После глубокого введения в функциональное программирование в моей последней статье Новый функциональный стиль Java, я думаю, что пришло время более глубоко взглянуть на Java Streams и понять, как они работают внутри. Это может быть очень важно при работе с Streams, если это может повлиять на нашу производительность.
Вы сможете увидеть, насколько проще и эффективнее обработка последовательностей элементов с помощью Java Streams по сравнению с старым, и насколько приятно писать код, используя плавные интерфейсы.
Теперь вы можете попрощаться с подверженным ошибкам кодом, полным шаблонного кода и беспорядка, который значительно усложнял нашу жизнь как разработчиков.
Давайте начнем с краткого введения в Java Streams!

Вступление
Java Streams - это, по сути, конвейер агрегированных операций, которые можно применять для обработки последовательности элементов.
Агрегатная операция - это функция высшего порядка, которая получает поведение в форме функции или лямбда, и это поведение применяется к нашей последовательности.
Например, если определяем следующий поток:
collection.stream()
.map(element -> decorateElement(element))
.collect(toList())
В этом случае поведение, которое мы применяем к каждому элементу, указано в нашем методе «decorateElement», который предположительно будет создавать новый «расширенный »или« украшенный »элемент на основе существующего элемента.
Java Streams построены вокруг его основного интерфейса, интерфейса Stream, который был выпущен в JDK 8. Давайте вкратце расскажем немного подробнее!
Характеристики ручья
Как было сказано в моей прошлой статье, Java Streams имеет следующие основные характеристики:
- Декларативная парадигма
Потоки написаны с указанием того, что должно быть сделано, но не как. - Ленивая оценка
Это в основном означает, что, пока мы не вызовем операцию терминала, наш поток ничего не будет делать, мы просто объявим, что будет делать наш конвейер. - Его можно использовать только один раз
После вызова операции терминала необходимо создать новый поток, чтобы применить ту же серию агрегатных операций. - Можно распараллеливать
Java-потоки по умолчанию являются последовательными, но их можно очень легко распараллелить.
Мы должны рассматривать потоки Java как серию связанных каналов, в каждом из которых наши данные обрабатываются по-разному; эта концепция очень похожа на трубы UNIX!

Фазы потока
Java Stream состоит из трех основных фаз:
- Разделение
Данные собираются, например, из коллекции, канала или функции генератора. На этом этапе мы преобразуем источник данных в поток для обработки наших данных, мы обычно называем его источником потока. - Применить
Каждая операция в конвейере применяется к каждому элементу в последовательности. Операции на этом этапе называются промежуточными операциями. - Объедините
завершение с операцией терминала, при которой поток материализуется.
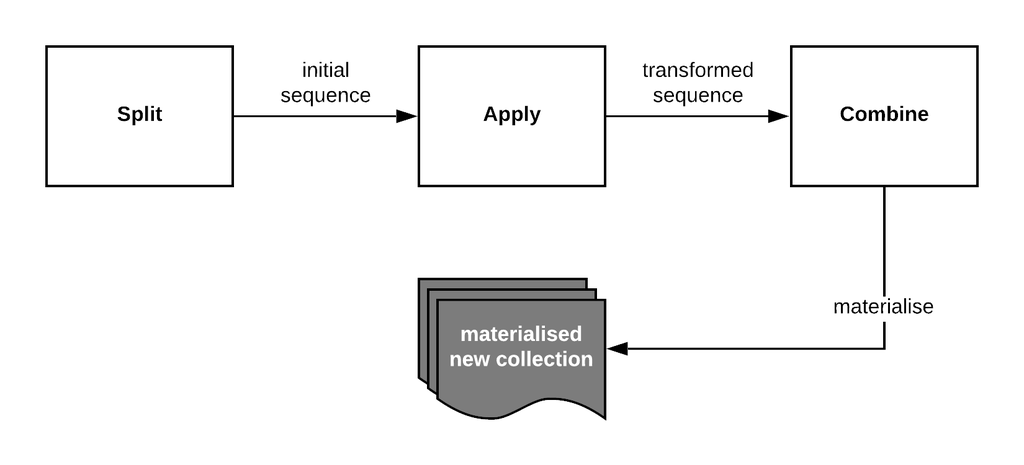
Помните, что при определении потока мы просто объявляем шаги, которые необходимо выполнить в нашем конвейере операций, они не будут выполнены, пока мы не вызовем нашу операцию терминала.
