
LSTM и GRU - распространенная проблема, с которой сталкиваются повторяющиеся нейронные сети, заключается в том, что через некоторое время, особенно если вы тренируете сеть на действительно большой последовательности, повторяющаяся нейронная сеть начнет забывать эти самые первые вводит более поздние и более поздние обучающие пакеты более поздних вводов, которые приближаются к концу текстового документа, которые будут запускать своего рода перезапись весов самых начальных вводов начала текста.
Поэтому мы хотим убедиться, что мы не начинаем забывать эти первые входные данные, поскольку информация теряется, что каждый шаг проходит через их текущую нейронную сеть.
Итак, что нам действительно нужно, так это что-то вроде долговременной памяти для наших сетей. Мы сбалансировали как краткосрочную память сетей, так и данные, на которых он недавно был обучен, и долгосрочную память сетей, все данные и самые первые данные, на которых проводилось обучение.
Итак, Ячейка долгосрочной краткосрочной памяти была создана, чтобы помочь решить эти повторяющиеся проблемы нейронной сети.
И хотя ячейки LSTM не совсем современные, они все еще довольно новые, учитывая, что на самом деле они существуют в Керасе только последние несколько лет. Итак, мы рассмотрим, как работает ячейка LSTM.
Имейте в виду, что здесь на самом деле много математики.
Итак, давайте приступим к изучению того, как на самом деле работает эта LSTM-клетка, но быстро вспомним, что типичный рекуррентный нейрон в основном имеет такую структуру, где у нас есть некоторый вход при Т минус один.
Тогда у нас есть выход T минус один, и этот выход также является обратной связью вдоль входа в T, так что вкратце эти выходы часто называются скрытыми, поэтому мы можем вместо того, чтобы говорить выход в T минус один. Мы можем сказать h от T минус один, и тогда это также будет соответствовать входу в t, который проходит через какую-то функцию активации, такую как гиперболический тангенс. Тогда это дает выход h для T и т. Д. Поэтому, когда вы видите h из t, просто думайте об этом как о типичном выходе повторяющейся нейронной клетки.
LSTM (ДОЛГОВРЕМЕННАЯ КРАТКАЯ ПАМЯТЬ)

