В каждом выпуске этой серии мы пытались понять и углубиться в компромиссы того, что мы изучаем.
Когда мы изучали структуры данных, мы рассматривали плюсы и минусы каждой структуры, чтобы упростить и сделать более очевидным для нас определение типов проблем, для решения которых была создана эта структура. Точно так же, когда мы изучали алгоритмы сортировки, мы много внимания уделяли компромиссу между эффективностью пространства и времени, чтобы помочь нам понять, когда один алгоритм может быть лучшим выбором по сравнению с другим.
Оказывается, это будет происходить все чаще и чаще, поскольку мы начинаем рассматривать еще более сложные структуры и алгоритмы, некоторые из которых были изобретены как решения супер конкретных проблем. Фактически, сегодняшняя структура данных основана на другой структуре, с которой мы уже знакомы; однако он был создан для решения конкретной проблемы. В частности, он был создан как компромисс между бегущим временем и пространством - двумя вещами, с которыми мы хорошо знакомы в контексте нотации Big O.
Итак, что это за загадочная структура, о которой я так неопределенно говорю, но на самом деле не называю? Время покопаться и узнать!
Примерка на попытки
Есть несколько различных способов изобразить что-то столь же простое, как набор слов. Например, хеш или словарь - это те, с которыми мы, вероятно, знакомы, как и хеш-таблица. Но есть еще одна структура, которая была создана для решения самой проблемы представления набора слов: trie. Термин trie происходит от слова re trie val и обычно произносится как попытка, чтобы отличить его от других древовидных структур.
Тем не менее, дерево в основном представляет собой древовидную структуру данных, но у него есть лишь несколько правил, которым нужно следовать с точки зрения того, как оно создается и используется.

Trie - это древовидная структура данных, в узлах которой хранятся буквы алфавита. Структурируя узлы определенным образом, слова и строки могут быть извлечены из структуры, пройдя путь ветви дерева.
Попытки в контексте информатики - дело относительно новое. Впервые они были рассмотрены в вычислительной технике еще в 1959 году, когда француз по имени Рене де ла Брианэ предложил их использовать. Согласно исследованию Дональда Кнута в The Art of Computer Programming:
Память Trie для компьютерного поиска была впервые рекомендована Рене де ла Брианэ. Он указал, что мы можем сэкономить место в памяти за счет времени выполнения, если мы используем связанный список для каждого вектора узла, поскольку большинство записей в векторах, как правило, пусты.
Первоначальная идея использования попыток в качестве вычислительной структуры заключалась в том, что они могли быть хорошим компромиссом между временем выполнения и памятью. Но мы вернемся к этому чуть позже. Во-первых, давайте сделаем шаг назад и попробуем понять, как именно выглядит эта структура в начале.

Мы знаем, что попытки часто используются для представления слов в алфавите. На показанной здесь иллюстрации мы можем начать понимать, как именно работает это представление.
Каждое дерево имеет пустой корневой узел со ссылками (или ссылками) на другие узлы - по одной для каждого возможного буквенного значения.
Форма и структура дерева всегда представляют собой набор связанных узлов, соединяющихся обратно с пустым корневым узлом. Важно отметить, что количество дочерних узлов в дереве полностью зависит от общего количества возможных значений. Например, если мы представляем английский алфавит, то общее количество дочерних узлов напрямую связано с общим количеством возможных букв. В английском алфавите 26 букв, поэтому общее количество дочерних узлов будет 26.
Однако представьте, что мы создаем дерево для хранения слов из кхмерского (камбоджийского) алфавита, который является самым длинным из известных алфавитов с 74 символами. В этом случае корневой узел будет содержать 74 ссылки на 74 других дочерних узла.
Размер дерева напрямую коррелирует с размером всех возможных значений, которые может представлять дерево.
Итак, дерево может быть довольно маленьким или большим, в зависимости от того, что оно содержит. Но до сих пор мы говорили только о корневом узле, который пуст. Так где же живут буквы разных слов, если их все не в корневом узле?
Ответ на этот вопрос заключается в ссылках корневого узла на его дочерние элементы. Давайте подробнее рассмотрим, как выглядит отдельный узел в дереве, и, надеюсь, это станет более ясным.

