
Развертывание через гетерогенные ускорители на периферии в Kubernetes
В прошлой статье мы представили использование меток узлов, производных от дерева устройств, для маркировки статических функций пограничных шлюзов, но заметили, что это не полное решение для маркировки, учитывая отсутствие поддержки для идентификации и маркировки устройств, подключенных к перечисляемым шинам. такие как PCI или USB.
К счастью, есть еще один проект, который хотя бы частично позаботился об этом - проект Kubernetesnode-feature-discovery (NFD). Я говорю частично, так как он позаботился о PCI, но нам пришлось написать поддержку USB самим. Поддержка USB теперь объединена в следующем выпуске. Мы более подробно рассмотрим NFD ниже.
Обзор NFD
NFD - это, как следует из названия, инструмент для обнаружения функций узлов в кластерах Kubernetes. Это достигается путем обнаружения оборудования и извлечения информации о конфигурации ОС для каждого узла и передачи этих результатов мастеру для маркировки.
Сам NFD состоит из двух разных компонентов:
nfd-master- это компонент, отвечающий за маркировку узловnfd-worker- это компонент, ответственный за обнаружение признаков и передачу результатов вnfd-master.
Репозиторий Git для NFD можно найти здесь:
Обнаружение устройства NFD
Благодаря интегрированной поддержке USB NFD теперь по умолчанию будет сканировать устройства PCI и USB, которые попадают в белый список классов устройств. Это компромисс между снижением отношения сигнал / шум и обеспечением того, чтобы устройства, которые с наибольшей вероятностью будут использоваться в качестве основы для информирования о критериях выбора узла, будут открыты.
В случае PCI белый список классов:
- Контроллеры дисплея
- Ускорители обработки
- Сопроцессоры
В случае USB мы обычно пытались согласовать с представлением PCI, но сталкиваемся с парой дополнительных проблем:
- Базовые классы USB предоставляют поставщикам значительно больше возможностей для произвольной классификации своих продуктов.
- Многие USB-устройства не кодируют свой базовый класс на уровне устройства, а вместо этого передают его на уровень интерфейса. У USB-устройства может быть несколько интерфейсов, и они не всегда реализуют один и тот же класс.
Чтобы обойти эти проблемы, мы намеренно расширили сеть возможных базовых классов и включили перечисление интерфейсов, которое будет отображать любой уникальный интерфейс, соответствующий белому списку кодов классов. Белый список классов:
- видео
- Разное
- Зависит от приложения
- Зависит от поставщика
Полный список доступных кодов можно найти здесь. Кроме того, при необходимости можно переопределить или расширить список с помощью настраиваемого правила сопоставления.
Шаблоны развертывания NFD
NFD можно развернуть несколькими способами:
- Как
Deploymentна мастере Kubernetes, в котором рабочие планируются какDaemonSetна каждом рабочем узле (узлы мастер-меток). - Как автономный
DaemonSetна каждом узле (узлы маркируют себя). - Как автономный
DaemonSetв сочетании сdt-labellerдля обнаружения функций на основе DT (узлы маркируют себя объединенным набором функций).
Эти различные шаблоны развертывания более подробно рассматриваются в следующем разделе.
NFD в качестве основного развертывания
Стандартный шаблон развертывания - запускать NFD как Deployment на мастере Kubernetes, который будет планировать рабочих как DaemonSet на каждом рабочем узле. В этом сценарии узлы обнаруживают свои функции с помощью локального для узла экземпляра nfd-worker и объявляют обнаруженные функции экземпляру nfd-master, запущенному на главном сервере Kubernetes, который, в свою очередь, отвечает за применение меток к рабочим узлам. Этот шаблон развертывания проиллюстрирован следующим образом:

Хотя эта модель является стандартной, она не справляется с некоторыми задачами, связанными с развертыванием Edge:
- Для обновления и поддержания состояния метки требуется постоянное соединение с мастером Kubernetes, которое может прерываться или периодически прерываться при развертывании на основе Edge.
