Работа с отсутствующими данными и выбросами

Как мы упоминали в первой части Необходимость очистки данных - часть 1, мы продолжим рассмотрение других проблем с данными и способов их решения.
Когда вы собираете или работаете с данными, вы можете обнаружить, что у вас отсутствуют данные в виде пропущенных значений для полей, или вы можете обнаружить, что ваши данные содержат выбросы, которые на самом деле не имеют особого смысла.
Отсутствующие данные

Когда вы работаете с данными, которые отсутствуют в записях, которые вам нужно обучить вашей модели. Есть два подхода, которым вы можете следовать, чтобы работать с этими данными.
1- Удаление
2- Вменение
Удаление A.K.A. Удаление по списку
Удаляет записи (строки) целиком, если отсутствует одно значение (столбец).
Это простой и беспроблемный метод работы с отсутствующими значениями, но он может привести к смещению, поскольку вы можете удалить очень относительные данные.
Списочное удаление часто является наиболее распространенным на практике, потому что оно простое, но может привести к нескольким проблемам. Это может значительно уменьшить размер выборки, с которой вы работаете. Если у вас не так много записей и вы применили этот подход, может возникнуть ситуация, когда у вас недостаточно данных для обучения модели машинного обучения.
Еще один повод для беспокойства: если значения не пропадают случайно, их удаление может привести к значительному смещению. Например, если вы собираете данные с датчиков и есть датчик, у которого отсутствуют значения в определенном поле, если вы продолжите и удалите все записи с этого датчика. Это может привести к значительной систематической ошибке.
Итак, совершенно очевидно, что просто отбрасывать целые записи, в которых отсутствуют некоторые поля, не самый лучший вариант, поэтому мы переходим к Вменению.
Расчет
Заполните отсутствующие значения столбца, а не удаляйте записи с пропущенными значениями. Отсутствующие значения выводятся из известных данных.
После того, как вы решили использовать замену пропущенных значений методом вменения, вы можете выбрать ряд методов от очень простых до очень сложных.
Самый простой из возможных методов - использовать среднее значение по столбцу. Вы предполагаете, что отсутствующие значения по существу равны среднему значению в этом столбце или для этой функции. Другой очень похожий вариант - использовать среднее значение этого столбца или режим этого столбца.
Другой способ вменения отсутствующих значений я интерполирую из других близлежащих значений. Этот метод полезен, когда ваши записи упорядочены в определенном порядке.
Вменение для заполнения пропущенных значений может быть очень сложным, на самом деле вы можете построить всю модель машинного обучения для прогнозирования отсутствующих значений в ваших данных.
Теперь вы можете выполнить вменение разными способами.
Многовариантное вменение
Одномерное вменение: полагайтесь на известные значения в той же функции или столбце.
Многовариантность вменения: используйте все известные данные для вывода отсутствующих данных.
Например - для многомерного вменения - вы можете построить модели регрессии из других столбцов, чтобы предсказать этот конкретный столбец, вы повторите это для всех столбцов, которые содержат пропущенные значения.
Есть и другие методы, которые можно применить для заполнения недостающих значений.
Hot-deck Imputation
Вы отсортируете все имеющиеся у вас записи по любым критериям. И для каждого отсутствующего значения вы можете использовать непосредственно предшествующее доступное значение.
Заполнение пропущенных значений с использованием предыдущего значения, одна из ваших записей была заказана. Это специально используется для заполнения данных временных рядов, где прогрессия во времени имеет полезное значение.
Для временных рядов эквивалентно предположению, что с момента последнего измерения не произошло никаких изменений.
Распространенной техникой, которая часто используется, является замещение среднего значения.
Среднее замещение
Для каждого пропущенного значения подставьте среднее всех доступных значений. Подстановка среднего имеет эффект ослабления корреляции между столбцами, которые существуют в ваших данных.
Когда вы, по сути, называете эту среднюю точку данных, в ней нет ничего особенного, вы ослабляете корреляцию, и это может быть проблематичным при выполнении двумерной анализ, двумерный анализ - это анализ для определения взаимосвязи между 2 столбцами.
Если вы хотите разумно предсказать недостающие значения в ваших данных, возможно, вы захотите использовать машинное обучение.
Регрессия