В показанном здесь примере у нас есть дерево с пустым корневым узлом, которое имеет ссылки на дочерние узлы. Если мы посмотрим на поперечное сечение одного из этих дочерних узлов, мы заметим, что один узел в дереве содержит только две вещи:
- Значение, которое может быть
null - Массив ссылок на дочерние узлы, все из которых также могут быть
null
Каждый узел в дереве, включая сам корневой узел, имеет только эти два аспекта. Когда создается дерево, представляющее английский язык, оно состоит из единственного корневого узла, значение которого обычно устанавливается равным пустой строке: "".
Этот корневой узел также будет иметь массив, содержащий 26 ссылок, все из которых сначала будут указывать на null. По мере роста дерева эти указатели начинают заполняться ссылками на другие узлы узлов, пример которых мы скоро увидим.
Особенно интересен способ представления этих указателей или ссылок. Мы знаем, что каждый узел содержит массив ссылок / ссылок на другие узлы. Что круто, так это то, что мы можем использовать индексы массива для поиска конкретных ссылок на узлы. Например, наш корневой узел будет содержать массив индексов от 0 до 25, поскольку существует 26 возможных слотов для 26 букв алфавита. Поскольку алфавит в порядке, мы знаем, что ссылка на узел, который будет содержать букву A, будет жить по индексу 0.
Итак, когда у нас есть корневой узел, что нам делать дальше? Пришло время попробовать вырастить наше дерево!
Попытка обхода дерева
Дерево, в котором нет ничего, кроме корневого узла, просто неинтересно! Итак, давайте еще больше усложним ситуацию, поиграв с деревом, в котором есть несколько слов, не так ли?
В приведенном ниже дереве мы представляем детский стишок, который начинается с чего-то вроде «Питер Пайпер сорвал кусочек маринованного перца». Я не буду пытаться заставить вас вспомнить остальное, в основном потому, что это сбивает с толку и у меня болит голова.
