Реальные примеры различных методов распределения вероятностей

«Правило 50–50–90: каждый раз, когда у вас есть 50–50 шансов сделать что-то правильно, с вероятностью 90% вы ошибетесь».
- Энди Руни
Вступление
Все параметрические тесты предполагают, что данные будут в определенном типе распределения данных для применения статистических тестов. Однако форма распределения определяется характером эксперимента и данными. Помимо понимания сложных математических выводов формул для демонстрации теории, лежащей в основе распределения вероятностей, важно понимать интуиции из реальной жизни, которые более понятны в качестве начального шага к изучению. В этой статье я объясню реальный сценарий для каждого распределения вероятностей.
Оглавление
- Дискретное и непрерывное распределение
- Равномерное распределение
- Распределение Бернулли
- Биномиальное распределение
- Геометрическое распределение
- Отрицательное биномиальное распределение
- Нормальное распределение
- Распределение Пуассона
- Экспоненциальное распределение
- Гипергеометрическое распределение
- Отрицательное гипергеометрическое распределение
- Одномодальное распространение
Дискретные и непрерывные распределения
Дискретные распределения вероятностей формируются, когда мы проводим эксперимент с переменными, который дает дискретный результат.
Эти переменные можно количественно оценить, посчитав их количество.
Пример-
· Вероятность получения суммы 5 при броске 2 кубиков 6 раз.
· Вероятность того, какое количество студентов будет в классе в следующий понедельник.
· Вероятность получения подарка на следующий день рождения от друга.
Непрерывные распределения вероятностей формируются, когда мы экспериментируем с переменными, которые дают непрерывный результат.
Эти переменные можно количественно оценить, измерив их показатели.
Пример-
· Вероятность выбора ученика ростом 174 см.
· Вероятность прибытия в пункт назначения в течение 60 минут после начала поездки.
· Вероятность того, что завтра в городе будет температура 30 градусов по Цельсию.


Равномерное распределение
Представьте, что мы бросаем кости, какова вероятность получить целочисленный результат?
· Вероятность получения 1 = 1/6
· Вероятность получения 2 = 1/6
· Вероятность получения 3 = 1/6
· Вероятность получения 4 = 1/6
· Вероятность получения 5 = 1/6
· Вероятность получения 6 = 1/6
Здесь все возможные исходы имеют равную вероятность.
Точно так же рассмотрим, что мы подбрасываем монету, какова вероятность получения правильного результата (орел или решка).
· Вероятность выпадения головы = 1/2
· Вероятность выпадения хвоста = 1/2
Здесь также все возможные исходы имеют равную вероятность.
Эти сценарии являются примерами равномерного распределения.


Распределение Бернулли
Это своего рода распределение, которое будет иметь только 2 возможных результата - Истина или Ложь.
Например,
· Вероятность получения правильного результата при подбрасывании монеты (орел или решка).
· Вероятность получения правильного результата при сдаче экзамена (сдан или не сдан).
· Вероятность получения достоверного результата при приеме лекарства (эффективное или неэффективное).
Биномиальное распределение
Это расширенная версия распределения Бернулли, в которой объединены несколько событий Бернулли.
Например, если мы хотим найти вероятность получить голову при подбрасывании монеты ровно один раз, это биномиальное распределение. Однако, подбрасывая монету более одного раза (скажем, 5 раз), какова вероятность выпадения ровно 3 орлов? Это классический пример биномиального распределения.
Еще несколько примеров -
· Вероятность получить 3 решки ровно за 7 бросков.
· Вероятность выиграть игру ровно 5 раз, если сыграть 10 раз.
· Вероятность сдачи выпускных экзаменов ровно по 6 предметам из 10.

Геометрическое распределение
Представьте, что мы стоим перед избирательным участком. На выборах участвуют 2 кандидата X и Y. Теперь нам нужно найти количество людей, которые не голосовали за X, пока первый голос не был для него кастом.
Представьте, что каждый человек говорит, за кого он голосовал, после того, как зашел с избирательного участка.
· Человек 1 сказал, что голосовал за Y.
· Человек 2 сказал, что голосовал за Y.
· Человек 3 сказал, что голосовал за Y.
· Человек 4 сказал, что голосовал за Y.
· Человек 5 сказал, что голосовал за X.
Здесь 4 голоса не относятся к X, пока он не получит первый голос.
Это означает, что до первого успеха не было никаких неудач.
Геометрическое распределение - это такое распределение данных, которое измеряет количество отказов до того, как произойдет первый успех.

