
вступление
Написание быстрого запроса — одна из квалификаций, которую должен получить бэкэнд-инженер. Просто потому, что чем проще, тем быстрее база данных может загружать данные. Тем не менее, база данных вашей компании часто может оставаться ужасной и беспорядочной, так что выбор данных без использования одного или нескольких операторов join практически невозможен. Вот с чем я столкнулся пару дней назад.

Вот моя ситуация:
- Мне нужна была вся информация о данном идентификаторе получателя с именем отправителя и дополнительные данные дизайна, совпадающие с выбранным идентификатором дизайна.
- Имя отправителя было сохранено в таблице
account. - Дизайнерские штучки были разбросаны по нескольким разным столам.
Это означает, что я должен сделать идеальный запрос для загрузки данных, объединяя несколько таблиц. Запрос будет примерно таким:

Вместо этого сложного запроса, в котором несколько таблиц запутываются join операциями, мне пришла в голову блестящая идея разбить его на простые запросы и последовательно отправлять их соответственно в базу данных. Код будет таким:

- выбрать все данные, отфильтрованные по заданному индексу, из таблицы
alarmи сопоставить их с DAO. - выберите все данные, в которых идентификатор отправителя и идентификатор получателя совпадают с заданными параметрами, и сопоставьте их с DAO.
- После этого должны быть отправлены другие запросы, чтобы найти имя шаблона дизайна и его миниатюру в разных таблицах. Полученные данные будут интегрированы и отображены не в базе данных, а на бизнес-уровне, чтобы найти нужную нам информацию.
«Хорошо, для реализации логики нужно еще 5 запросов, но это, безусловно, будет намного быстрее и стабильнее, чем выполнение одного большого запроса», — подумал я.
Ждать! Это так?
Пул соединений
Это было совершенно неправильно, как вы догадываетесь. Когда я тестировал два метода для загрузки одного объекта Alarm, просто выполнение одного большого запроса с набором join операций было в 6 раз быстрее, чем использование нескольких запросов, с которыми легко работать.

Составление списка Alarm объектов заняло неожиданно больше времени. Насколько сложным был запрос, он был более чем в 30 раз быстрее, чем его разбивка на упрощенные подзапросы. Чтобы выяснить причину, сначала нужно понять, как сервер подключен к базе данных (особенно при использовании JDBC). Ниже изложена концепция «пула соединений».
Что такое пул соединений?