В Java есть два интерфейса, которые очень важны для этапов SPLIT и COMBINE; это интерфейсы Spliterator и Collector.
Интерфейс Spliterator допускает два поведения, которые очень важны на этапе разделения: итерация и возможное разделение элементов.
Первый из этих аспектов довольно очевиден, мы всегда будем хотеть для перебора нашего источника данных; а как насчет разделения?
Разделение будет иметь большое значение при запуске параллельных потоков, так как оно будет отвечать за разделение потока, чтобы дать независимую часть работы каждому потоку .
Spliterator предоставляет два метода доступа к элементам:
boolean tryAdvance(Consumer<? super T> action);
void forEachRemaining(Consumer<? super T> action);И еще один метод разделения нашего источника потока:
Spliterator<T> trySplit();Начиная с JDK 8, метод spliterator был включен в каждую коллекцию, поэтому потоки Java используют Spliterator внутри себя для итерации по элементам Stream.
Java предоставляет реализации интерфейса Spliterator, но вы можете предоставить свою собственную реализацию Spliterator, если по какой-либо причине вам это нужно.
Java предоставляет набор сборщиков в классе Collectors, но вы также можете сделать то же самое с интерфейсом Collector, если вам нужен собственный сборщик, чтобы по-другому комбинировать полученные элементы!
Давайте теперь посмотрим, как конвейер Stream работает внутри и почему это важно.
Внутреннее устройство потока
Операции Java Streams хранятся внутри с использованием структуры LinkedList, а в его внутренней структуре хранения каждому этапу назначается растровое изображение, которое следует этой структуре:

Таким образом, мы могли бы представить это представление, например:
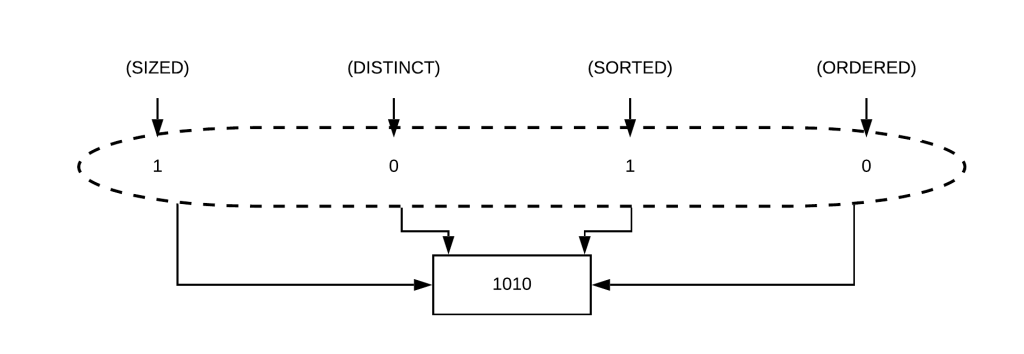
Почему это так важно? Потому что это растровое представление позволяет Java выполнять оптимизацию потока.
Каждая операция очищает, устанавливает или сохраняет разные флаги; это очень важно, потому что это означает, что каждый этап знает, какие эффекты вызывают сами себя в этих флагах, и это будет использоваться для оптимизации.
Например, map очистит биты SORTED и DISTINCT, поскольку данные могли измениться; однако он всегда будет сохранять флаг РАЗМЕР, так как размер потока никогда не будет изменен с помощью карты. Имеет ли это смысл?
Давайте рассмотрим другой пример, чтобы прояснить ситуацию. например, фильтр очистит флаг РАЗМЕР, поскольку размер потока мог измениться, но всегда сохранит флаги СОРТИРОВАТЬ и РАЗЛИЧНЫЙ. потому что фильтр никогда не изменит структуру данных. Это достаточно ясно?

