Как я использовал базовое НЛП, чтобы посмотреть, как пол соотносится с определенными предметами на Netflix.

Пару лет назад, когда я впервые познакомился с наукой о данных, меня поразила статья с данными под названием Она хихикает, он скачет », в которой анализировался гендерный аспект в направлении экрана в тысячах сценариев. Он специально идентифицировал все глаголы, следующие за он и она, чтобы исследовать гендерные тропы. Теперь, когда я узнал больше о науке о данных, я подумал, что могу попробовать применить аналогичный анализ к другому набору данных.
В настоящее время потоковые сервисы полностью захватили индустрию кино и телевидения. Они являются основным средством массовой информации для зрителей, и эти платформы формируют нашу культуру посредством фильмов, которые они выбирают для показа. Netflix, являющийся одним из крупнейших потоковых сервисов, имеет наибольшее влияние в этой области, поэтому я хотел взглянуть на гендерное представительство в его выборе.
В этой статье я собираюсь объяснить необходимую интуицию, лежащую в основе моего анализа, и продемонстрировать скелет кода, который ему соответствует. Если вы хотите получить доступ к полному коду или используемым наборам данных, вы можете найти их в моем репозитории Github для этого проекта.
Данные
Сторонняя поисковая система Netflix, Flixable, выпустила набор данных, в котором перечислены все фильмы и телешоу на Netflix по состоянию на 2019 год. Он предоставляет несколько различных атрибутов с названием, включая их состав и описание. С помощью этих двух атрибутов мы можем отслеживать тенденции в отношении пола (-ов) актеров и содержания фильма или телешоу. Для своего анализа я решил посмотреть на пол главного актера / актрисы.
Однако набор данных Flixable не включает пол актеров. Я не собираюсь маркировать все 6000+ записей вручную, поэтому мне помог IMDb, у которого есть несколько общедоступных наборов данных, которые обновляются ежедневно. Один из этих наборов данных подробно описывает имена актеров, актрис, писателей и т. Д. И их профессии. Учитывая актерский состав названия, я обнаружил, что могу сопоставить имена участников актерского состава с именами в наборе данных IMDb, посмотреть, помечены ли они как актер или актриса, и таким образом автоматизировать определение пола.
Прежде чем я натолкнулся на этот гениальный план, я попробовал соскабливать пол, выполняя поиск в Google по имени каждого актера, находя их страницу на IMDb, а затем извлекая их вакансии. На запуск потребовалось несколько дней, и я был только примерно на полпути, когда понял, что у IMDb есть набор данных, который может мне помочь. Я с большим энтузиазмом использовал веб-скрапинг, поскольку узнал об этом совсем недавно, но это заставило меня вспомнить, что определенные инструменты созданы для определенных целей. Веб-скрапинг позволяет самому собирать данные, но мне не нужно его использовать, если данные уже где-то там есть.
В следующем фрагменте кода я создаю новый список со строками, соответствующими полам всех участников приведения. Это дает мне свободу решать позже, хочу ли я маркировать фильмы по главной роли, по полу большинства актеров или по чему-то еще.
genders = [''] * len(data)
# loop through each row
for i, row in data.iterrows():
cast = row['cast']
cast_genders = []
# for each cast member, get their gender
for name in cast.split(','):
gender = ''
# professions_key stores a given name's professions
if (name in professions_key.keys()):
professions = professions_key[name]
if ('actor' in professions):
gender = 'male'
elif ('actress' in professions):
gender = 'female'
cast_genders.append(gender)
genders[i] = ','.join(cast_genders)
# store as new column in dataframe
data['genders'] = genders
Языковая модель SpaCy
Самая важная особенность, которая позволяет мне проводить этот анализ, заключается в том, что к каждому заголовку идет описание. В этих описаниях подробно описано основное содержание фильма или телешоу. Слова, используемые в этих описаниях, могут дать нам представление о том, о каких фильмах с определенным полом чаще всего рассказывают.
Инструмент, который позволяет нам выбирать эти определенные слова, - это пакет обработки естественного языка под названием spaCy. Мы используем очень простые функции языковой модели spaCy. По сути, языковая модель - это функция, которая присваивает вероятность заданным словам или предложениям, но в модель spaCy добавлены функции, которые обрабатывают общие функции НЛП. В нашем случае мы можем создать объект документа из модели spaCy, что позволит нам выбрать каждый токен (в нашем случае слово) из предложения и получить доступ к его части речи и леммы.