Как и в случае с RNN, у нас есть временные шаги в LSTM, но у нас есть дополнительная информация, которая называется «ПАМЯТЬ» в ячейке LSTM для каждого временного шага.
Итак, ячейка LSTM содержит следующие компоненты
- Забудьте о Gate «f» (нейронная сеть с сигмоидом)
- Слой кандидатов «C`» (NN с Tanh)
- Входной вентиль «I» (NN с сигмовидой)
- Выходной вентиль «O» (NN с сигмоидой)
- Скрытое состояние «H» (вектор)
- Состояние памяти «C» (вектор)
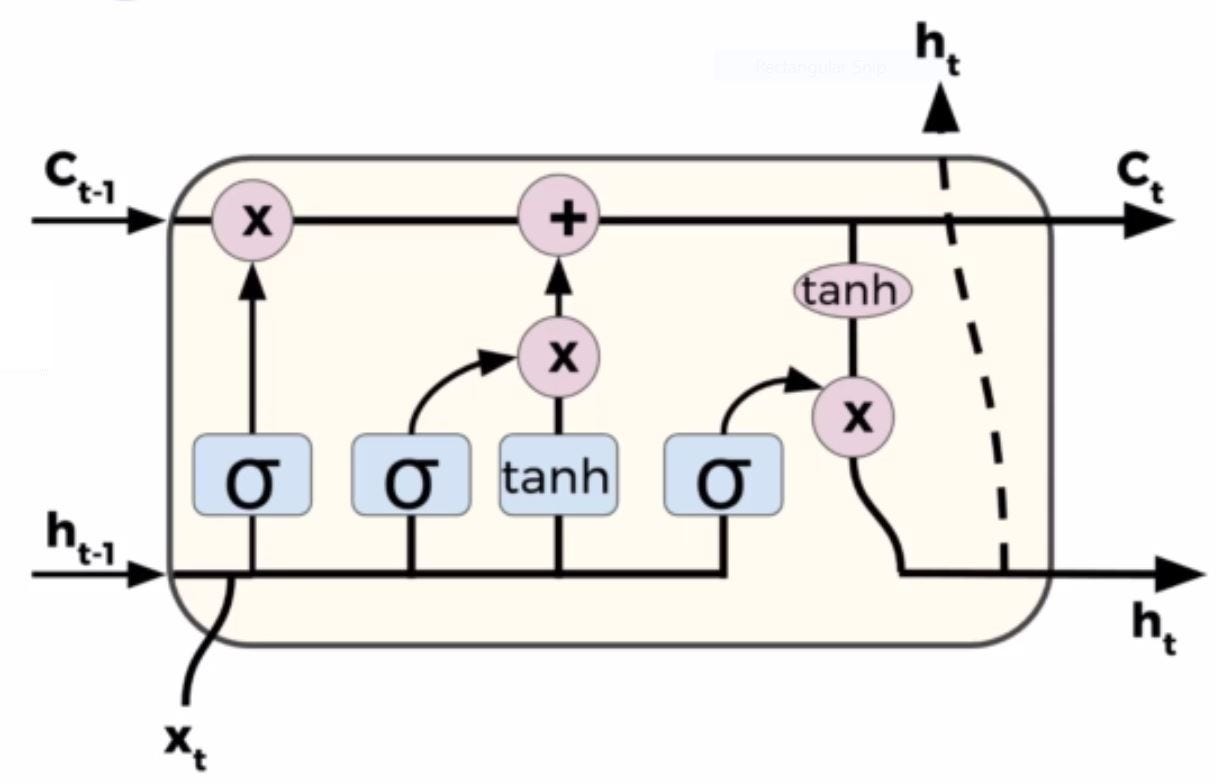
Хорошо, здесь мы можем увидеть всю модель ячейки долговременной краткосрочной памяти, и я знаю, что она может выглядеть очень сложной, если вы видите ее в этом формате, но на самом деле это не так уж плохо, если вы разбиваете ее на части.
Сначала посмотрите, что здесь вводится и что выводится.
У нас все еще есть исходные данные от обычного RNN.
Эти h равны T минус единица и выход T. Но обратите внимание, что здесь у нас есть третий вход, и мы назовем его состоянием ячейки. Итак, прямо сейчас мы получаем состояние ячейки при Т минус единица, а затем на выходе мы снова выводим h для T, а затем у нас также есть состояния ячейки.
Это текущее состояние ячейки C для T. < br /> Итак, что мы собираемся сделать, мы возьмем h из T минус один и выйдем из T, а также из предыдущего состояния ячейки C из T минус один, и мы выведем h T, а также текущее состояние C клетки T.
ЗАБЫВАЙТЕ СЛОЙ ВОРОТ


Итак, мы сделаем это шаг за шагом, так что самый первый шаг называется забывает слой Гейтса r, и это будет первый шаг, иначе мы решим, какая информация мы собираемся забыть или выбросить из состояния ячейки.
Итак, что мы в конечном итоге делаем здесь, вы передаете h из T минус один и x из T, и мы передаем это после выполнения линейного преобразования с некоторыми весами и смещенные термины в сигмовидную функцию.
И помните, поскольку это, по сути, сигмовидный слой, он всегда будет выводить число от 0 до 1, а 1 будет представлять его, а 0 будет представлять забудьте об этом или избавьтесь от него.
Итак, если мы вспомним, может быть, языковую модель, в которой мы пытаемся предсказать следующее слово на основе предыдущих, состояние ячейки может включать в себя пол настоящего субъекта, чтобы вы могли выбрать правильное местоимение, чтобы, когда вы в конечном итоге увидели новый предмет, вы хотите забыть о поле старого предмета.
Так что это может быть использовано для слоя забыть ворота при работе с естественным языком как последовательность.
СОСТОЯНИЕ ЯЧЕЙКИ

Теперь следующий шаг - решить, какую новую информацию вы собираетесь хранить в состоянии ячейки.