Итак, как Stream использует эти флаги для своей выгоды? Помните, что операции структурированы в LinkedList? Итак, каждая операция объединяет флаги из предыдущего этапа со своими собственными флагами, создавая новый набор флагов.
Исходя из этого, во многих случаях мы сможем пропустить некоторые этапы! Давайте посмотрим на пример:

В этом примере мы создаем Набор строк, который всегда будет содержать уникальные элементы. Позже в нашем Stream мы будем использовать разные, чтобы получить уникальные элементы из нашего Stream; Set уже гарантирует уникальные элементы, поэтому наш Stream сможет ловко пропустить этот этап, используя флаги, которые мы объяснили выше. Это здорово, правда?
Мы узнали, что потоки Java могут прозрачно оптимизировать наши потоки благодаря своей внутренней структуре, давайте теперь посмотрим, как они выполняются!
Исполнение
Мы уже знаем, что Stream выполняется лениво, поэтому при выполнении операции терминала происходит то, что Stream выбирает план выполнения.
Существует два основных сценария выполнения Java Stream: когда все этапы не имеют состояния, и когда НЕ все этапы не имеют состояния.
Чтобы понять это, нам нужно знать, что такое операции без состояния и с сохранением состояния:
- Операции без состояния
Операции без сохранения состояния не нужно знать ни о каком другом элементе, чтобы иметь возможность выдать результат. Примеры операций без сохранения состояния: фильтр, карта или flatMap. - Операции с отслеживанием состояния
Напротив, операции с отслеживанием состояния должны знать обо всех элементах до выдачи результата. Примеры операций с отслеживанием состояния: отсортированные, ограничивающие или отдельные.
В чем же тогда разница в этих ситуациях? Что ж, если все операции не имеют состояния, тогда Stream может быть обработан за один раз. С другой стороны, если он содержит операции с отслеживанием состояния, конвейер делится на секции, используя операции с отслеживанием состояния в качестве разделителей.
Давайте сначала взглянем на простой конвейер без сохранения состояния!
Выполнение конвейеров без состояния
Мы склонны думать, что потоки Java будут выполняться точно в том же порядке, в котором мы их пишем; это неправильно, давайте посмотрим, почему.
Давайте рассмотрим следующий сценарий, в котором нас попросили предоставить список сотрудников с зарплатой ниже 80 000 долларов и обновить их зарплаты с увеличением на 5%. За это отвечает поток, показанный ниже:
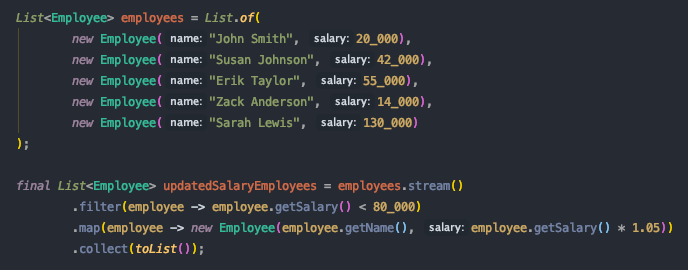
Как вы думаете, как это будет выполняться? Обычно мы думаем, что коллекция сначала фильтруется, затем мы создаем новую коллекцию, включающую сотрудников с их обновленными зарплатами, и, наконец, собираем результат, верно? Что-то вроде этого:
К сожалению, на самом деле Java Streams выполняется не так; чтобы доказать это, мы собираемся добавить журналы для каждого шага в нашем потоке, просто расширяя лямбда-выражения:

Если наши первоначальные рассуждения были правильными, мы должны увидеть следующее:
Filtering employee John Smith
Filtering employee Susan Johnson
Filtering employee Erik Taylor
Filtering employee Zack Anderson
Filtering employee Sarah Lewis
Mapping employee John Smith
Mapping employee Susan Johnson
Mapping employee Erik Taylor
Mapping employee Zack AndersonМы ожидаем, что сначала каждый элемент пройдет через фильтр, а затем, поскольку у одного из сотрудников зарплата выше 80 000 долларов, мы ожидаем, что четыре элемента будут сопоставлены новому сотруднику с обновленной зарплатой.