Получение его части речи полезно, потому что мы можем определить, какие слова являются важными существительными и глаголами для каждого пола, и отделить их от таких функций, как предлоги, которые для нас менее важны.
Лемма слова - это корневая форма слова. Например, лемма для слов «играл» и «играет» - это «играть». Это полезно, потому что для нас не так важно, используются ли разные формы слова, а просто то, что слово используется в Общее.
Это пример использования языковой модели прямо из документации spaCy:
import spacy
nlp = spacy.load(“en_core_web_sm”)
doc = nlp(“Apple is looking at buying U.K. startup for $1 billion”)
for token in doc:
print(token.text, token.lemma_, token.pos_, token.tag_, token.dep_, token.shape_, token.is_alpha, token.is_stop)
В этом анализе я рассмотрел 3 основных визуализации. Первый был просто облаком слов. Это дает мне общее представление о наиболее употребительных словах в описаниях. Второй - это сюжет, показывающий вероятность появления слов в описаниях фильмов и телешоу определенного пола. Это позволит выделить наиболее поляризованные слова и любые существенные различия в содержании фильмов. Последнее - сюжет о гендерной репрезентации в жанрах. Это даст нам лучшее представление о том, какие более широкие темы важны для каждого пола.
Облака слов
Я визуализировал два разных облака, одно для существительных, а другое для глаголов. Чтобы получить необходимые данные, я просмотрел каждое описание, применил языковую модель и сохранил лемму в словаре со списками для каждой части речи.
pos_words = {}
for description in data[‘description’]:
doc = nlp(description)
for token in doc:
pos = token.pos_
pos_words[pos].append(token.lemma_)

Здесь не так много сюрпризов, но это дает нам общее представление о словах в описаниях.
Гендерные слова
Что касается гендерных слов, я специально хотел создать что-то вроде статьи, которую я прочитал. Они рассчитали значения того, насколько более вероятно, что слово будет отображаться в женском или мужском контексте, поэтому я хотел сделать то же самое. Для этого я сначала собрал количество каждого слова (по частям речи) для каждого пола. Затем я вычислил вероятность того, что он появится в описании фильма определенного пола. Затем я взял отношение большей из двух вероятностей к меньшей из двух и дал ему знак, указывающий, какой пол более вероятен, т. Е. Отрицательный означает более вероятный женский пол, положительный означает более вероятный мужской.
