
10 статистических методов, которыми должны овладеть специалисты по данным
Независимо от того, как вы относитесь к сексуальности Data Science, просто невозможно игнорировать непреходящую важность данных и нашу способность анализировать, систематизировать и контекстуализировать их. Опираясь на свои обширные данные о занятости и отзывы сотрудников, Glassdoor поставила Data Scientist №1 в своем списке 25 лучших рабочих мест в Америке. Таким образом, роль остается неизменной, но, несомненно, специфика того, что делает специалист по анализу данных, будет развиваться. Благодаря тому, что такие технологии, как машинное обучение, становятся все более распространенным явлением, а новые области, такие как глубокое обучение, получают значительную поддержку среди исследователей и инженеров - а также компаний, которые их нанимают, - специалисты по данным продолжают находиться на гребне невероятной волны инноваций и технического прогресса.
Хотя хорошие навыки кодирования важны, наука о данных - это не только разработка программного обеспечения (на самом деле, хорошо знакомы с Python, и все готово). Специалисты по обработке данных живут на стыке программирования, статистики и критического мышления. Как сказал Джош Уиллс, специалист по данным - это человек, который лучше разбирается в статистике, чем любой программист, и лучше программирует, чем любой статистик. Я лично знаю слишком много инженеров-программистов, стремящихся перейти к данным. ученым и слепо используют фреймворки машинного обучения, такие как TensorFlow или Apache Spark, для обработки своих данных без глубокого понимания стоящих за ними статистических теорий. Так начинается изучение статистического обучения, теоретической основы машинного обучения, основанной на статистике и функциональном анализе.
Зачем изучать статистическое обучение? Важно понимать идеи, лежащие в основе различных методов, чтобы знать, как и когда их использовать. Сначала нужно понять более простые методы, чтобы понять более сложные. Важно точно оценить эффективность метода, знать, насколько хорошо или плохо он работает. Кроме того, это захватывающая область исследований, имеющая важные приложения в науке, промышленности и финансах. В конечном счете, статистическое обучение - это фундаментальная составляющая в обучении современного специалиста по данным. Примеры задач статистического обучения:
- Определите факторы риска рака простаты.
- Классифицируйте записанную фонему на основе лог-периодограммы.
- Предсказать, будет ли у кого-то сердечный приступ, на основе демографических, диетических и клинических данных.
- Настройте систему обнаружения спама в электронной почте.
- Определите числа в почтовом индексе, написанном от руки.
- Отнесите образец ткани к одному из нескольких классов рака.
- Установите связь между заработной платой и демографическими переменными в данных обследования населения.
В моем последнем семестре в колледже я провел независимое исследование интеллектуального анализа данных. Класс охватывает обширные материалы из 3 книг: Введение в статистическое обучение (Хасти, Тибширани, Виттен, Джеймс), Проведение байесовского анализа данных (Крушке) и Анализ временных рядов и его приложения (Шамвей, Стоффер). Мы сделали много упражнений по байесовскому анализу, цепям Маркова Монте-Карло, иерархическому моделированию, контролируемому и неконтролируемому обучению. Этот опыт углубляет мой интерес к академической сфере интеллектуального анализа данных и убеждает меня в дальнейшем специализироваться на ней. Недавно я прошел Онлайн-курс статистического обучения в Stanford Lagunita, который охватывает весь материал Введение в статистическое обучение, которое я прочитал в своем независимом исследовании. Теперь, когда я дважды ознакомился с контентом, я хочу поделиться 10 статистическими методами из книги, которым, как я считаю, следует научиться любому специалисту по данным, чтобы быть более эффективным в работе с большими наборами данных.
Прежде чем перейти к этим 10 методам, я хочу провести различие между статистическим обучением и машинным обучением. Раньше я писал один из самых популярных постов на Medium о машинном обучении, поэтому уверен, что у меня есть опыт, чтобы обосновать эти различия:
- Машинное обучение возникло как подполе искусственного интеллекта.
- Статистическое обучение возникло как подполе статистики.
- В машинном обучении больше внимания уделяется крупномасштабным приложениям и точности прогнозов.
- Статистическое обучение делает упор на модели и их интерпретируемость, а также на точность и неопределенность.
- Но это различие стало еще более размытым, и теперь происходит много «перекрестного оплодотворения».
- Машинное обучение берет верх в маркетинге!