Для геометрического распределения должны быть определенные условия.
· Испытания должны быть независимыми.
· Результат должен быть двоичным.
· Вероятность успеха в каждом испытании должна быть одинаковой.
Отрицательное биномиальное распределение
Это расширение геометрического распределения, в котором количество успехов будет кратным, а не одним. Здесь мы измеряем количество сбоев до того, как произойдет определенное количество успехов.
Например, количество избирателей, которые не проголосовали за X, пока X не получит ровно 3 голоса.
Нормальное распределение
Нормальное распределение, также известное как распределение Гаусса, представляет собой распределение вероятностей, которое симметрично относительно среднего, показывая, что данные, близкие к среднему, встречаются чаще, чем данные, далекие от среднего.
Согласно теории, форма распределения данных будет в точности похожа на кривую колокола. В основном это будет нулевой перекос и эксцесс около 3.
Например,
· Образцы данных включают рост всех учащихся в классе.
· Оценки всех учащихся класса на конкретном экзамене.

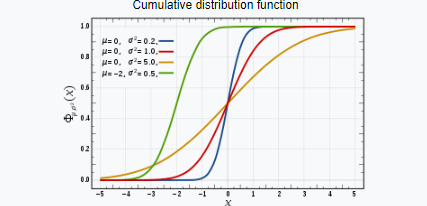
Эмпирическое правило говорит вам, какой процент ваших данных находится в пределах определенного числа стандартного отклонения от среднего:
• 68% данных попадают в одно стандартное отклонение от среднего.
• 95% от среднего. данные находятся в пределах двух стандартных отклонений от среднего.
• 99,7% данных находятся в пределах трех стандартных отклонений от среднего.
· Стандартное нормальное распределение может быть сформировано, если мы преобразуем все точки данных в новое значение, используя функцию со средним значением = 0 и стандартным отклонением = 1.
· Логарифмически нормальное распределение может быть сформировано, если мы преобразуем все точки данных в соответствующий логарифм.
· Логарифмическое стандартное нормальное распределение может быть сформировано, если мы преобразуем все точки данных стандартного нормального распределения в соответствующее значение логарифма.
· Нормальное распределение, которое не является симметричным, называется асимметричным распределением. Перекос может быть как положительным, так и отрицательным.
распределение Пуассона
Это дискретное распределение вероятностей, которое вычисляет вероятность того, что заданное количество событий произойдет в заданный период времени.
Например,
Учтите, что профессор запланировал занятие на понедельник с 9 до 10. Какова вероятность того, что класс посетят ровно 75 учеников, если общая численность класса составляет 100 человек?
Это не что иное, как пример распределения Пуассона.
Еще несколько примеров:
· Вероятность того, что в 2021 году в Нью-Йорке будет построено ровно 50 новых зданий.
· Вероятность того, что ровно 50 акций вырастут более чем на 3% с 9:00 до 15:00 на фондовых рынках США.


Здесь лямбда обычно предполагается с помощью исторических свидетельств.
Экспоненциальное распределение
Это непрерывное распределение вероятностей, которое описывает время, необходимое для ожидания между двумя приходами двух независимых событий.
Например, предположим, что профессор занимается с 9 до 10 часов утра.
· Студент 1 прибыл в 9.01.
· Студент 2 прибыл в 9:05.
· Студент 3 прибыл в 9:15.
· Студент 4 прибыл в 9:10.
· Студент 5 прибыл в 9:08.
Итак, какова вероятность того, что разница во времени между прибытием Студента 2 и Студента 3 превышает 5 минут?
Это не что иное, как пример экспоненциального распределения.
Сходным образом,
· Какова вероятность того, что разница во времени между прибытием Студента 2 и Студента 3 меньше 5 минут?
· Какова вероятность того, что разница во времени между прибытием Студента 2 и Студента 3 меньше 5 минут, но больше 3 минут?