Подобрать модель для прогнозирования отсутствующих столбцов на основе значений других столбцов. Применение этого метода имеет тенденцию усиливать корреляции, существующие в ваших данных, потому что вы, по сути, говорите, что этот столбец зависит от другого столбца.
Регрессия и замещение среднего для заполнения пропущенных значений имеют взаимодополняющие преимущества
Выбросы
Выбросы: точка данных, которая значительно отличается от других точек в том же наборе данных.
Если вы визуализируете свои данные, вы можете найти что-то вроде этого
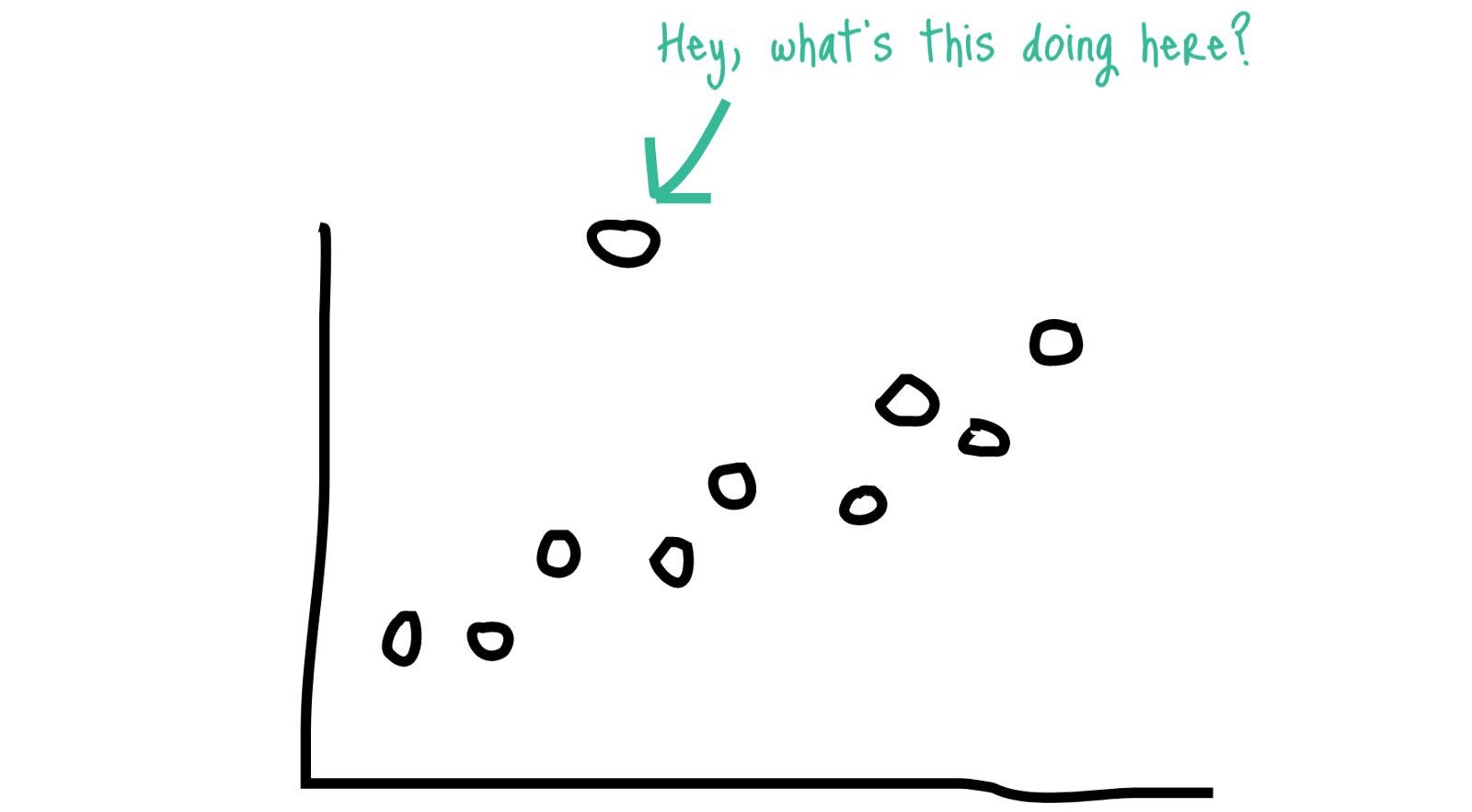
Возможно, вся запись каким-то образом является выбросом или есть определенные поля с выбросами.
При работе с данными выбросов это двухэтапный процесс, первый шаг - это определение выбросов, которые существуют в ваших данных, второй шаг - использование методов, позволяющих справиться с этими выбросами.
Существуют определенные алгоритмы машинного обучения, которые были созданы для обнаружения выбросов, но на самом базовом уровне вы можете идентифицировать выбросы, видя расстояние до этой точки данных от среднего значения ваших данных или расстояние от линии, которую вы вписываете в свои данные.
Определив выбросы, вы можете справиться с выбросами, используя три метода: отбросить записи с данными выбросов, выбросы верхнего / нижнего пределов или установить выбросы на среднее значение этой характеристики.

