Одна из лучших книг, которые мне недавно довелось прочитать, — «Проектирование приложений с интенсивным использованием данных» Мартина Клеппманна. Эта книга стала известна своим всеобъемлющим обзором распределенных систем и исследованием различных компромиссов, связанных с выбором дизайна. На полное прохождение у меня ушло 3 месяца, и много времени на то, чтобы впитать то, чему меня учили. В следующей серии постов я хотел бы обобщить некоторые ключевые идеи, которые я извлек из каждой главы, начиная с моей любимой из всех; транзакции базы данных.
Как мы знаем, с базами данных многое может пойти не так.
- Программное или аппаратное обеспечение базы данных может выйти из строя в любое время (в том числе в процессе записи).
- Приложения могут аварийно завершать работу в любой момент во время операций записи.
- Возможны перебои в сети
- Несколько клиентов одновременно пишут в базу данных, перезаписывая изменения друг друга
- Клиенты могут читать данные, которые не имеют смысла
- Условия гонки между клиентами, вызывающие ошибки
Транзакции — это способ для баз данных защитить приложения от подобных проблем; группируя несколько операций чтения/записи в один логический блок. В вызове API, который записывает в 4 таблицы, поставщик базы данных гарантирует подход «все или ничего», чтобы избежать несоответствий данных. Разработчик приложения должен иметь дело только с двумя исходами: 1) Успех 2) Неудача.
Без этого у нас осталась бы целая цепочка перестановок в коде приложения, например: «Что, если 3 операции записи в базу данных завершатся успешно, а 1 завершится ошибкой? Что, если 2 операции записи завершатся успешно, а 2 — нет?» и Т. Д.