1 - Линейная регрессия:
В статистике линейная регрессия - это метод прогнозирования целевой переменной путем подбора наилучшего линейного отношения между зависимой и независимой переменной. Для наилучшего соответствия необходимо убедиться, что сумма всех расстояний между фигурой и фактическими наблюдениями в каждой точке как можно меньше. Подгонка формы является «наилучшей» в том смысле, что никакое другое положение не приведет к меньшим ошибкам при выборе формы. Два основных типа линейной регрессии: Простая линейная регрессия и Множественная линейная регрессия . Простая линейная регрессия использует одну независимую переменная для прогнозирования зависимой переменной путем подбора наилучшей линейной зависимости. Множественная линейная регрессия использует более одной независимой переменной для прогнозирования зависимой переменной путем подбора наилучшей линейной связи.
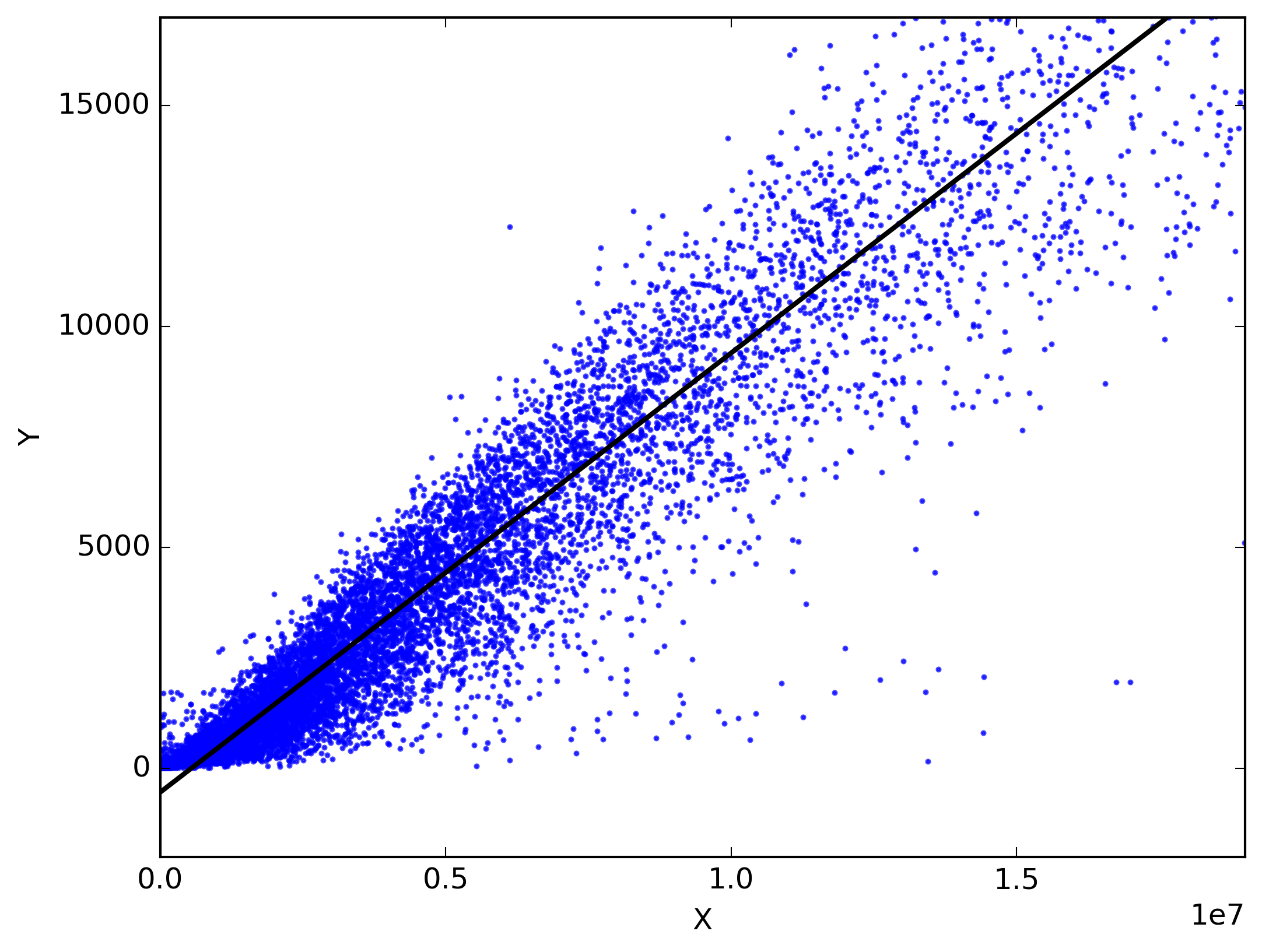
Выберите любые 2 вещи, которые вы используете в повседневной жизни и которые связаны между собой. Например, у меня есть данные о моих ежемесячных расходах, ежемесячном доходе и количестве поездок в месяц за последние 3 года. Теперь мне нужно ответить на следующие вопросы:
- Каковы будут мои ежемесячные расходы в следующем году?