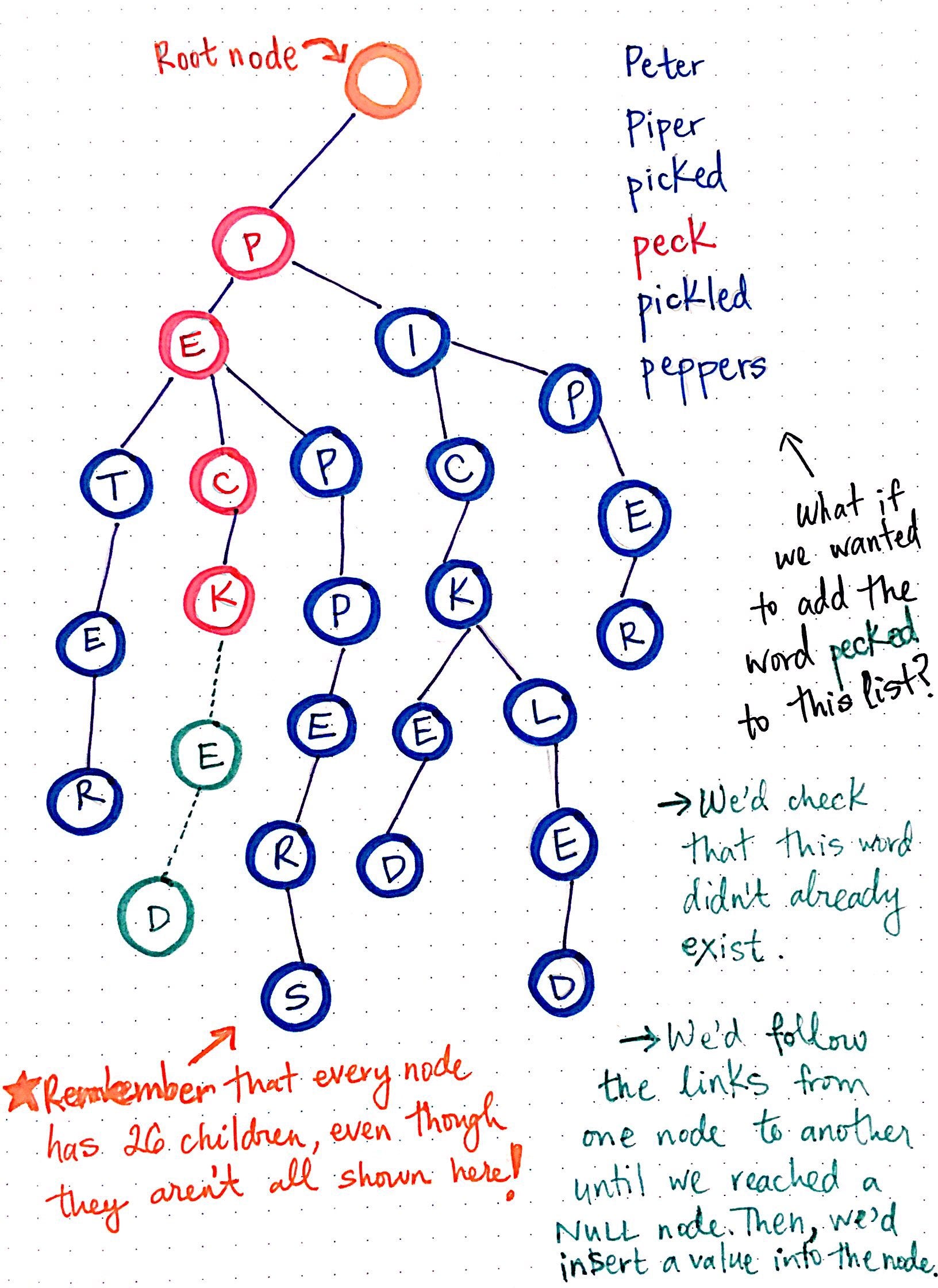
Глядя на наше дерево, мы видим, что у нас есть пустой корневой узел, что типично для структуры дерева. У нас также есть шесть разных слов, которые мы представляем в этом дереве: Peter, piper, picked, peck, pickled и peppers.
Чтобы упростить просмотр этого дерева, я нарисовал только те ссылки, в которых действительно есть узлы; важно помнить, что, хотя они здесь не показаны, каждый отдельный узел имеет 26 ссылок на возможные дочерние узлы.
Обратите внимание на шесть различных «ветвей» этого дерева, по одной для каждого слова, которое представлено. Мы также можем видеть, что некоторые слова разделяют родительские узлы. Например, все ветви для слов Peter, peck и peppers имеют общие узлы для p и для e. Точно так же путь к слову picked и pickled разделяет узлы p, i, c и k.
Итак, что, если бы мы хотели добавить слово pecked в этот список слов, представленных этим деревом? Для этого нам нужно сделать две вещи:
- Во-первых, нам нужно проверить, что слово
peckedеще не существует в этом дереве. - Затем, если мы прошли вниз по ветке, где это слово должно находиться, а слова еще не существует, мы вставим значение в ссылку узла, куда должно идти слово. В этом случае мы вставим
eиdв правильные ссылки.
Но как на самом деле проверить, существует ли это слово? И как вставить буквы на их правильные места? Это легче понять на примере небольшого дерева, поэтому давайте посмотрим на пустое дерево и попробуем что-нибудь вставить в него.
Мы знаем, что у нас будет пустой корневой узел, который будет иметь значение "", и массив с 26 ссылками в нем, все из которых будут пустыми (указывающими на null) для начала. Допустим, мы хотим вставить слово "pie" и присвоить ему значение 5. Другой способ подумать об этом - это то, что у нас есть хэш, который выглядит так: { "pie": 5 }.