- Он был в основном разработан с учетом традиционных облачных развертываний - в основном, облачных узлов на базе x86_64 с PCI, SR-IOV и другими аналогичными функциями, которые обычно можно ожидать в системах серверного класса.
- Функции, которые чаще встречаются на пограничных шлюзах и SBC, недостаточно хорошо фиксируются или раскрываются, что требует более тесной связи с
dt-labeller.
NFD как автономный модуль
Помимо этого, NFD также предоставляет альтернативную модель развертывания, нацеленную на самомаркировку узлов. В этом случае nfd-master и nfd-worker объединяются в один модуль и развертываются как DaemonSet на каждом узле. Пример этого шаблона представлен ниже:
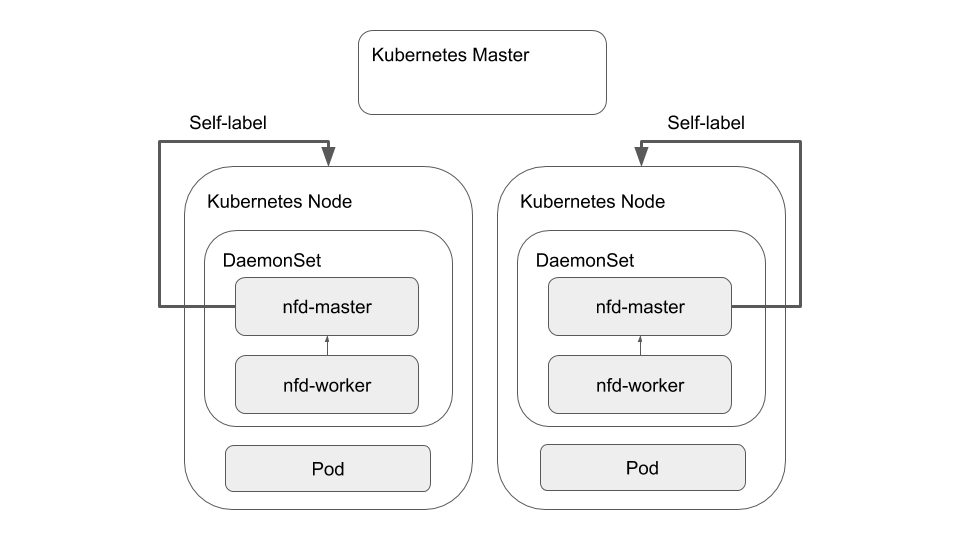
хотя эта модель развертывания решает проблему прерывистого подключения, остальные ограничения, упомянутые выше, по-прежнему применяются.
NFD как автономный модуль с DT Feature Discovery
Чтобы получить лучшее из обоих миров, необходима тесная связь между NFD и dt-labeller. Одной из уникальных функций NFD является local источник функций, который позволяет обнаруживать настраиваемые функции либо с помощью исполняемого механизма перехвата, либо с помощью плоских файлов с парами метка / значение. Поскольку dt-labeller уже имеет механизм для выполнения пробного запуска и сброса обнаруженных пар метка / значение для целей тестирования, его тривиально расширяют, чтобы записать функции таким образом, чтобы они могли быть непосредственно проанализированы nfd-worker.