Итак, мы заказываем то, что собираемся забыть. Теперь нам нужно решить, что мы на самом деле будем хранить в состоянии ячейки.
Помните, что это C из T.
Итак, первая часть - это сигмовидный слой.
, а вторая часть - это слой гиперболического касательного.
Итак, давайте продолжим и займемся первой частью этого сигмовидного слоя.
Итак Сигмоидный слой let называется слоем входного затвора.
Итак, мы скажем, что он равен IFT для слоя входного затвора. И снова мы берем h из T минус 1, и x из t производим на нем линейное преобразование. Это будет vi плюс ba vi, мы передадим это в сигмовидную функцию, и снова теперь у нас есть набор значений между нулями и единицами.
Затем вторая часть этого - это слой гиперболического тангенса, и он снова возьмет h из T минус один и выйдет из t, выполните это линейное преобразование, а затем пропустите его через гиперболический тангенс, чтобы в итоге создать вектор того, что мы называем новыми значениями-кандидатами .
Итак, это C of T с небольшим наклоном над ним.
Итак, это возможные значения, которые могут будет добавлен в состояние на следующем шаге. Мы собираемся объединить эти два, чтобы создать обновление состояния ячейки.
Итак, если мы вернемся к примеру языковой модели, мы, по сути, хотим добавить пол нового зависит от состояния ячейки и заменяет старую, о которой мы уже решили, что забываем, поэтому теперь пришло время обновить старое состояние ячейки.
ОБНОВЛЕНИЕ СОСТОЯНИЯ ЯЧЕЙКИ

Помните, что старое состояние ячейки - это C из T минус один, и мы в конечном итоге хотим обновить его до нового состояния ячейки C из T, чтобы мы могли передать его в T плюс одно состояние ячейки.
Так было в предыдущем шаги, мы уже решили, что мы собираемся забыть, и мы также уже решили, что мы будем хранить.
Итак, теперь нам нужно просто выполнить или выполнить эти действия.
В итоге мы умножаем старое состояние C из T минус единица на F из T, так что мы в конечном итоге забываем то, что мы, по сути, решили, что мы собираемся забыть.
Затем на основе этого первого сигмовидного слоя мы собираемся добавить, что у меня t слой входного затвора, умноженный на те значения-кандидаты C of t, которые отмечены сверху.
Итак, это новые значения-кандидаты, и теперь они масштабируются в зависимости от того, насколько мы решили повысить значение каждого состояния.
Итак, если мы вернемся к случаю языковой модели, здесь мы фактически отбросим информацию о поле этого старого испытуемого и добавим новую информацию, основанную на том, что мы решили на предыдущих шагах.
ТЕКУЩИЙ ВЫХОД НА ЯЧЕЙКЕ

Теперь наше окончательное решение будет заключаться в том, что мы будем выводить для h из T.
Итак, этот вывод будет основан на состоянии вашей ячейки.
Это просто отвлечение фильтра. Так что теперь это на самом деле довольно просто.
Мы просто используем h из T минус 1 и x из t мы передаем это после линейного преобразования в сигмовидный слой, и это решит, какие части состояния ячейки мы собираемся выводить. Затем мы помещаем состояние ячейки через гиперболический тангенс, чтобы значения были между отрицательными 1 и 1, и мы собираемся затем умножить его на выход этого сигмовидного вентиля, чтобы мы выводили только те части, которые мы решили .
Вот что происходит здесь, в этой красной линии.
Снова мы берем h из T минус один и выходим из t, выполняя линейное преобразование, передавая его через сигмоид, а затем, когда у нас есть этот выход, мы собираемся сказать, что это o из T выхода T. умножить на гиперболический тангенс точки C точки T или текущего состояния ячейки, и это дает ssss нам h of T.
Вот как работает ячейка LSTM.
ГРУ (закрытый рекуррентный блок)

Блок GatedRecurrent или ГРУ.
На самом деле он был представлен совсем недавно, примерно в 2014 году, и в конечном итоге он упрощает ситуацию, комбинируя теги Забудьте и введите ворота в единый, который они называют воротами обновления.
Кроме того, он объединяет состояние ячейки и скрытое состояние и создает несколько других изменений.
Таким образом, полученная модель на самом деле проще, чем стандартные модели LSTM, и из-за этого она становится все более популярной в последние несколько лет.
Так что на самом деле есть много других небольших вариаций этого, и они вводятся постоянно, была еще одна, называемая глубинными рекуррентными нейронными сетями, которая была представлена в 2015 году.
И я имею в виду, кто знает, может быть, в нескольких лет мы увидим еще один вариант, который будет улучшать эту модель.
Но основная идея состоит в том, чтобы понять, как работает LSTM, и это позволит вам быстро узнать, как эти варианты работают на его основе.
Хорошо.

Вот и все. Удачной Вам Жизни…. !!!!!!!!!!!!!!!!!! СЧАСТЛИВОГО УЧЕНИЯ.
ССЫЛКИ:
Если есть ошибка, не стесняйтесь ее упоминать.
Надеюсь, вы получили то, что искали.
Если ты ценишь мои старания,
Не забудьте дать Хлопать. Это поднимает мне настроение. Спасибо!