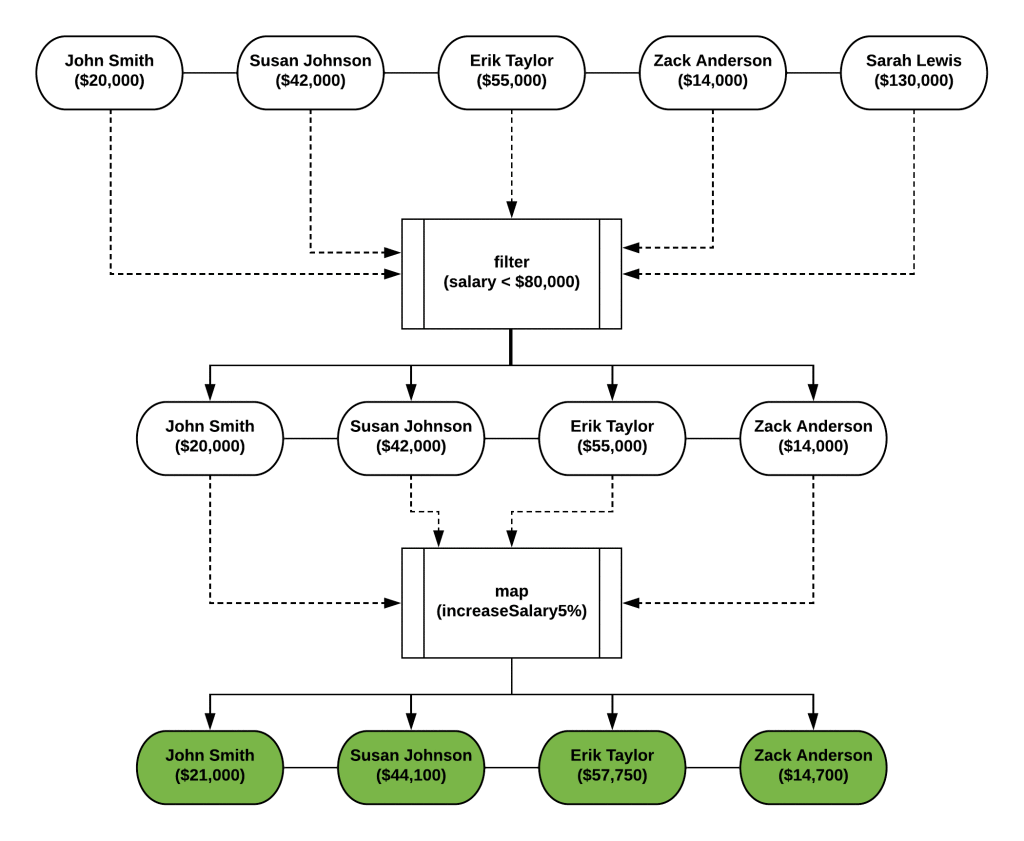
Посмотрим, что на самом деле происходит, когда мы запускаем наш код:
Filtering employee John Smith
Mapping employee John Smith
Filtering employee Susan Johnson
Mapping employee Susan Johnson
Filtering employee Erik Taylor
Mapping employee Erik Taylor
Filtering employee Zack Anderson
Mapping employee Zack Anderson
Filtering employee Sarah LewisХммм, это не то, чего вы ожидали, верно? На самом деле, как обрабатываются потоки Java, больше похоже на это:
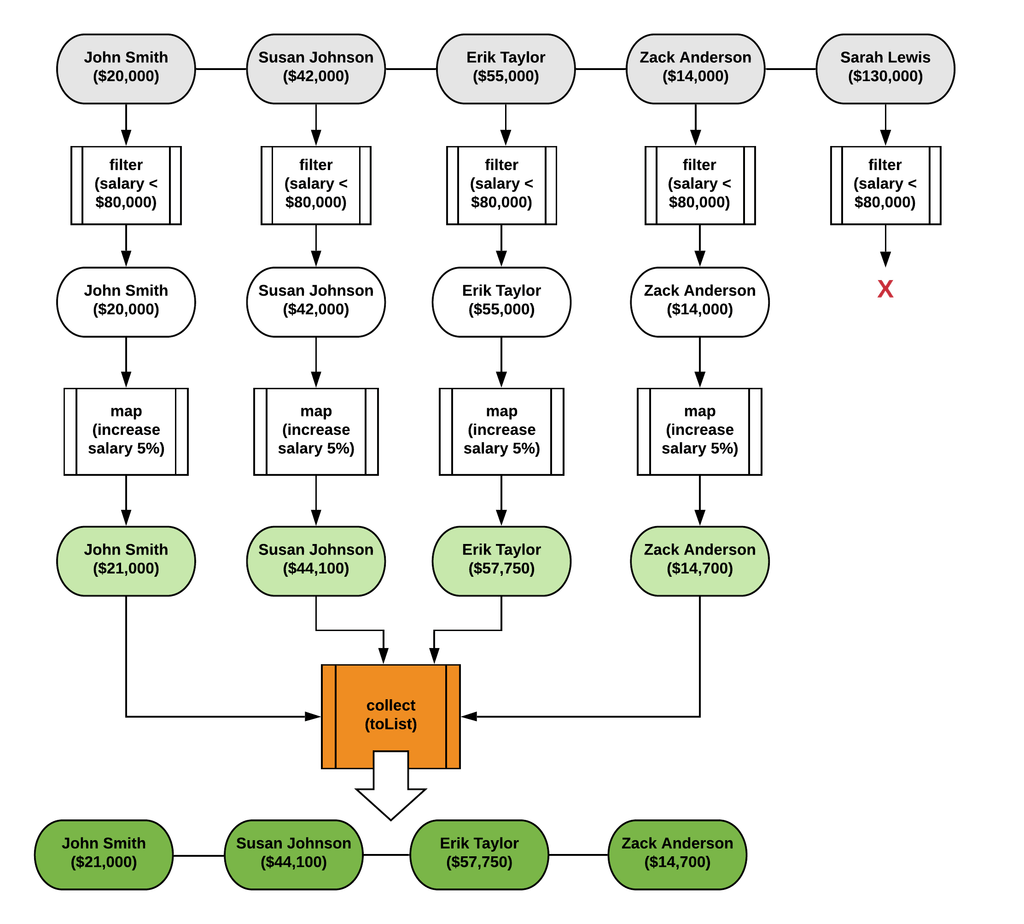
Это довольно удивительно, правда?
На самом деле элементы Stream обрабатываются индивидуально, а затем, наконец, собираются. Это ОЧЕНЬ ВАЖНО для правильного функционирования и эффективности Java Streams! Почему?
Прежде всего, параллельная обработка очень безопасна и проста, следуя этому типу обработки, поэтому мы можем очень легко преобразовать поток в параллельный поток!
Еще одним большим преимуществом этого является то, что называется закорачивающими клеммами. Мы кратко рассмотрим их позже!