Oracle говорит, что Пул соединений — это именованная группа идентичных JDBC-соединений с базой данных, которые создаются при регистрации пула соединений, обычно при запуске WebLogic Server. Ваше приложение «заимствует соединение из пула, использует его, а затем возвращает в пул, закрывая его». Существует несколько преимуществ непрямых подключений:
- Использование пулов соединений намного эффективнее, чем создание нового соединения для каждого клиента каждый раз, когда ему требуется доступ к базе данных.
- Вам не нужно жестко кодировать такие детали, как пароль СУБД, в вашем приложении.
- Вы можете ограничить количество подключений к вашей СУБД. Это может быть полезно для управления лицензионными ограничениями на количество подключений к вашей СУБД.
- Вы можете изменить используемую СУБД без изменения кода приложения.
Тем не менее, для оптимальной производительности рекомендуется от восьми до шестнадцати подключений на узел, что указывает на то, что если к базе данных передается количество запросов, превышающее размер пула, остальные должны ждать, пока некоторые из подключений не будут полностью использованы и возвращены, в противном случае тайм-аут подключения послал.
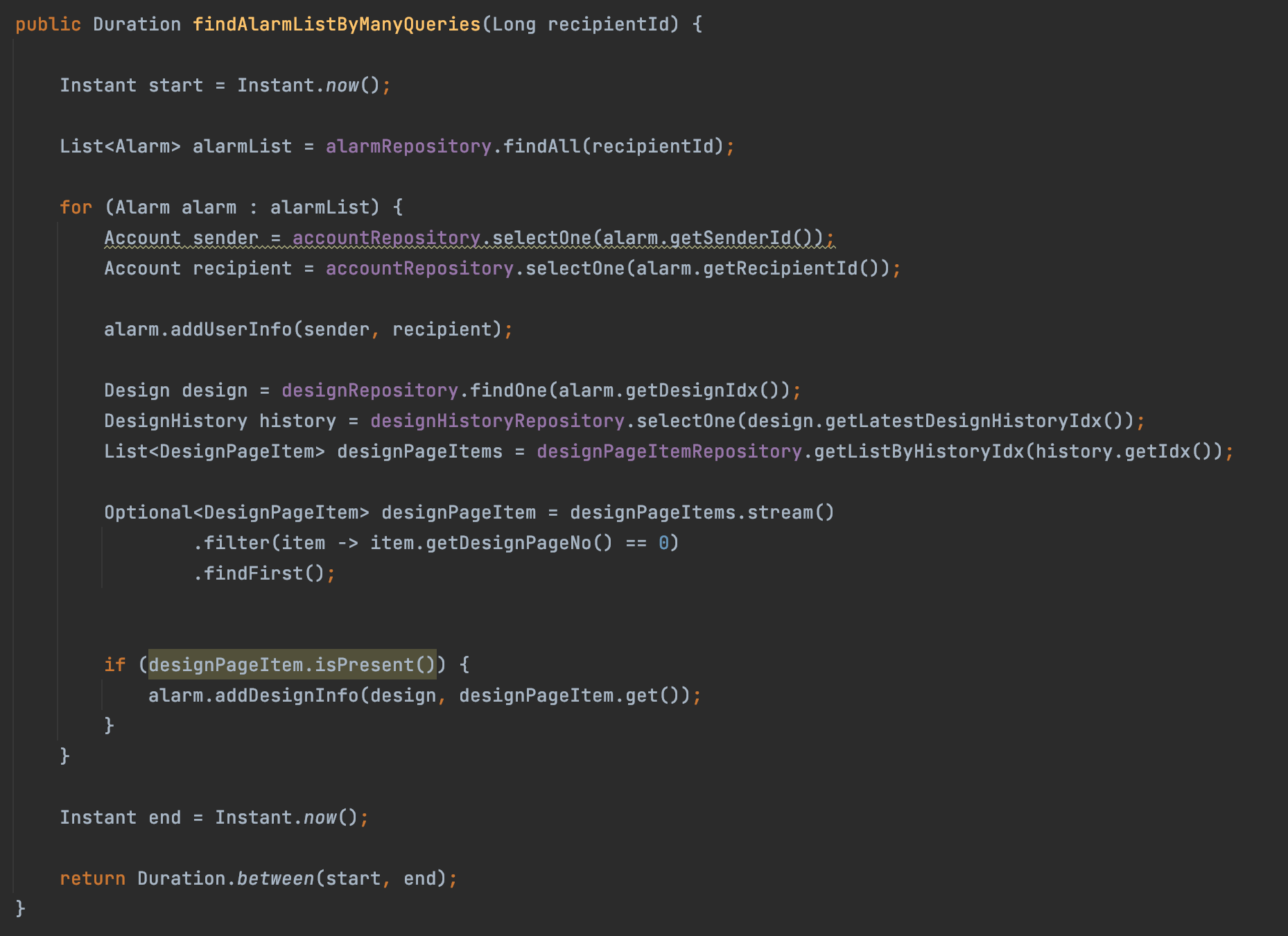
В этом примере я упустил из виду, что стоимость «заимствования» соединения из пула намного выше, чем стоимость обработки жестко закодированного запроса; По сравнению с первым, последний практически не влияет на производительность. Скорее, общее затраченное время увеличилось пропорционально количеству подключений, так как было найдено четыре объекта Alarm и суммировано двадцать запросов — всего был использован 21 запрос. Обратите внимание, что расчетная скорость должна была составлять около 2000 %, но на самом деле потребовалось больше времени, потому что размер пула был установлен равным исходному размеру по умолчанию, то есть 8, и был увеличен до 32 для клиентских запросов.
Заключение
В этом посте мы теперь понимаем, что каким бы простым ни был запрос, множественные запросы к базе данных должны занимать много времени. База данных всегда является внешней по отношению к серверу, поэтому ограниченный размер пула соединений вызывает экспоненциальное увеличение времени. Следовательно, для оптимальной производительности вам необходимо сосредоточиться на двух задачах:
- Сделайте свою базу данных структурно организованной.
- Подумайте, как минимизировать количество запросов.