- Какой фактор (ежемесячный доход или количество поездок в месяц) более важен при принятии решения о моих ежемесячных расходах?
- Как ежемесячный доход и поездки в месяц соотносятся с ежемесячными расходами?
2 - Классификация:
Классификация - это метод интеллектуального анализа данных, который присваивает категории набору данных, чтобы помочь в более точных прогнозах и анализе. Классификация, также иногда называемая деревом решений, является одним из нескольких методов, предназначенных для эффективного анализа очень больших наборов данных. Выделяются 2 основных метода классификации: логистическая регрессия и дискриминантный анализ .
Логистическая регрессия - это подходящий регрессионный анализ, который следует проводить, когда зависимая переменная является дихотомической (двоичной). Как и все регрессионные анализы, логистическая регрессия - это прогнозный анализ. Логистическая регрессия используется для описания данных и объяснения взаимосвязи между одной зависимой двоичной переменной и одной или несколькими номинальными, порядковыми, интервальными или пропорциональными независимыми переменными. Типы вопросов, которые можно изучить с помощью логистической регрессии:
- Как изменяется вероятность заболеть раком легких (Да против Нет) с каждым дополнительным фунтом избыточного веса и с каждой пачкой сигарет, выкуриваемых в день?
- Влияют ли калорийность веса тела, потребление жиров и возраст участников на сердечные приступы (да или нет)?

В Дискриминантном анализе 2 или более группы, кластеры или популяции известны априори, и 1 или более новых наблюдений классифицируются в 1 из известных популяций на основе измеренных характеристик. Дискриминантный анализ моделирует распределение предикторов X отдельно в каждом из классов ответов, а затем использует теорему Байеса, чтобы преобразовать их в оценки вероятности категории ответа при заданном значении X. Такие модели могут быть либо линейный или квадратичный .
- Линейный дискриминантный анализ вычисляет «дискриминантные оценки» для каждого наблюдения, чтобы классифицировать, к какому классу переменных ответа оно относится. Эти оценки получаются путем нахождения линейных комбинаций независимых переменных. Предполагается, что наблюдения внутри каждого класса основаны на многомерном распределении Гаусса, а ковариация переменных-предикторов является общей для всех k уровней переменной отклика Y.
- Квадратичный дискриминантный анализ предлагает альтернативный подход. Как и LDA, QDA предполагает, что наблюдения каждого класса Y взяты из гауссовского распределения. Однако, в отличие от LDA, QDA предполагает, что каждый класс имеет свою собственную матрицу ковариаций. Другими словами, не предполагается, что переменные-предикторы имеют общую дисперсию на каждом из k уровней в Y.
3 - Методы передискретизации:
Передискретизация - это метод, который состоит из отрисовки повторяющихся выборок из исходных выборок данных. Это непараметрический метод статистического вывода. Другими словами, метод повторной выборки не включает использование общих таблиц распределения для вычисления приблизительных значений вероятности p.
Повторная выборка создает уникальное распределение выборки на основе фактических данных. Он использует экспериментальные методы, а не аналитические, для создания уникального распределения выборки. Он дает объективные оценки, поскольку основан на объективных выборках всех возможных результатов данных, изученных исследователем. Чтобы понять концепцию повторной выборки, вы должны понимать термины Bootstrapping и Cross-Validation:
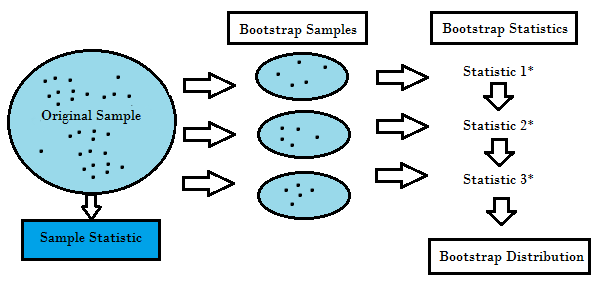
- Начальная загрузка - это метод, который помогает во многих ситуациях, таких как проверка эффективности прогнозирующей модели, методы ансамбля, оценка смещения и дисперсии модели. Он работает путем выборки с заменой исходных данных и берет «не выбранные» точки данных в качестве тестовых примеров. Мы можем сделать это несколько раз и рассчитать средний балл как оценку производительности нашей модели.