Выявление выбросов: расстояние от среднего
Если у вас есть точка данных со значением, далеким от среднего значения, которое можно рассматривать как выброс, или вы можете выполнить некоторый регрессионный анализ и найти линию или кривую, которые следуют шаблону в ваших данных, если у вас есть точка, которая далека от этой подходящей линии, которая является выбросом.
Если вы хотите быстро обобщить любой набор данных, с которым вы работаете, первая мера, которую вы укажете, является средним значением этих данных.
Среднее или среднее - это одно число, которое лучше всего представляет все эти точки данных.
Среднее или Среднее любого набора данных - это сумма всех чисел, деленная на количество чисел.

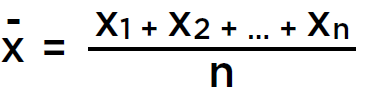
Однако наряду со средним значением также важны вариации, существующие в ваших данных.
Вариант: это показатель того, меняется ли число в вашем наборе данных.
Одним из важных показателей вариации в наборе данных является диапазон.
Диапазоны полностью игнорируют среднее значение, и на него влияют выбросы, которые присутствуют в вашем наборе данных, вот где и проявляется дисперсия.
Дисперсия - это второе по важности число для суммирования любого набора точек, с которым вы работаете.

Среднее значение и дисперсия кратко суммируют любой набор чисел.
Помимо дисперсии, вы можете встретить еще один термин - стандартное отклонение.
Стандартное отклонение: представляет собой квадратный корень из дисперсии и является мерой вариации ваших данных.
Стандартное отклонение помогает вам выразить, насколько далеко конкретная точка данных находится от среднего значения.
Выявление выбросов: расстояние от подогнанной линии

Выбросы также могут быть точками данных, которые не соответствуют тем же отношениям, что и остальные данные.
Как справиться с выбросами
Как только вы определите выбросы, вам нужно выяснить, как вы с ними справляетесь, как вы хотите с ними справляться?
Всегда начинайте с тщательного изучения выбросов, которые существуют в ваших данных
При ошибочном наблюдении:
- Удалите всю запись, если все атрибуты этой точки ошибочны.
- В строке или записи есть один атрибут, который, по вашему мнению, является ошибочным: установите для него среднее значение.
Вполне возможно, что ваши данные о выбросах не являются неправильным наблюдением, это подлинные, законные выбросы. У вас есть 2 подхода к работе с такими выбросами:
- Оставить как есть, если модель не искажена
- Cap / Floor, если модель искажена, но сначала вам нужно стандартизировать ваши данные.
Заключительные слова…
Поскольку вам необходимо использовать данные для принятия важных бизнес-решений, можно с уверенностью сказать, что периодическая очистка и обогащение ваших данных является обязательной.
Спасибо за внимание.
Надеюсь, вам понравилась моя серия статей об очистке данных.
