dlcm = cg ясно указывает на то, что L1 используется с операциями памяти NVLink. На данный момент нет никакой разницы между чтением собственной памяти и чтением удаленной памяти через NVLink. Верно ли это для L2? Ну нет. Разница в L2-кеше весьма интересна. Данные фактически кэшируются в L2. Единственная разница в том, что это L2 другого графического процессора. Чтобы доказать, что я вызвал обсуждаемое ядро на втором GPU с собственной памятью. Затем я переключился на первый GPU и вызвал ядро в памяти второго GPU. Вы можете увидеть влияние этого теста на производительность на рисунке выше (NVLink после второй погони за графическим процессором).

Путь, по которому проходят данные при использовании NVLink, показан ниже. Интересно отметить, что NVLink не имеет автоматической маршрутизации. Если два графических процессора подключены к промежуточному графическому процессору, P2P не будет использоваться. Есть способ решить эту проблему. Вы можете запустить ядро маршрутизации на промежуточном графическом процессоре, чтобы облегчить передачу данных. В этом случае вы не будете тратить дополнительную память промежуточного графического процессора на буферы.
Знания об основной аппаратной архитектуре полезны для профилирования. Теперь вы можете оправдать увеличение пропусков L2 на удаленном графическом процессоре по сравнению с выполнением на одном графическом процессоре. К счастью, есть еще одно применение описанных знаний. Теперь, когда мы знаем точную задержку доступа к удаленной памяти, мы можем ее скрыть.

Скрытие задержки NVLink
Нагрузка на память не приводит к остановкам. Фактически, это дальнейшие инструкции, которые используют загруженные данные, которые могут быть остановлены из-за зависимости данных. Эта функция может использоваться для сокрытия длительной нагрузки на память. Чтобы скрыть задержку, нам нужно сделать что-то еще перед выдачей инструкции, которая зависит от загружаемых данных. К счастью, компилятор знает об этой возможности. В большинстве случаев ему удается переупорядочить загрузку памяти с выполнением инструкций для увеличения параллелизма на уровне инструкций (ILP). В приведенном ниже коде я добавил загрузку собственной памяти и некоторую арифметику. Управляя ILP, мы могли видеть, сколько инструкций может перекрываться удаленной загрузкой памяти.
Из приведенного ниже графика видно, что можно почти бесплатно перекрывать нагрузки на собственную память. Задержка ядра без чтения в собственную память текущего графического процессора составляет около 1290 циклов. Если вам не хватает ILP, это тоже нормально. Заявлено, что достаточное количество подходящих перекосов может скрыть 10% задержки доступа к удаленной памяти даже с PCIe.

Если в вашем случае этого недостаточно, вам необходимо продублировать удаленную память и выполнить массовые операции с памятью вне ядер. Но даже при таком подходе есть место для сокрытия задержки. Я проиллюстрирую удаленное дублирование памяти вместе с некоторыми дополнительными методами оптимизации на моделировании уравнений Максвелла.
Удаленное дублирование памяти
Уравнения Максвелла описывают эволюцию электрических и магнитных полей. Чтобы найти приближенное решение дифференциальных уравнений Максвелла, я использую метод конечных разностей во временной области (FDTD) или метод Йи. FDTD - это метод, основанный на сетке. Производительность методов на основе сетки обычно зависит от размера сетки. Само вычисление выглядит как цикл, вызывающий две функции, которые обновляют поля H и E в каждой ячейке сетки.
Чтобы обновить значение поля H в ячейке, необходимо значение поля H внутри ячейки вместе со значениями верхних и правых соседей ячейки. Функция, обновляющая поле E, выглядит примерно так же, за исключением того, что ей требуются значения из нижней и левой ячеек.
Вы можете увидеть результат моделирования на видео ниже. В этом видео я создал пример георадара с двумя объектами.
Поскольку я рассматриваю двумерный случай уравнений Максвелла, сетка очень похожа на изображение в оттенках серого. Мы уже знаем, как работать с изображениями в среде с несколькими графическими процессорами. Давайте применим технику декомпозиции домена для поддержки нескольких графических процессоров. Единственная проблема здесь заключается в том, что ячейкам нужны значения компонентов поля соседей, чтобы вычислить значение для следующего временного шага. Чтобы уменьшить трафик NVLink при вызове ядра, я создал слой ячеек вокруг собственных элементов блока сетки для каждого графического процессора.