Основываясь на автономном шаблоне Pod, мы можем дополнительно вставить dt-labeller в тот же Pod, чтобы включить передачу функций. Еще одним преимуществом является то, что, хотя dt-labeller требует привилегированного доступа для доступа к /sys/firmware, это можно смягчить, запустив его в однократном режиме с initContainer, сохранив обнаруженные функции в общем томе и позволив контейнерам NFD взять на себя управление в непривилегированном контексте безопасности - что в конечном итоге позволяет нам снизить риск безопасности, связанный с наличием длительно работающих контейнеров с расширенными привилегиями, сохраняя при этом полную функциональность. Пример комбинированной модели развертывания приведен ниже:

эту модель можно развернуть напрямую, используя шаблон, предоставленный k8s-dt-node-labeller:
$ kubectl apply -f https://raw.githubusercontent.com/adaptant-labs/k8s-dt-node-labeller/k8s-dt-labeller-nfd.yamlили его можно просмотреть в дереве git:
Собираем все вместе: размещение модулей нацелено на гетерогенные ускорители в кластере RPi
Для следующих шагов мы рассмотрим автономный кластер Raspberry Pi, к которому подключено несколько USB-ускорителей AI / ML. В этой конкретной конфигурации у нас есть:
- 4 узла Raspberry Pi 4 Model B
- 1x Intel NCS2 Accelerator (VPU)
- 1x Коралловый USB-ускоритель (EdgeTPU)
Объединение этикеток устройств Devicetree и NFD
При работе на RPi нас интересуют не только базовая модель и детали ЦП, но также тип ГП, количество и тип ядер ЦП, поскольку это точки данных, которые можно использовать для определения конкретных оптимизаций, которые можно применить. (наш фокус в рамках проекта SODALITE H2020). Мы можем протестировать эту конфигурацию, чтобы увидеть, какие метки обнаруживает dt-labeller:
$ k8s-dt-node-labeller -d -n gpu cpu Discovered the following devicetree properties: beta.devicetree.org/brcm-bcm2711-vc5: 1 beta.devicetree.org/arm-cortex-a72: 4 beta.devicetree.org/raspberrypi-4-model-b: 1 beta.devicetree.org/brcm-bcm2711: 1
Это выглядит как разумная отправная точка, поэтому мы обязательно включаем эти дополнительные спецификации узла DT в качестве аргументов для этикетировщика при развертывании.
Если мы посмотрим на журналы для dt-labeller, мы увидим, что он обнаружил особенности и выписал их:
$ kubectl logs nfd-tdzl9 --namespace node-feature-discovery dt-labeller Writing out discovered features to /etc/kubernetes/node-feature-discovery/features.d/devicetree-features
Проделав то же самое для nfd-worker, мы увидим, что он успешно взял метки и отправил их nfd-master для маркировки:
2020/05/21 20:54:59 beta.devicetree.org/brcm-bcm2711-vc5 = 1 2020/05/21 20:54:59 beta.devicetree.org/arm-cortex-a72 = 4 2020/05/21 20:54:59 beta.devicetree.org/raspberrypi-4-model-b = 1 2020/05/21 20:54:59 beta.devicetree.org/brcm-bcm2711 = 1 2020/05/21 20:54:59 Sending labeling request to nfd-master
Хотя этот процесс повторяется для каждого узла в кластере, NFD обнаруживает подключенные USB-ускорители на двух из узлов:
2020/05/21 20:55:14 usb-fe_1a6e_089a.present = true 2020/05/21 20:55:23 usb-ff_03e7_2485.present = true
и маркирует узлы соответственно:
$ kubectl describe node rpi-cluster-node2
Name: rpi-cluster-node2
Roles: <none>
Labels: beta.devicetree.org/brcm-bcm2711-vc5=1
beta.devicetree.org/arm-cortex-a72=4
beta.devicetree.org/raspberrypi-4-model-b=1
beta.devicetree.org/brcm-bcm2711=1
beta.kubernetes.io/arch=arm64
beta.kubernetes.io/instance-type=k3s
beta.kubernetes.io/os=linux
k3s.io/hostname=rpi-cluster-node2
k3s.io/internal-ip=192.168.188.100
kubernetes.io/arch=arm64
feature.node.kubernetes.io/usb-fe_1a6e_089a.present=true
...
$ kubectl describe node rpi-cluster-node3
Name: rpi-cluster-node3
Roles: <none>
Labels: beta.devicetree.org/brcm-bcm2711-vc5=1
beta.devicetree.org/arm-cortex-a72=4
beta.devicetree.org/raspberrypi-4-model-b=1
beta.devicetree.org/brcm-bcm2711=1
beta.kubernetes.io/arch=arm64
beta.kubernetes.io/instance-type=k3s
beta.kubernetes.io/os=linux
k3s.io/hostname=rpi-cluster-node3
k3s.io/internal-ip=192.168.188.101
kubernetes.io/arch=arm64
feature.node.kubernetes.io/usb-ff_03e7_2485.present=true
...