Одной из ключевых тем этой главы является изоляция. Это буква «I» в ACID (Atomic Consistent Isolated Durable). Все это означает, что для базы данных, совместимой с ACID, клиентское приложение может быть уверено, что операции, выполняемые с данными, не будут мешать другим клиентам и другим запросам. Типичное состояние гонки похоже на приведенное ниже. Два пользователя пытаются увеличить один и тот же счетчик, и из-за синхронизации запросов кажется, что произошло только одно увеличение, и данные не отражают «истинное» ожидаемое состояние, которое было бы, если бы эти запросы выполнялись не одновременно. .
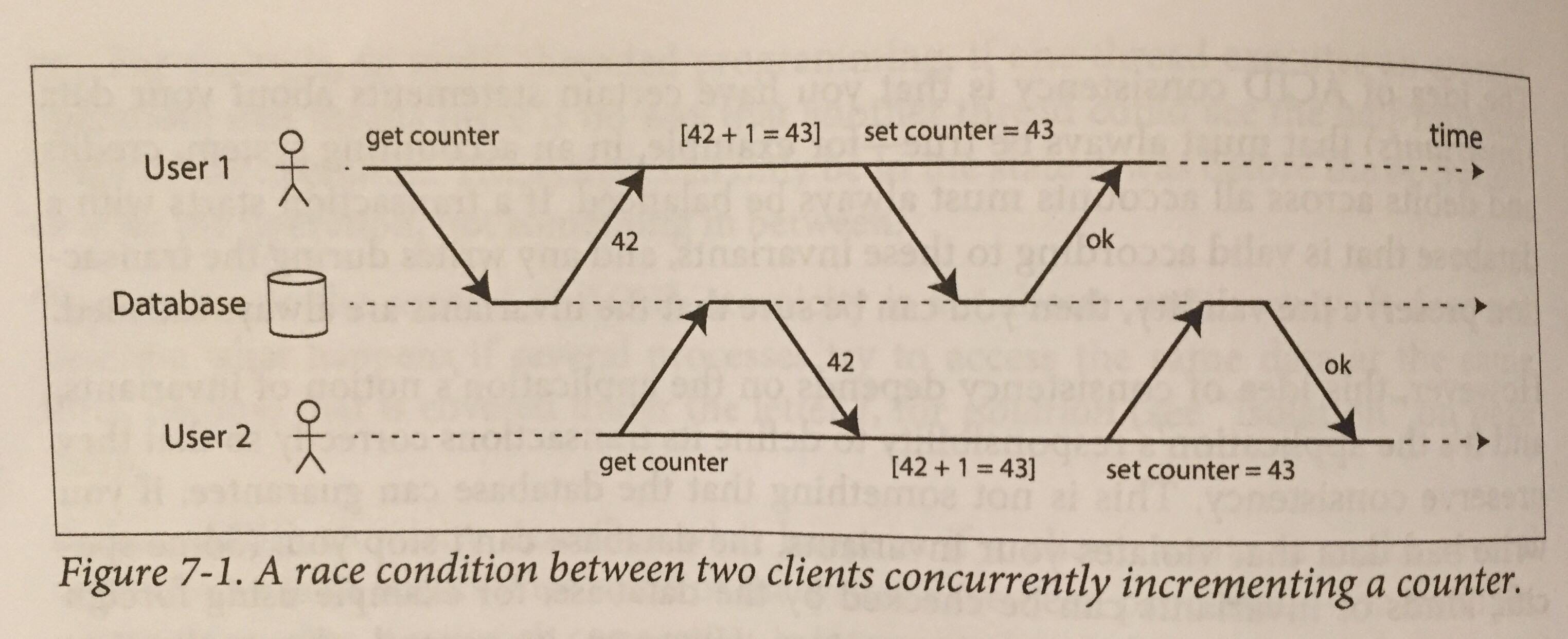
Транзакции имеют разные уровни изоляции и разные степени влияния на производительность, о которых разработчики должны знать при их реализации. Давайте углубимся в некоторые из тех, которые обсуждает Клеппманн.
В этой главе более подробно были рассмотрены 3 уровня изоляции.
- Чтение зафиксированной изоляции
- Изоляция моментальных снимков (также известная как повторяемое чтение)
- Сериализуемая изоляция
Первые два из них известны как «слабые уровни изоляции». Клеппманн предупреждает читателей, что даже несмотря на то, что популярные системы баз данных будут рекламировать свои «ACID-совместимые» транзакции, фактически реализуемые уровни изоляции не всегда являются самыми сильными и могут привести к возникновению условий гонки. Сейчас мы увидим, почему.
Чтение подтверждено
Это самый базовый уровень изоляции транзакций, который дает две гарантии:
- При чтении из базы данных вы увидите только те данные, которые были зафиксированы (без грязных чтений).
- При записи в базу данных вы будете перезаписывать только те данные, которые были зафиксированы (без грязных записей).
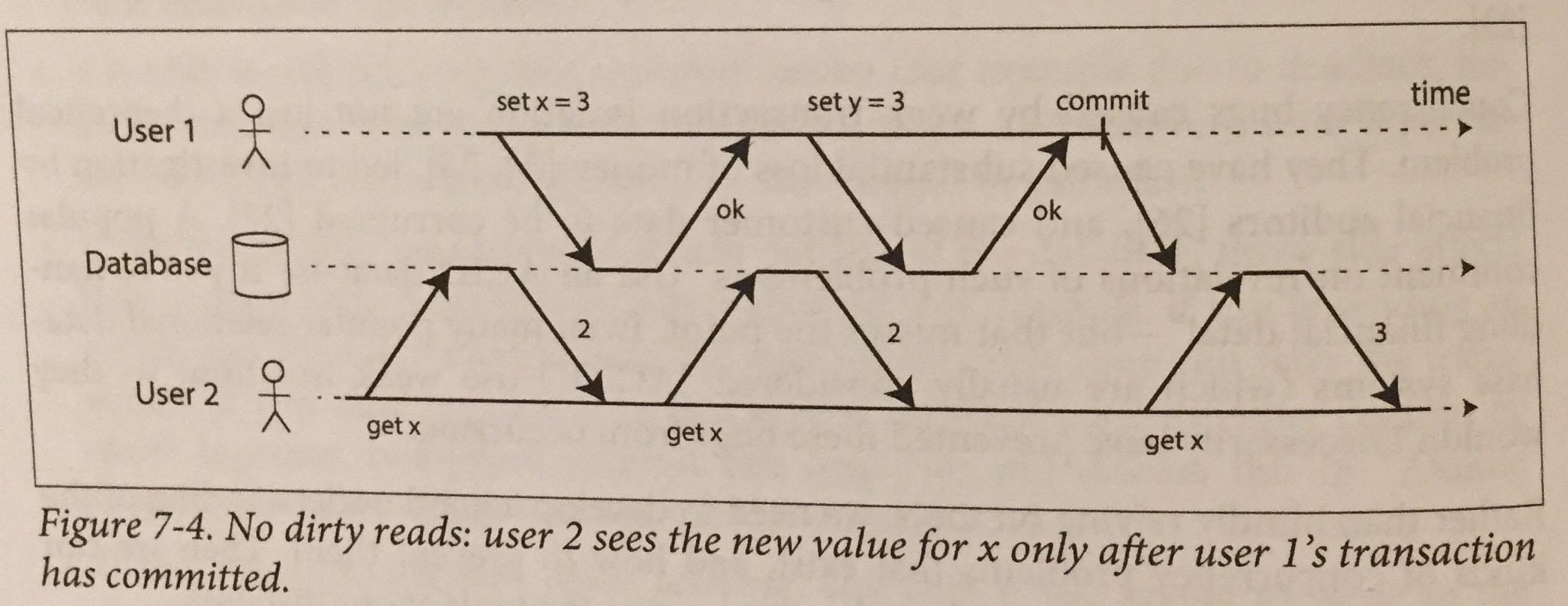
Основная причина предотвращения грязных чтений (незафиксированных чтений) заключается в том, что в случае отката транзакции клиент, прочитавший данные, не остается в замешательстве. Чтение постоянно увеличивающегося счетчика на 5 в одном запросе (где 5 еще не зафиксировано), а затем на 4 в последующем запросе может вызвать всевозможные тонкие ошибки и привести к тому, что клиент будет принимать неверные решения на основе неверных данных. .
Ниже приведен пример изолированного чтения на практике. Без этого уровня изоляции пользователь 2 во втором запросе увидит x = 3, то есть до того, как он будет зафиксирован.
Пример опасностей, вызванных грязной записью, можно увидеть ниже. Представьте себе сценарий, в котором два пользователя пытаются купить один и тот же автомобиль. При выполнении покупки должны произойти две операции записи; первый для обновления списков, а второй для обновления счетов. Без изоляции зафиксированного чтения мы могли бы закончить тем, что пользователи перезаписывают данные, которые еще не были зафиксированы. Таким образом, в нашем случае с покупкой автомобиля система записала бы, что автомобиль продается Бобу, тогда как счет-фактура за покупку был отправлен Алисе.
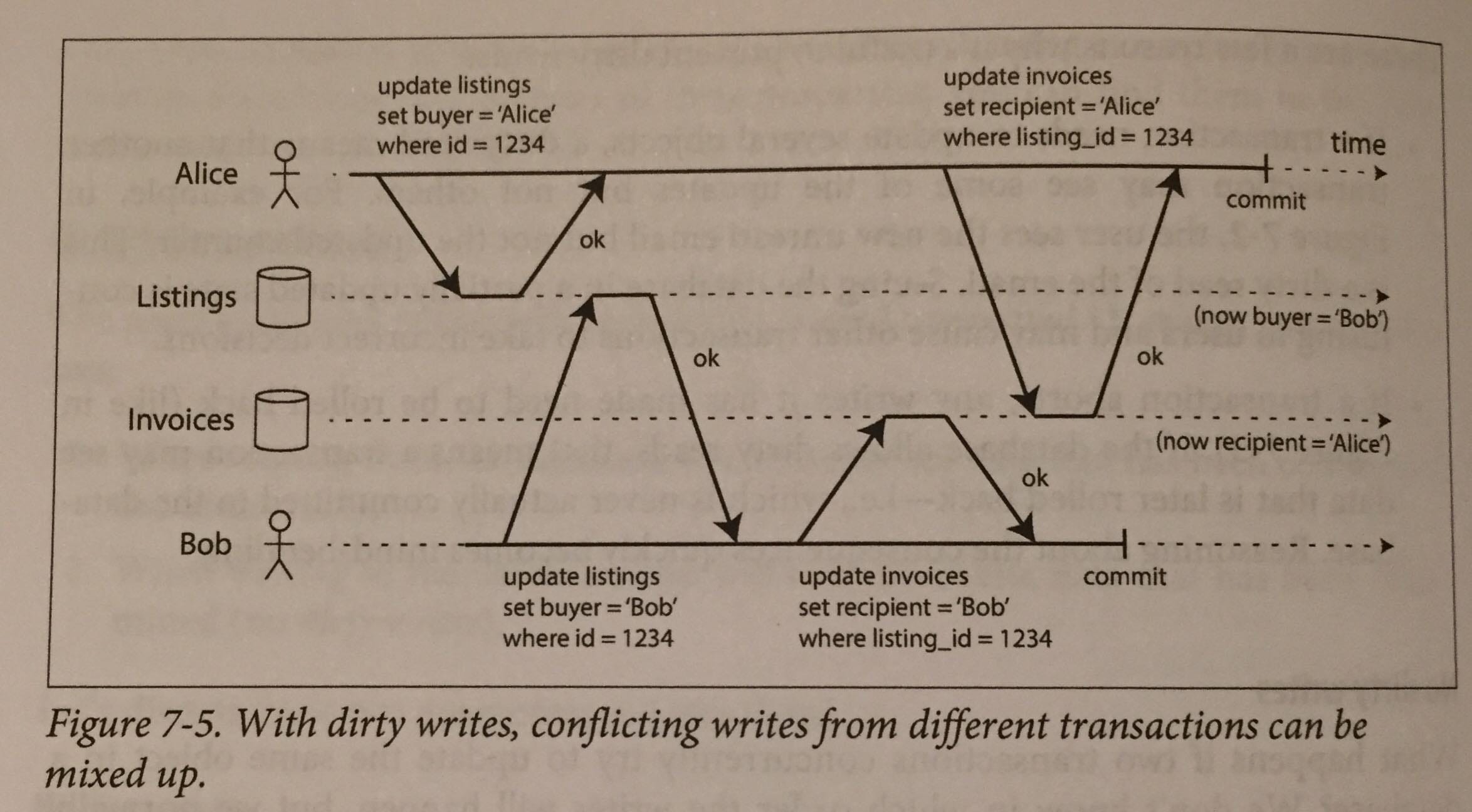
По умолчанию минимальный уровень изоляции, который вы получите от базы данных, — зафиксированное чтение, и это очень популярный уровень изоляции в базах данных от Postgres до Oracle.