Я исключил слова, которые встречаются только в одном роде, потому что я хотел посмотреть на слова, которые я мог бы сравнить, насколько более вероятно, что один пол был над другим, и слова, которые появлялись только в одном роде, чаще были просто словами, которые использовались очень редко, а не слова, которые особенно указывали на конкретный пол.
# retrieving counts
pos_counts = {}
for i, row in data.iterrows():
leading_gender = str(row['genders']).split(',')[0]
doc = nlp(str(row['description']))
for token in doc:
pos_counts[leading_gender][token.pos_][token.lemma_] += 1
# calculating probabilities
pos_probs = {}
for pos in all_pos.keys():
for word in all_pos[pos]:
male_count = pos_counts['male'][p][word] / male_total
female_count = pos_counts['female'][p][word] / female_total
male_prob = male_count / (male_count + female_count)
female_prob = female_count / (male_count + female_count)
prob = (max(male_prob, female_prob) / (min(male_prob, female_prob)))
prob *= 1 if (male_prob > female_prob) else -1
pos_probs[pos][word] = prob
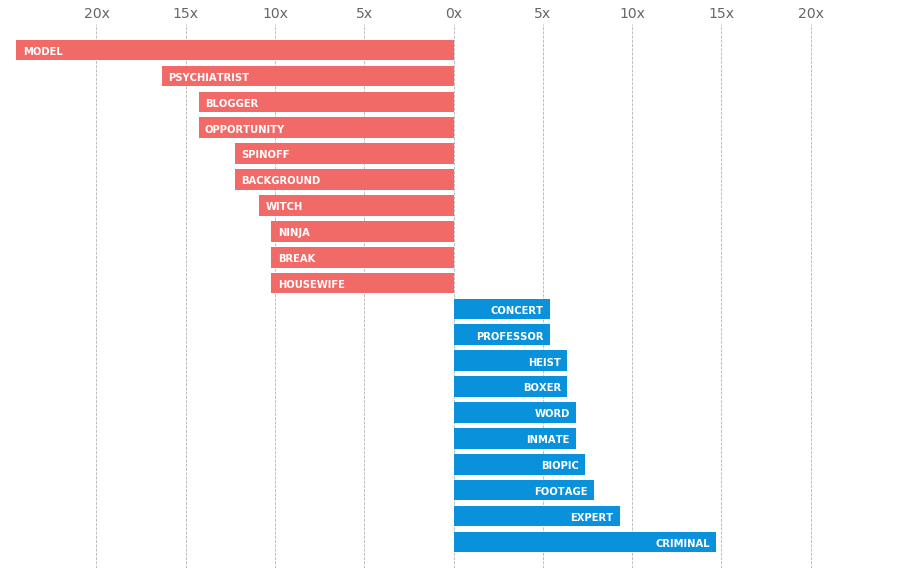
Некоторые действительно резкие гендерные различия, которые я заметил, заключались в том, что среди женских слов были «психиатр» и «блоггер», а среди мужских слов были «эксперт» и «профессор». Я бы рассмотрел эти в основном гендерно-нейтральные термины, но они встречаются среди существительных, наиболее поляризованных по гендерному признаку, в описаниях этих фильмов и телешоу.
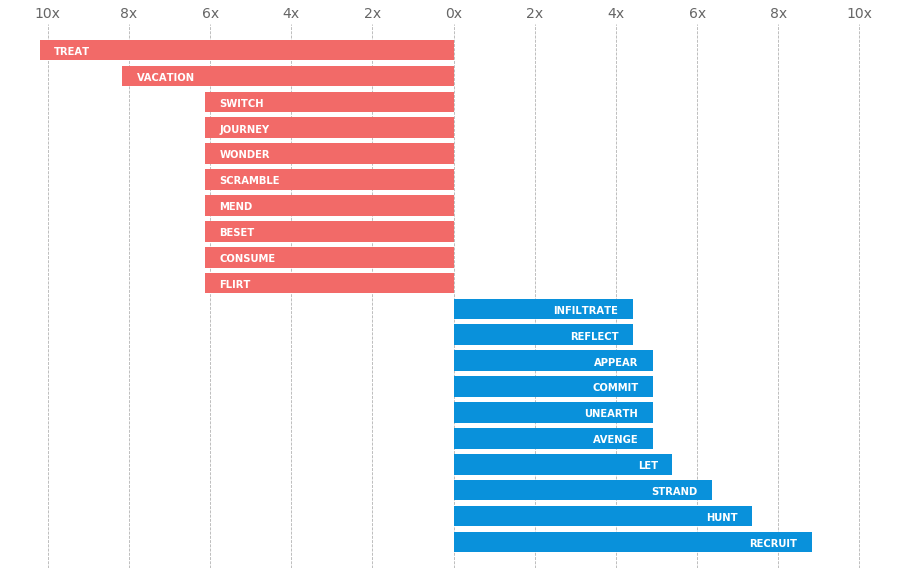
Здесь, если не считать слова «флирт», которые сильно ассоциируются с женщинами, все они довольно нейтральны. Однако, если смотреть на мужскую сторону вещей, «охота», «месть» и «проникновение» гораздо более гендерны и отражают традиционно мужские роли в боевиках или приключенческих фильмах.
Жанровое представление
Для представления жанров я просто подсчитал количество фильмов определенных жанров для каждого пола и нормализовал это количество по общему количеству названий между двумя полами, чтобы получить процент фильмов, имеющих теги определенного жанра. Это позволяет провести более справедливое сравнение.