- С другой стороны, перекрестная проверка - это метод проверки производительности модели, который выполняется путем разделения обучающих данных на k частей. Мы берем k - 1 частей в качестве обучающей выборки и используем часть «протянутая» в качестве тестовой. Мы повторяем это k раз по-разному. Наконец, мы берем среднее значение k баллов в качестве оценки производительности.
Обычно для линейных моделей обычным методом наименьших квадратов является основной критерий, который следует учитывать при их подборе данных. Следующие 3 метода представляют собой альтернативные подходы, которые могут обеспечить лучшую точность прогноза и интерпретируемость модели для подбора линейных моделей.
4 - Выбор подмножества:
Этот подход определяет подмножество предикторов p, которые, по нашему мнению, связаны с ответом. Затем мы подбираем модель, используя метод наименьших квадратов подмножества функций.

- Выбор наилучшего подмножества. Здесь мы подбираем отдельную регрессию OLS для каждой возможной комбинации предикторов p, а затем смотрим на соответствие полученной модели. Алгоритм разбит на 2 этапа: (1) Подобрать все модели, содержащие k предикторов, где k - максимальная длина моделей, (2) Выбрать один модель с использованием перекрестно проверенной ошибки прогноза. Для оценки соответствия модели важно использовать тестирование или ошибку проверки, а не ошибку обучения, поскольку RSS и R² монотонно увеличиваются с увеличением количества переменных. Лучшим подходом является перекрестная проверка и выбор модели с самым высоким R² и самым низким RSS при оценке ошибок тестирования.
- Прямой пошаговый выбор учитывает гораздо меньшее подмножество предикторов p. Он начинается с модели, не содержащей предикторов, затем добавляет предикторы к модели по одному, пока все предикторы не будут в модели. Порядок добавления переменных - это переменная, которая дает наибольшее дополнительное улучшение подгонки до тех пор, пока никакие переменные не улучшат подгонку модели с использованием перекрестно проверенной ошибки предсказания.
- Обратный пошаговый выбор начинается со всех p предикторов в модели, а затем итеративно удаляется наименее полезный предиктор по одному.
- Гибридные методы используют прямой пошаговый подход, однако после добавления каждой новой переменной метод также может удалять переменные, которые не влияют на соответствие модели.
5 - Усадка:
Этот подход соответствует модели, включающей все предикторы p, однако оценочные коэффициенты уменьшаются до нуля по сравнению с оценками методом наименьших квадратов. Это сокращение, также известное как регуляризация, снижает дисперсию. В зависимости от того, какой тип усадки выполняется, некоторые коэффициенты могут быть оценены как равные нулю. Таким образом, этот метод также выполняет выбор переменной. Двумя наиболее известными методами уменьшения оценок коэффициентов до нуля являются гребенчатая регрессия и лассо.
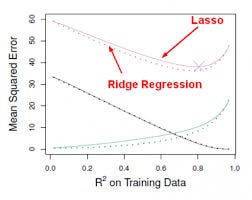
- Риджевая регрессия похожа на метод наименьших квадратов, за исключением того, что коэффициенты оцениваются путем минимизации немного другой величины. Регрессия гребня, как и OLS, ищет оценки коэффициентов, которые уменьшают RSS, однако они также имеют штраф за усадку, когда коэффициенты приближаются к нулю. Этот штраф приводит к уменьшению оценок коэффициентов до нуля. Не вдаваясь в математику, полезно знать, что гребенчатая регрессия сжимает объекты с наименьшей дисперсией пространства столбцов. Как и в случае основного компонентного анализа, гребенчатая регрессия проецирует данные в d направленное пространство, а затем сжимает коэффициенты компонентов с низкой дисперсией больше, чем компоненты с высокой дисперсией, которые эквивалентны наибольшим и наименьшим основным компонентам. .