Выполнение конвейеров с сохранением состояния
Как мы упоминали ранее, основное различие, когда у нас есть операции с состоянием, заключается в том, что операция с сохранением состояния должна знать обо всех элементах до выдачи результата. Итак, что происходит: операция с сохранением состояния буферизует все элементы, пока не достигнет последнего элемента, а затем выдаст результат.
Это означает, что наш конвейер делится на две части!
Давайте изменим наш пример, показанный в последнем разделе, чтобы включить операцию с отслеживанием состояния в середине двух существующих этапов; мы будем использовать sorted, чтобы доказать, как работает выполнение Stream. Обратите внимание, что для использования отсортированного метода без аргументов класс Employee теперь должен реализовать интерфейс Comparable.
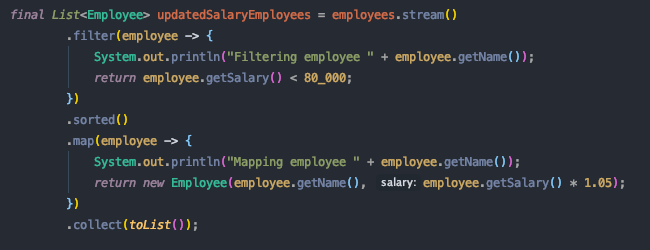
Как вы думаете, как это будет реализовано? Будет ли он таким же, как в нашем предыдущем примере с операциями без сохранения состояния? Давайте запустим его и посмотрим, что произойдет.