Изоляция снимков и повторяющиеся чтения
Легко довольствоваться изоляцией «Read Committed» и думать, что это все, что нужно. К сожалению, условия гонки могут подкрадываться к приложениям, даже если база данных не позволяет одновременным операциям записи наступать друг другу на пятки.
Ниже приведен пример, который, как демонстрирует Клеппманн, может иметь место при изоляции чтения с зафиксированным считыванием; аномалия под названием перекос чтения
У нашего пользователя, Алисы, есть 1000 долларов, разделенных на два счета по 500 долларов на каждом. Она переводит 100 долларов с одного счета на другой, но ей не повезло читать данные с обоих счетов одновременно с обработкой транзакции, а это значит, что она считает, что на обоих у нее есть только 900 долларов.
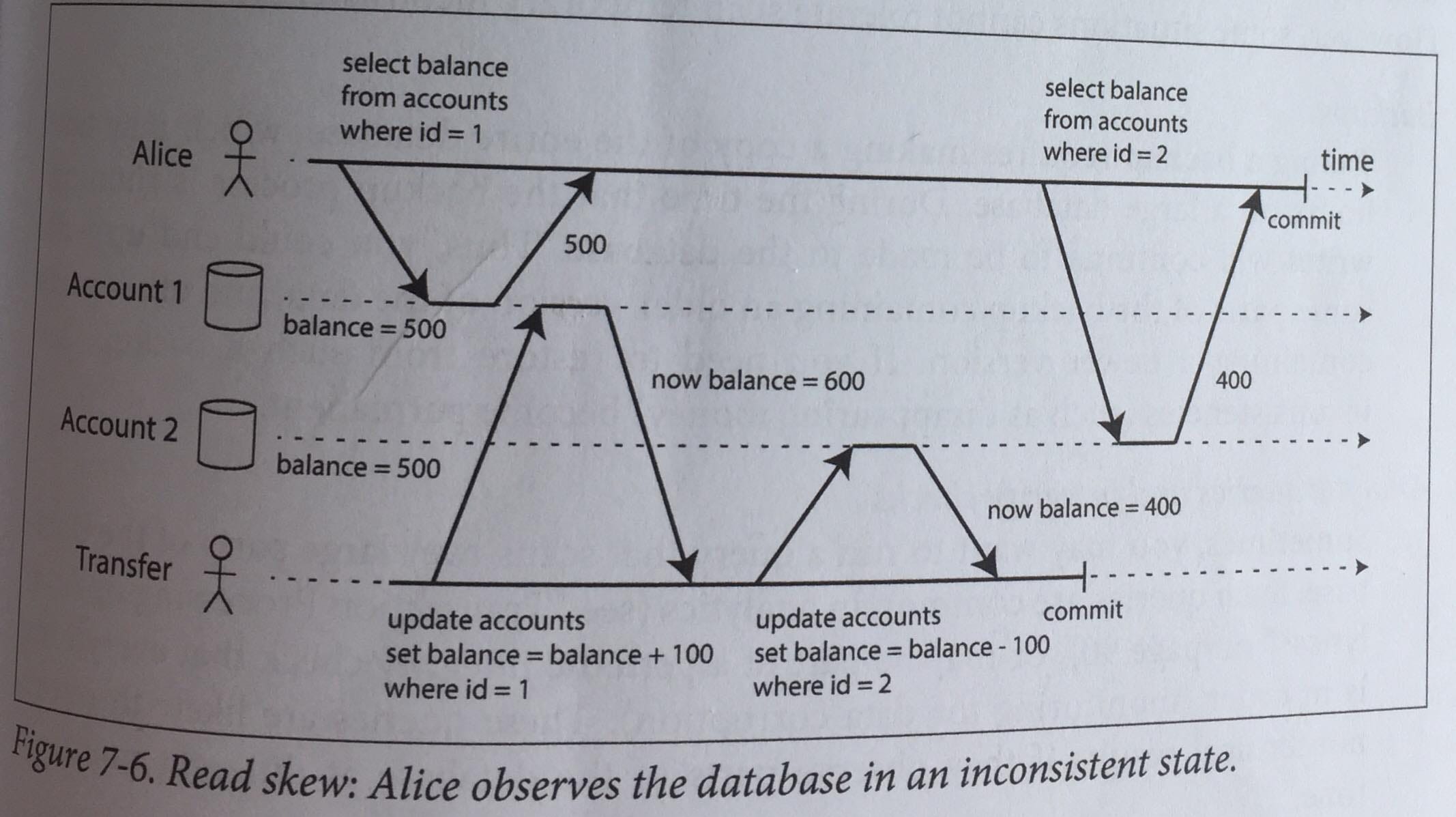
Это пример того, что называется неповторяющимся чтением, и оно все еще может происходить при изолированном чтении. Обычно это считается приемлемым в большинстве случаев, потому что проблема не сохраняется. Когда пользователь перезагрузит страницу, он, скорее всего, снова увидит правильный баланс, и многие приложения могут допускать подобное временное несоответствие. Но не все.
Наиболее распространенным решением этой проблемы является изоляция моментальных снимков. Идея заключается в том, что каждая транзакция будет просматривать данные, которые были зафиксированы в определенный момент времени. Таким образом, пока вы находитесь внутри транзакции, вы будете видеть только те данные, которые были