- У регрессии хребта был по крайней мере один недостаток; в окончательную модель включены все предикторы p. Срок штрафа приведет к тому, что многие из них будут близки к нулю, но никогда не станут точно равными нулю. Обычно это не проблема для точности прогнозов, но может затруднить интерпретацию результатов модели. Лассо преодолевает этот недостаток и может обнулять некоторые коэффициенты при условии, что s достаточно мало. Поскольку s = 1 приводит к регулярной регрессии OLS, по мере того, как s приближается к 0, коэффициенты уменьшаются до нуля. Таким образом, регрессия Лассо также выполняет выбор переменных.
6 - Уменьшение размера:
Уменьшение размерности сводит проблему оценки коэффициентов p + 1 к простой задаче коэффициентов M + 1, где M ‹p. Это достигается путем вычисления M различных линейных комбинаций или проекций переменных. Затем эти M проекции используются в качестве предикторов для соответствия модели линейной регрессии методом наименьших квадратов. Двумя подходами к этой задаче являются регрессия главных компонентов и частичный метод наименьших квадратов.

- Регрессию основных компонентов можно описать как подход к получению низкоразмерного набора характеристик из большого набора переменных. Направление первого главного компонента данных - это наибольшая разница в наблюдениях. Другими словами, первый ПК - это линия, максимально приближенная к данным. Можно уместить p различных основных компонентов. Второй ПК представляет собой линейную комбинацию переменных, которая не коррелирует с первым ПК и имеет наибольшую дисперсию с учетом этого ограничения. Идея состоит в том, что главные компоненты фиксируют наибольшую вариативность данных, используя линейные комбинации данных в последовательно ортогональных направлениях. Таким образом, мы также можем комбинировать эффекты коррелированных переменных, чтобы получить больше информации из доступных данных, тогда как при обычном методе наименьших квадратов нам пришлось бы отбросить одну из коррелированных переменных.
- Описанный выше метод ПЦР включает определение линейных комбинаций X, которые лучше всего представляют предикторы. Эти комбинации (направления) идентифицируются неконтролируемым образом, поскольку ответ Y не используется для определения направлений основных компонентов. То есть ответ Y не контролирует идентификацию основных компонентов, поэтому нет гарантии, что направления, которые лучше всего объясняют предикторы, также являются наилучшими для прогнозирования ответ (хотя это часто предполагается). Метод методом наименьших квадратов (PLS) - это контролируемая альтернатива ПЦР. Как и PCR, PLS - это метод уменьшения размеров, который сначала определяет новый меньший набор элементов, которые представляют собой линейные комбинации исходных элементов, а затем подгоняет линейную модель с помощью наименьших квадратов к новым элементам M. Тем не менее, в отличие от PCR, PLS использует переменную ответа для определения новых функций.
7 - Нелинейные модели:
В статистике нелинейная регрессия - это форма регрессионного анализа, в котором данные наблюдений моделируются функцией, которая представляет собой нелинейную комбинацию параметров модели и зависит от одной или нескольких независимых переменных. Данные аппроксимированы методом последовательных приближений. Ниже приведены несколько важных приемов работы с нелинейными моделями:
- Функция на действительных числах называется ступенчатой функцией, если ее можно записать как конечную линейную комбинацию индикаторных функций интервалов. Неформально говоря, ступенчатая функция - это кусочно-постоянная функция, состоящая только из конечного числа частей.
- Кусочная функция - это функция, которая определяется несколькими подфункциями, каждая подфункция применяется к определенному интервалу домена основной функции. Кусочно - это фактически способ выражения функции, а не характеристика самой функции, но с дополнительными уточнениями он может описывать природу функции. Например, кусочно-полиномиальная функция - это функция, которая является полиномом на каждой из своих подобластей, но, возможно, на каждой другой.