Здесь лямбда - это среднее количество приходов в единицу времени.
Гипер-геометрическое распределение
Это особый вид распределения, при котором вероятность определенных особых характеристик объекта измеряется при отборе из большой совокупности.
Учтите, что в Нью-Йорке 1 миллион кошек. Мы хотим узнать вероятность того, что кошка будет самкой, если выберем случайную кошку из популяции. Это очень сложно определить при такой большой численности населения.
Теперь мы случайным образом выбираем 1000 кошек из общей популяции. Теперь, какова вероятность того, что выбранная кошка из этой случайной выборки будет самкой?
Это не что иное, как реальный пример гипергеометрического распределения.
Если внимательно присмотреться к этой теории, можно обнаружить, что это расширенная версия биномиального распределения.
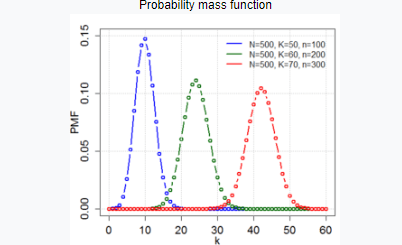
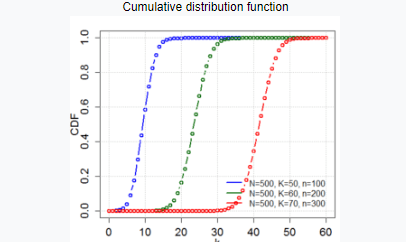
Здесь,
N = размер популяции
K = количество успешных состояний в популяции
N = Количество розыгрышей
K = количество наблюдаемых успехов
Отрицательное гипергеометрическое распределение
Это похоже на отрицательное биномиальное распределение в контексте гипергеометрического распределения.
Здесь нам нужно измерить количество неудачных случаев до заранее определенного количества успехов.
Для того же реального сценария, описанного выше, какова вероятность получить ровно 120 кошек, пока мы не найдем 20 котов мужского пола, если мы посчитаем в общей популяции кошек Нью-Йорка 1 миллион?
Это не что иное, как пример отрицательного гипергеометрического распределения.


Здесь,
N = размер популяции
K = количество успешных состояний в популяции
R = количество отказов
K = количество наблюдаемых успехов.
Одномодальное распределение
Одномодальное распределение имеет один идентифицируемый пик на диаграмме распределения данных. Нормальное распределение - это пример одномодального распределения, когда данные растут с небольшого значения и достигают пика при определенном числе, а затем снова постепенно уменьшаются.
Бимодальное распределение имеет 2 пика в форме распределения данных.
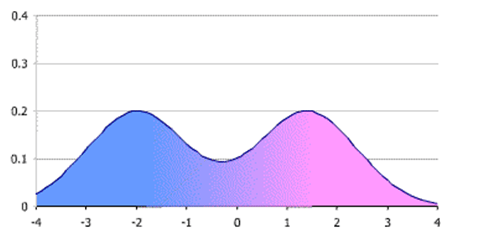
Точно так же мультимодальное распределение имеет более двух пиков в форме распределения данных.

Заключение
История вероятности действительно богата, антична и увлекательна. Однако на протяжении столетия эта тема оставалась лишь уделом умов и исследователей. В связи с быстрым использованием машинного обучения и науки о данных в последние годы, этот предмет, поднимаемый в отрасли, а также студенты и профессионалы, владеющие этой сутью, пользуются большим спросом.
Хотя для вероятностных тестов и случайных процессов в R и Python доступны различные встроенные библиотеки, очень важно изучить приложение реального времени и интуитивно понятный процедурный расчет концепций, чтобы это было очень полезно для создания расширенных моделей с точки зрения высокая производительность и согласованность при изменении бизнес-сценариев использования.
Я надеюсь, что эта статья была полезна для понимания интуиции, лежащей в основе каждой концепции распределения вероятностей.
Вы можете связаться со мной на следующих платформах:
- Quora
- Gmail - [email protected]
использованная литература
1. Агрести А., Финли Б. Статистические методы в социальных науках. 4-е издание. Река Аппер Сэдл, Нью-Джерси: Прентис-Холл, 2009.
2. Пелози М.К., Сандифер Т.М., Черкиелло П. и др. Введение в статистику. 2-е издание. Неаполь: Edizioni Scientifiche Italiane, 2008.
3. Гайек А. Интерпретации вероятностей. В кн .: Залта Е.Н., редактор. Стэнфордская энциклопедия философии. Стэнфорд, Калифорния: Исследовательская лаборатория метафизики, 2012.
4. Гримметт Г.Р., Стирзакер Д.Р. Вероятность и случайные процессы, 3-е издание. Оксфорд: Издательство Оксфордского университета, 2001.