Код ниже иллюстрирует основной цикл. Я применил все исправления, которые мы обсуждали ранее. Он выполняется несколькими потоками и использует связь P2P через NVLink. И, конечно, есть возможности для оптимизации.
Вы могли заметить, что я синхронизирую потоки с барьером перед выполнением следующего вызова ядра. Барьер необходим для задержки обновления поля E до завершения транзакции памяти. В противном случае ядро будет наблюдать частично обновленный фантомный слой. Синхронизация потоков после обновления поля E служит той же цели.
Пока все выглядит просто, но как насчет производительности? Если площадь контакта блоков сетки меньше другого измерения (например, высота сетки составляет 8000 ячеек, а ширина - около 4000), код работает с эффективностью 96%. Это связано с тем, что вычисление занимает большую часть времени. Но если мы изменим соотношение на противоположное, мы увидим что-то вроде 85% эффективности. Это неприемлемый результат. К счастью, эту задержку можно скрыть. Как и раньше, нам нужно совмещать передачу данных с вычислениями.
Перекрытие передачи данных с вычислением
Чтобы скрыть задержку передачи данных, нам нужно использовать потоки и события. Я полностью выделил перенос полей фантомного слоя в отдельный метод. Он вызывает cudaMemcpyAsync и записывает событие. Модифицированный основной цикл показан ниже.
Сейчас я выдаю ядро, которое вычисляет большую часть сетки, кроме ее границы. Затем я выдаю ядро, которое вычисляет границу в отдельном потоке. Тот же поток отвечает за передачу данных. Чтобы заставить среду выполнения CUDA выдавать передачи до завершения массового завершения ядра, я увеличил приоритет потоков передачи.
Часто лучше платить только за то, чем пользуетесь. Я использовал события только для синхронизации потоков. Как известно, по умолчанию события также фиксируют время. Для повышения производительности событий можно отключить тайминг.
Эта версия работает намного лучше - около 99% эффективности с двумя графическими процессорами. Из приведенного ниже профилирования видно, что копирование полностью перекрывается с вычислениями.

Тот же подход можно использовать в многоузловых системах. Можно отправлять пограничные ячейки с помощью MPI при вычислении остальной части сетки.
Кооперативные группы
Есть еще один подход, о котором я еще не упоминал. Модель программирования Cooperative Groups (CG) описывает шаблоны синхронизации как внутри, так и между блоками потоков CUDA. С помощью CG можно запустить одно ядро и синхронизировать все потоки графического процессора между различными этапами. Другими словами, CG расширяет __syncthreads до области графического процессора. Но что важно для нашей темы - ее можно расширить еще больше - до области мульти-GPU.
Вы можете увидеть интерфейс CG в ядре ниже. Я переписал симуляцию уравнений Максвелла так, чтобы она могла уместиться в одном ядре. После обновления полей H и E я синхронизирую все потоки графического процессора с методом синхронизации группы сетки. Чтобы распространить это на случай с несколькими графическими процессорами, было бы достаточно вызвать метод синхронизации многосеточной группы. Вы можете получить объект этого типа с помощью this_multi_grid ().
CG требует изменения запуска ядра. Ядро следует запускать с помощью cudaLaunchCooperativeKernel, чтобы использовать барьеры всей сетки. Чтобы использовать барьеры для нескольких графических процессоров, вам нужно вместо этого использовать cudaLaunchCooperativeKernelMultiDevice.
После этих изменений вы увидите в профилировщике единственный вызов ядра. Хотя эта технология довольно удобна с точки зрения программирования, вы должны четко понимать, когда ее следует использовать. Во-первых, очень много ограничений. Если вас это устраивает, задайте следующий вопрос - код быстрее с CG? Смотря как. Если у вас много маленьких ядер - вы можете получить прирост производительности. В случае обсуждаемого кода я получил улучшение примерно на 9% на малых сетках. У меня также было замедление на 40% на больших. Важно понимать, что нельзя использовать динамический параллелизм с запусками компьютерной графики. Если за маленькими ядрами последуют большие, будет сложно превзойти классический подход. Таким образом, в этом случае я бы предложил CUDA Graphs. Графики CUDA выходят за рамки этой публикации. Вместо них я хотел бы поделиться с вами последней техникой оптимизации с использованием нескольких графических процессоров.
Задержка обмена пропускной способностью
Вы помните точки насыщения на графиках пропускной способности? Мы могли бы воспользоваться тем фактом, что можно увеличить размер сообщения бесплатно, если новый размер ниже точки насыщения. Мы уже сделали это, выполнив пакетную отправку вместо нескольких небольших транзакций. На этот раз я кратко проиллюстрирую, как применить ту же технику к моделированию уравнений Максвелла.
Давайте посмотрим на текущее состояние кода с точки зрения обновления данных. Вначале у нас есть фактические значения в собственной части сетки. Призрачный слой находится в недопустимом состоянии.

Существует статья, в которой предлагается способ сокрытия задержки путем выполнения избыточных вычислений. Работа называется «Эффективное моделирование агентно-ориентированных моделей на многопроцессорных и многоядерных кластерах». Авторы добились более чем четырех порядков ускорения на многопроцессорных системах. Этот метод называется схемой скрытия задержки B + 2R. Он заключается в расширении фантомной части блока сетки с одного слоя на R. Расширяя призрачную часть слоями R, мы могли отложить переводы на шаги R. Эти шаги R можно вычислить без какой-либо синхронизации с разными графическими процессорами.

В некоторых крайних случаях этот метод превосходит копирование с перекрытием. Если вас интересует эта тема, вы можете проверить исходный код на github.
Заключение
Я хотел бы сказать, что программы с несколькими графическими процессорами представляют собой набор программ с одним графическим процессором только в простейшем случае независимых ядер. Во всех остальных случаях дело само по себе. Попробуйте сами программировать на нескольких GPU, и я желаю вам добиться 100% эффективности.