Теперь мы можем приступить к написанию критериев выбора узла, которые будут их использовать.
В прошлой статье одной из целей была плата Coral AI Dev, которая включает EdgeTPU в качестве устройства, подключенного к PCI, но для которой мы также можем просто использовать модель платы в качестве дополнительного критерия.
Мы всегда должны помнить о различных методах присоединения, которые ускоритель может иметь в кластере при определении критериев выбора узла, так что мы можем определить это один раз и разрешить планирование модулей независимо от того, какая конкретная конфигурация узла в конечном итоге может удовлетворить Это.
Выбор узла против привязки к узлу
Ранее мы рассматривали использование nodeSelector в качестве основы для определения все более строгих критериев отбора. Преимущество этого подхода не только в том, что он довольно прост, но и в том, что он позволяет детально размещать контейнеры, оптимизированные для очень специфических конфигураций. В случае, если мы хотим ограничить контейнер Raspberry Pi 4 Model B с USB-подключенным ускорителем Intel NCS2 Accelerator, это можно выразить следующим образом:
Однако это можно было бы сделать более общим - скажем, мы хотим нацелить NCS2 на любой узел с поддержкой ARM64, или у нас есть определенные оптимизации, которые применяются только к определенному типу ядра ARM. Каждый из этих аспектов может быть зафиксирован и выражен через nodeSelector, используя метки, предоставленные DT.
Хотя nodeSelector - это самый упрощенный способ выделить определенные узлы, стоит подчеркнуть, что он следует подходу логического И - каждая из меток должна быть удовлетворена для того, чтобы Pod был запланирован. В случае, когда ресурс всегда прикрепляется одним и тем же способом или у нас очень специфические требования к размещению, этот подход подходит. Однако, как мы видим в случае с EdgeTPU, EdgeTPU может быть подключен и обнаружен несколькими способами.
Чтобы решить эту проблему, мы должны использовать немного более сложный nodeAffinity, который позволяет определять сходство узлов с помощью набора меток с использованием подхода логического ИЛИ. Пока узел может удовлетворить одну из требуемых меток, Pod может быть запланирован. Пример размещения http-echo Pod на любом узле с EdgeTPU можно увидеть ниже:
Спецификация под requiredDuringSchedulingIgnoredDuringExecution гарантирует, что выбор ДОЛЖЕН быть выполнен для того, чтобы Pod был запланирован. В случае, когда это планирование является только предпочтительным (возможно, приложение имеет встроенный механизм отката на случай недоступности ресурса), мы можем вместо этого использовать preferredDuringSchedulingIgnoredDuringExecution, который делает все возможное для планирования на совпадающем узле, но по-прежнему будет планировать на любой другой доступный узел, если это не удается. Мы можем использовать этот подход, когда критерии выбора ДОЛЖНЫ быть выполнены, но не должны.
Более подробную информацию о сродстве узлов можно найти здесь.
Заключение
Мы видим, что комбинация NFD и k8s-dt-node-labeller способна предоставить более комплексное решение для маркировки узлов, которое может раскрыть не только базовые функции платформы пограничных шлюзов, но также и подключенных устройств для целевого использования во время развертывания оптимизированных контейнеров.
Различия в подходах к логическому сопоставлению между терминами селектора узла и сходства узлов обеспечивают гибкость, необходимую для предоставления всего, от детальных ограничений размещения до слабо определенных требований к оборудованию, которые могут быть удовлетворены различными способами в течение срока службы кластера.
Хотя еще предстоит проделать некоторую работу, большая часть функций, необходимых для работы с гетерогенными средами на Edge, уже внедрена и готова к экспериментам.