Filtering employee John Smith
Filtering employee Susan Johnson
Filtering employee Erik Taylor
Filtering employee Zack Anderson
Filtering employee Sarah Lewis
Mapping employee Erik Taylor
Mapping employee John Smith
Mapping employee Susan Johnson
Mapping employee Zack AndersonСюрприз! Изменился порядок выполнения этапов!
Почему?
Как мы объясняли ранее, когда мы используем операцию с отслеживанием состояния, наш конвейер делится на две части. Именно это и произошло!
Сортированный метод не может выдать результат, пока все элементы не будут отфильтрованы, поэтому он буферизует их перед передачей любого результата следующему этапу (карте).
Это наглядный пример того, как план выполнения полностью меняется в зависимости от типа операции; это делается абсолютно прозрачным для нас способом.
Выполнение параллельных потоков
Мы можем очень легко выполнять параллельные потоки, используя parallelStream или parallel. Так как же это работает внутри?
На самом деле это довольно просто. Java использует метод trySplit, чтобы попытаться разделить коллекцию на части, которые могут обрабатываться разными потоками.
Что касается плана выполнения, он работает очень похоже, с одним основным отличием. Вместо одного набора связанных операций, у нас есть несколько его копий, и каждый поток применяет эти операции к части элементов, за которые он отвечает; после завершения все результаты, полученные каждым потоком, объединяются для получения единого и окончательного результата!
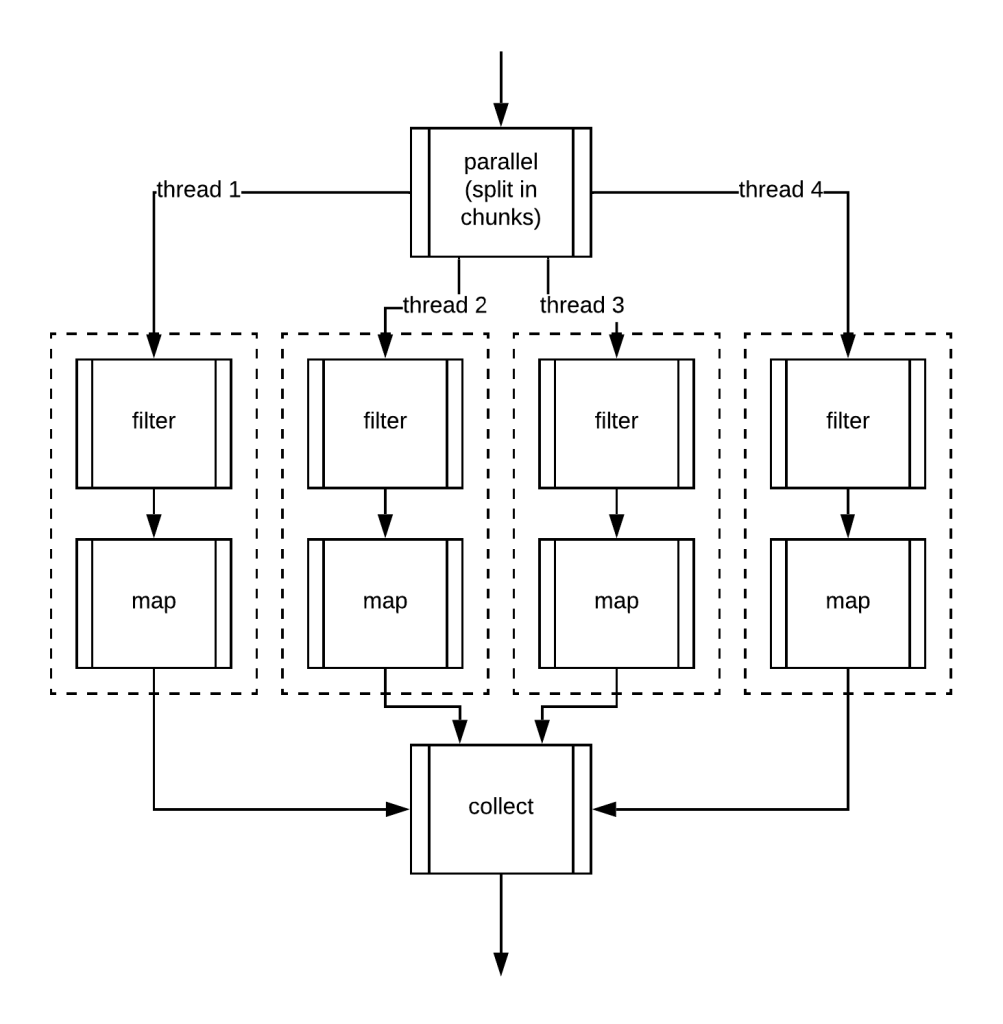
Лучше всего то, что потоки Java делают это прозрачно для нас! Это здорово, не правда ли?