Мы проработаем ключ, используя каждую букву для построения нашего дерева и добавления узлов по мере необходимости.
Сначала мы найдем указатель для p, поскольку первая буква в нашем ключе "pie" - это p. Поскольку в этом дереве пока ничего нет, ссылка на p в нашем корневом узле будет null. Итак, мы создадим новый узел для p, а корневой узел теперь имеет массив с 25 пустыми слотами и 1 слот (с индексом 15), который содержит ссылку на узел.
Теперь у нас есть узел с индексом 15, содержащий значение для p. Но наша строка "pie", так что мы еще не закончили. Мы сделаем то же самое для этого узла: проверим, есть ли нулевой указатель на следующей букве ключа: i. Поскольку мы встретили еще одну пустую ссылку для ссылки в i, мы создадим еще один новый узел. Наконец, мы подошли к последнему символу нашего ключа: e в "pie". Мы создаем новый узел для ссылки на массив на e, и внутри этого третьего узла, который мы создали, мы устанавливаем наше значение: 5.
В будущем, если мы захотим получить значение ключа "pie", мы будем перемещаться от одного массива к другому, используя индексы для перехода от узлов p к i, к e; когда мы дойдем до узла по индексу для e, мы прекратим обход и получим значение из этого узла, которым будет 5.

Давайте посмотрим, как будет выглядеть поиск в нашем недавно созданном дереве!
На показанной здесь иллюстрации, если мы ищем ключ "pie", мы просматриваем массив каждого узла и ищем, есть ли значение для пути ветвления: p-i-e. Если у него есть значение, мы можем просто вернуть его. Иногда это называют попаданием в поиск, поскольку нам удалось найти значение для ключа.
Но что, если мы будем искать то, чего не существует в нашем дереве? Что, если мы будем искать слово "pi", которое мы не добавили в качестве ключа со значением? Итак, мы перейдем от корневого узла к узлу с индексом p, а затем перейдем от узла с номером p к узлу с индексом i. Когда мы дойдем до этой точки, мы увидим, имеет ли узел на пути ветвления p-i значение. В этом случае у него нет значения; он указывает на null. Итак, мы можем быть уверены, что ключ "pi" не существует в нашем дереве в виде строки со значением. Это часто называют промахом при поиске, поскольку мы не смогли найти значение для ключа.
Наконец, есть еще одно действие, которое мы могли бы сделать с нашим деревом: удалить объекты! Как мы можем удалить ключ и его значение из нашей trie-структуры? Чтобы проиллюстрировать это, я добавил еще одно слово в наше дерево. Теперь у нас есть оба ключа "pie" и "pies", каждый со своими значениями. Допустим, мы хотим удалить ключ "pies" из нашего дерева.

Для этого нам нужно сделать два шага:
- Во-первых, нам нужно найти узел, содержащий значение для этого ключа, и установить его значение равным
null. Это означает переход вниз и поиск последней буквы слова"pies", а затем сброс значения последнего узла с12наnull. - Во-вторых, нам нужно проверить ссылки узла и убедиться, что все его указатели на другие узлы также
null. Если все они пусты, это означает, что ниже этого нет других слов / веток, и все они могут быть удалены. Однако если есть указатели для других узлов, которые имеют значения, мы не хотим удалять узел, для которого мы только что установилиnull.
Эта последняя проверка особенно важна для того, чтобы не удалять более длинные строки, когда мы удаляем подстроки слова. Но кроме этого единственного чека, ничего больше!
Пробуем свои силы в попытках
Когда я впервые узнал о попытках, они напомнили мне множество хеш-таблиц, о которых мы узнали ранее в этой серии. Фактически, чем больше я читал о попытках и о том, как их строить и искать в них, тем больше я задавался вопросом, каковы на самом деле компромиссы между двумя структурами.

Как оказалось, и попытки, и хеш-таблицы напоминают друг друга, потому что они обе используют массивы под капотом. Однако хеш-таблицы используют массивы в сочетании со связанными списками, тогда как попытки использовать массивы в сочетании с указателями / ссылками.
Между этими двумя структурами есть довольно много незначительных различий, но наиболее очевидное различие между хэш-таблицами и попытками состоит в том, что trie не нуждается в хеш-функции, потому что каждый ключ может быть представлен по порядку (в алфавитном порядке), и однозначно извлекается, поскольку каждый путь перехода к значению строки будет уникальным для этого ключа. Побочным эффектом этого является то, что нет коллизий, с которыми нужно иметь дело, и, таким образом, достаточно полагаться на индекс массива, а функция хеширования не нужна.
Однако, в отличие от хеш-таблиц, обратная сторона дерева состоит в том, что оно занимает много памяти и места с пустыми (null) указателями. Мы можем представить, как большое дерево начнет расти в размерах, и с каждым добавленным узлом также потребуется инициализировать весь массив, содержащий 26 null указателей. Для более длинных слов эти пустые ссылки, вероятно, никогда не будут заполнены; например, представьте, что у нас есть ключ Honorificabilitudinitatibus с некоторым значением. Это очень длинное слово, и мы, вероятно, не собираемся добавлять какие-либо другие ответвления к этому слову в дереве; это набор пустых указателей для каждой буквы этого слова, которые занимают место, но на самом деле никогда не используются!