зафиксированы до начала транзакции. Любые последующие изменения не будут отражены внутри процедуры. Обычно это используется для длительных запросов на основе аналитики, которые должны каким-то образом «заморозить» набор данных, чтобы построить точную агрегацию существующих данных, чтобы новые запросы не мешали процессу. Клеппманн пишет: «Очень сложно рассуждать о значении запроса, если данные, с которыми он работает, изменяются одновременно с выполнением запроса».
В этом посте я познакомил вас с двумя наиболее распространенными формами слабой изоляции, которые мы можем использовать в системах баз данных; чтение зафиксированной изоляции и изоляция моментальных снимков. Таким образом, зафиксированное чтение гарантирует отсутствие грязных операций чтения/записи (так что клиенты будут читать и записывать только те данные, которые были зафиксированы, а не данные, которые в настоящее время изменяются в рамках транзакции).
Мы также обсудили некоторые проблемы, связанные с изоляцией подтвержденного чтения, и то, как это все еще может привести к перекосу чтения, как в случае с банковским переводом пользователя. Чтобы решить эту проблему, мы используем изоляцию моментальных снимков, чтобы заставить базу данных просматривать только те данные, которые были зафиксированы до начала транзакции. Диаграмма, приведенная несколькими абзацами выше, показывает, как может возникнуть такое искажение чтения.
В следующем посте я расскажу вам о некоторых проблемах с этими формами изоляции и о том, почему могут потребоваться более строгие уровни в зависимости от вашего варианта использования.