leading = defaultdict(lambda: defaultdict(lambda: 0))
for i, row in data.iterrows():
leading_gender = row['genders'].split(',')[0]
genres = row['listed_in'].split(',')
for genre in genres:
leading[leading_gender][genre] += 1
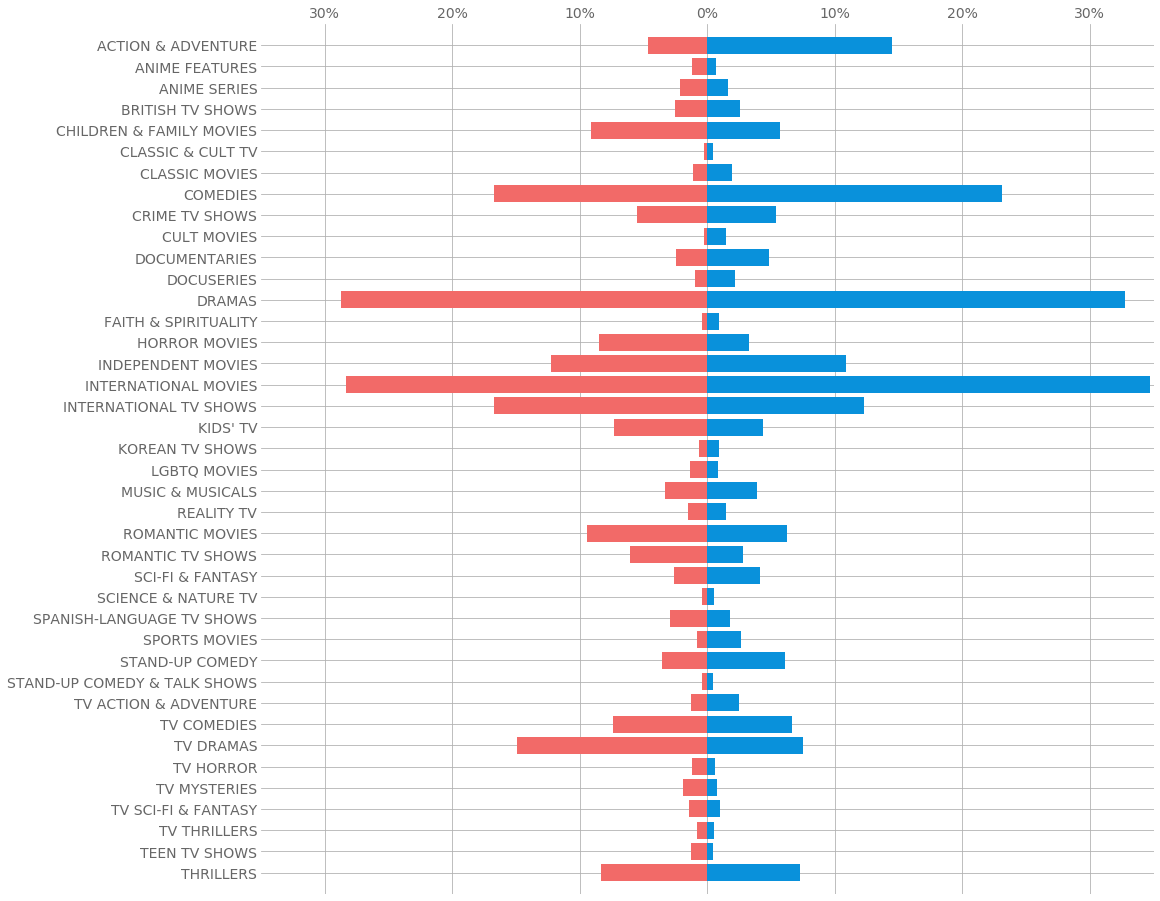
Несколько вещей, которые привлекли мое внимание, заключались в том, что в боевиках и комедиях в главных ролях больше мужчин, чем женщин, в то время как в романтических фильмах и телешоу в главных ролях больше женщин, чем мужчин. Это не так уж и шокирует, но дает некоторые эмпирические доказательства того, как развлечения влияют на то, как люди относятся к гендерным вопросам.
Еще одна вещь заключалась в том, что большая часть мужских главных ролей была драмами по сравнению с женскими, но большая доля женских главных ролей была телешоу по сравнению с мужскими. Это может послужить аргументом в пользу того, что представители разных полов лучше подходят для разных сред со стороны руководителей сети или зрителей.
Заключение
Пытаясь воссоздать вдохновляющий меня анализ, я обнаружил новые идеи и приобрел новые навыки. Использование этого нисходящего подхода к обучению навыкам по мере необходимости заставило меня использовать два набора данных для получения желаемых результатов и дало мне возможность изучить и использовать основы НЛП. Эта практика оказалась для меня очень полезной, и я думаю, что другие начинающие специалисты по данным могут многому научиться, делая то же самое.