Последнее, что нужно знать о параллельных потоках, это то, что Java назначает каждый фрагмент работы потоку в общем ForkJoinPool так же, как это делает CompletableFuture.
Теперь, как и было обещано, давайте кратко рассмотрим операции терминала с коротким замыканием, прежде чем мы завершим этот раздел о том, как работают потоки.
Короткое замыкание клеммных операций
Закорачивающие терминальные операции - это своего рода операции, при которых мы можем закоротить поток, как только мы нашли то, что искали, даже если это параллельный поток и несколько потоков выполняет некоторую работу.
Если мы внимательно рассмотрим некоторые операции, такие как: limit, findFirst, findAny, anyMatch, allMatch или noneMatch; мы увидим, что мы не хотим обрабатывать всю коллекцию, чтобы получить окончательный результат.
В идеале мы хотели бы прервать обработку потока и вернуть результат, как только мы его найдем. Это легко достигается способом обработки Java Streams; элементы обрабатываются индивидуально, поэтому например, если мы обрабатываем операцию терминала noneMatch, мы завершаем обработку, как только один элемент соответствует критериям. Надеюсь, это имеет смысл!

Один интересный факт, который следует упомянуть с точки зрения выполнения, заключается в том, что для операций короткого замыкания вызывается метод tryAdvance в Spliterator; однако для операций без короткого замыкания вызываемый метод будет forEachRemaining.
Это от меня! Я надеюсь, что теперь вы хорошо понимаете, как работают Java Streams, и что это поможет вам легче разрабатывать потоковые конвейеры!
Если вам нужно улучшить свое понимание Java Streams и функционального программирования на Java, я бы порекомендовал вам прочитать Функциональное программирование на Java: использование возможностей лямбда-выражений Java 8 ; Вы можете купить его на Amazon по следующей ссылке.
Заключение
Java Streams - это значительное улучшение языка Java; не только наш код более читабелен и легче отслеживается, но и менее подвержен ошибкам и более плавно в написании. Необходимость писать сложные циклы и иметь дело с переменными только для итерации коллекций - не самый эффективный способ делать что-то в Java.
Однако я думаю, что главное преимущество заключается в том, что потоки Java позволили любому выполнять параллельное программирование! Вам больше не нужно быть экспертом в области параллелизма, чтобы писать параллельный код; хотя хорошо, что вы разбираетесь во внутреннем устройстве, чтобы избежать возможных проблем.
То, как Java разумно обрабатывает потоки, расчистило наши пути для обработки коллекций и написания параллельных программ, и мы должны воспользоваться этим!

Я надеюсь, что то, что мы рассмотрели в этой статье, было достаточно ясным, чтобы помочь вам хорошо разобраться в Java Streams. Я также надеюсь, что вам понравилось это чтение так же, как мне нравится писать, чтобы поделиться этим с вами, ребята!
В следующей статье мы покажем много примеров того, как использовать Java Streams, поэтому, если вам понравилась эта статья, подпишитесь / подпишитесь, чтобы получать уведомления, когда будет опубликована новая статья. Было приятно видеть вас, и я надеюсь, что снова увижу вас!
Большое спасибо за чтение!