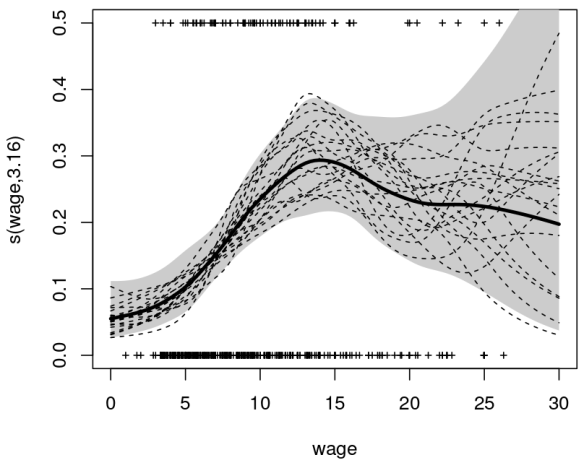
- сплайн - это специальная функция, кусочно определяемая полиномами. В компьютерной графике сплайн относится к кусочно-полиномиальной параметрической кривой. Сплайны являются популярными кривыми из-за простоты их построения, простоты и точности оценки, а также их способности аппроксимировать сложные формы с помощью подбора кривой и интерактивного проектирования кривых.
- Обобщенная аддитивная модель - это обобщенная линейная модель, в которой линейный предсказатель линейно зависит от неизвестных гладких функций некоторых переменных-предикторов, и интерес сосредоточен на выводе об этих гладких функциях.
8 - Древовидные методы:
Древовидные методы могут использоваться как для регрессионных, так и для классификационных задач. Они включают стратификацию или сегментирование пространства предикторов на ряд простых областей. Поскольку набор правил разделения, используемых для сегментирования пространства предикторов, можно обобщить в виде дерева, эти типы подходов известны как методы дерева решений. Приведенные ниже методы выращивают несколько деревьев, которые затем объединяются для получения единого консенсусного прогноза.
- Бэггинг - это способ уменьшить дисперсию вашего прогноза путем создания дополнительных данных для обучения из исходного набора данных с использованием комбинаций с повторениями для создания многоступенчатого шага той же плоти / размера, что и исходные данные. Увеличивая размер обучающей выборки, вы не можете улучшить предсказательную силу модели, а просто уменьшить дисперсию, точно настроив прогноз в соответствии с ожидаемым результатом.
- Повышение - это подход к вычислению результата с использованием нескольких различных моделей и последующему усреднению результата с использованием метода средневзвешенного значения. Объединив преимущества и недостатки этих подходов, варьируя формулу взвешивания, вы можете получить хорошую предсказательную силу для более широкого диапазона входных данных, используя различные узко настроенные модели.
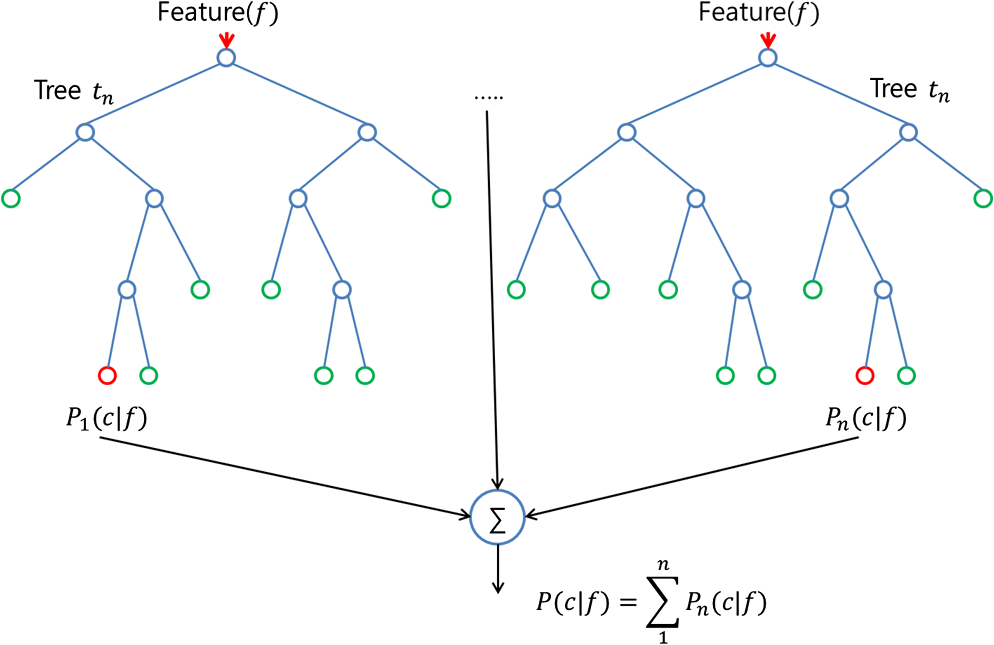
- Алгоритм случайного леса на самом деле очень похож на бэггинг. Также здесь вы рисуете случайные образцы начальной загрузки вашего обучающего набора. Однако в дополнение к образцам начальной загрузки вы также рисуете случайное подмножество функций для обучения отдельных деревьев; в упаковке вы даете каждому дереву полный набор функций. Благодаря случайному выбору признаков вы делаете деревья более независимыми друг от друга по сравнению с обычным бэггингом, что часто приводит к лучшей прогнозной производительности (из-за лучшего компромисса смещения дисперсии), а также быстрее, потому что каждое дерево учится только из подмножество функций.