Надеюсь, мы не будем использовать слово «Honorificabilitudinitatibus» в качестве строки.
Однако у использования попыток есть некоторые большие преимущества. Во-первых, основная работа по созданию дерева выполняется на ранней стадии. Это имеет смысл, если подумать, потому что, когда мы впервые добавляем узлы, нам каждый раз приходится делать тяжелую работу по выделению памяти для массива. Но по мере увеличения размера дерева нам приходится каждый раз выполнять меньше работы, чтобы добавить значение, поскольку вполне вероятно, что мы уже инициализировали узлы, их значения и ссылки. Добавление «промежуточных узлов» становится намного проще, поскольку ветви дерева уже созданы.
Еще один факт в «столбце pro» для попыток заключается в том, что каждый раз, когда мы добавляем букву слова, мы знаем, что нам нужно будет просмотреть только 26 возможных индексов в массиве узла, поскольку в английском языке всего 26 возможных букв. алфавит. Несмотря на то, что 26 кажется большим количеством, для наших компьютеров это действительно не так места. Однако тот факт, что мы уверены в том, что каждый массив когда-либо будет содержать только 26 ссылок, является огромным преимуществом, потому что это число никогда не изменится в контексте нашего дерева! Это постоянное значение.
В связи с этим давайте быстро взглянем на временную сложность Big O структуры данных trie. Время, необходимое для создания дерева, напрямую зависит от того, сколько слов / ключей содержит дерево и какова длина этих ключей. Наихудшая среда выполнения для создания дерева - это комбинация m, длины самого длинного ключа в дереве, и n, общего количества ключей в дереве. . Таким образом, наихудшее время выполнения создания дерева - O (mn).

Сложность поиска, вставки и удаления из дерева зависит от длины слова a, которое ищется, вставляется или удаляется, и общего количества слов, n , делая время выполнения этих операций O (an). Конечно, для самого длинного слова в дереве вставка, поиск и удаление потребуют больше времени и памяти, чем для самого короткого слова в дереве.
Итак, теперь, когда мы знаем всю внутреннюю работу попыток, остается ответить на один вопрос: где используются попытки? Что ж, правда в том, что они редко используются исключительно; обычно они используются в сочетании с другой структурой или в контексте алгоритма. Но, пожалуй, самый крутой пример того, как попытки можно использовать для их формы и функций, - это функции автозаполнения, подобные той, что используется в поисковых системах, таких как Google.

Теперь, когда мы знаем, как работает пытается, мы можем представить, как ввод двух букв в поле поиска приведет к получению подмножества гораздо большей структуры дерева. Еще одним мощным аспектом этого является то, что попытки упростить поиск подмножества элементов, поскольку, подобно двоичным деревьям поиска, каждый раз, когда мы перемещаемся вниз по ветви дерева, мы вырезаем количество другие узлы, которые нам нужно посмотреть! Стоит отметить, что поисковые системы, вероятно, более сложны в своих попытках, поскольку они будут возвращать определенные термины в зависимости от их популярности и, вероятно, имеют некоторую дополнительную логику для определения веса, связанного с определенными терминами в их структурах дерева. Но под капотом они, вероятно, пытаются сделать это волшебство!
Попытки также используются для алгоритмов сопоставления и реализации таких вещей, как проверка орфографии, а также могут использоваться для реализации версий поразрядной сортировки.
Я полагаю, что если мы будем стараться достаточно сильно, мы увидим, что попытки окружают нас! (Извините, я просто не смог устоять перед каламбуром)
Ресурсы
Попытки часто появляются в вопросах на белой доске или технических собеседованиях, часто в некоторых вариациях вопроса, таких как «поиск строки или подстроки в этом предложении». Учитывая их уникальную способность извлекать элементы в постоянное время, они часто являются отличным инструментом для использования, и, к счастью, многие люди писали о них. Если вам нужны полезные ресурсы, вот несколько хороших мест для начала.
- Сортировка цифр и структуры данных, профессор Аврим Блюм
- Конспект лекций о попытках, профессор Франк Пфеннинг
- Алгоритмы: попытки, Роберт Седжвик и Кевин Уэйн
- Попытки, блестящее обучение
- Попытки, Дэниел Эллард
- Попытки, Гарвардский CS50