9 - Поддержка векторных машин:
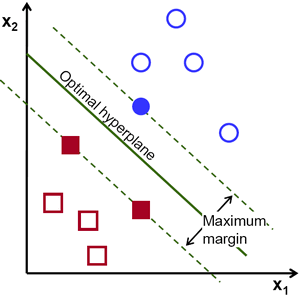
SVM - это метод классификации, который указан в моделях контролируемого обучения в машинном обучении. С точки зрения непрофессионала, это включает в себя поиск гиперплоскости (линия в 2D, плоскость в 3D и гиперплоскость в более высоких измерениях. Более формально гиперплоскость - это n-1-мерное подпространство в n-мерном пространстве), которая лучше всего разделяет два класса точек с максимальная маржа. По сути, это задача оптимизации с ограничениями, когда маржа максимизируется при условии, что она идеально классифицирует данные (жесткая маржа).
Точки данных, которые как бы «поддерживают» эту гиперплоскость с обеих сторон, называются «опорными векторами». На картинке выше залитый синий кружок и два закрашенных квадрата являются опорными векторами. В случаях, когда два класса данных не могут быть разделены линейно, точки проецируются в разнесенное (многомерное) пространство, где возможно линейное разделение. Проблема, связанная с несколькими классами, может быть разбита на несколько задач двоичной классификации «один против одного» или «один против остальных».
10 - Обучение без учителя:
До сих пор мы обсуждали только методы контролируемого обучения, в которых группы известны, а опыт, предоставляемый алгоритму, представляет собой отношения между фактическими объектами и группой, к которой они принадлежат. Другой набор методов можно использовать, когда группы (категории) данных неизвестны. Они называются неконтролируемыми, поскольку алгоритм обучения должен определять закономерности в предоставленных данных. Кластеризация - это пример обучения без учителя, в котором различные наборы данных объединяются в группы тесно связанных элементов. Ниже приведен список наиболее широко используемых алгоритмов обучения без учителя:
- Анализ основных компонентов помогает в создании низкоразмерного представления набора данных путем определения набора линейных комбинаций функций, которые имеют максимальную дисперсию и взаимно некоррелированы. Этот метод линейной размерности может быть полезен для понимания скрытого взаимодействия между переменной в неконтролируемой среде.
- Кластеризация k-средних: разбивает данные на k отдельных кластеров в зависимости от расстояния до центроида кластера.
- Иерархическая кластеризация: строит многоуровневую иерархию кластеров путем создания дерева кластеров.
Это был базовый обзор некоторых основных статистических методов, которые могут помочь руководителю программы по анализу данных или руководителю лучше понять, что работает под капотом их команд по анализу данных. По правде говоря, некоторые команды по анализу данных просто запускают алгоритмы через библиотеки Python и R. Большинству из них даже не нужно думать о математике, лежащей в основе. Однако понимание основ статистического анализа дает вашим командам лучший подход. Понимание мельчайших деталей позволяет упростить манипуляции и абстракцию. Я надеюсь, что это базовое статистическое руководство по науке о данных даст вам хорошее понимание!
P.S: Вы можете получить все слайды лекций и сеансы RStudio из моего исходного кода GitHub здесь. Спасибо за потрясающий ответ!
- -
Если вы хотите следить за моей работой над системами рекомендаций, глубоким обучением, MLOps и журналистикой данных, вы можете проверить мои Medium и GitHub, а также другие проекты на https://jameskle.com/. Вы также можете написать мне в Твиттере, написать мне по электронной почте или найти меня в LinkedIn. Или присоединяйтесь к моей рассылке, чтобы получать мои последние мысли прямо на ваш почтовый ящик!