
Кратко об Apache Kafka
Архитектура, сценарии использования и руководство по началу работы - в одном лице
Итак, вы слышали об этой штуке с Кафкой, которая появляется повсюду в магазине. От стартапов с зелеными побегами до жадных многонациональных компаний во всевозможных странных и замечательных контекстах. Похоже, что кто-то придумал швейцарский армейский нож из über -технологии, который работает для микросервисов, потоковой передачи событий, CQRS и всего остального, что попадает в заголовки.
Как человек, работающий с Apache Kafka с 2015 года, помогая нескольким клиентам создавать сложные событийно-ориентированные приложения и приложения в стиле микросервисов, я слышал свою долю вопросов. Во-первых, большую часть вопросов задавал я. Затем я оказался на стороне получателя. На момент написания я вошел в десятку лучших писателей на Quora - подвиг, которым я обязан в основном ошибкам, которые я сделал на этом пути, которые сделали меня немного более осознанным. Убрав бессовестное избиение грудью, я подумал, что смогу составить пост в стиле часто задаваемых вопросов, который разбивает Kafka на части, сосредотачиваясь на важных аспектах.
Что такое Кафка?
Apache Kafka - это платформа для потоковой передачи событий с открытым исходным кодом, которая была создана из LinkedIn примерно в 2011 году. Первоначально она использовалась для перекачки (большого количества) сообщений через жилы LinkedIn, но с тех пор была выпущена в мир. И вот мы здесь.
Для чего это можно использовать?
Широкий спектр архитектур приложений, управляемых событиями, может выиграть от использования Kafka в качестве базовой магистрали обмена сообщениями / событиями. Конкретные случаи включают:
Опубликовать-подписаться

Любые сценарии обмена сообщениями, при которых производители обычно не знают потребителей и вместо этого публикуют сообщения в хорошо известных группах, называемых темами. И наоборот, потребители, как правило, не знают производителей, а вместо этого озабочены конкретными категориями контента. Экосистемы производителя и потребителя слабо связаны, им известны только общие темы и схемы обмена сообщениями. Этот шаблон часто используется при создании слабосвязанных микросервисов.
Агрегация журналов

Работа с большими объемами структурированных журналов событий, обычно генерируемых компонентами приложений или инфраструктуры. Журналы могут создаваться с большой скоростью, которая значительно превосходит способность баз данных поддерживать прием и индексирование журналов, что обычно является дорогостоящей операцией. Kafka может действовать как буфер, предлагая промежуточное надежное хранилище данных. Процесс приема будет действовать как приемник, в конечном итоге объединяющий журналы в базу данных, оптимизированную для чтения (например, Elasticsearch). Конвейер агрегации журналов также может содержать промежуточные этапы, например, для нормализации журналов до канонической формы или очистки журналов - очистки их от информации, позволяющей установить личность.
Доставка журналов

Хотя это звучит отдаленно похоже на агрегацию журналов, доставка журналов - это совершенно другая концепция. По сути, это включает в себя копирование в реальном времени записей журнала из главной системы в одну или несколько реплик. Предполагая, что изменения стадии полностью фиксируются в записях журнала, повторное воспроизведение этих записей позволяет репликам точно имитировать состояние мастера, хотя и с некоторым запаздыванием.
Трубопроводы SEDA

Поэтапная архитектура, управляемая событиями (SEDA) - это применение конвейерной обработки данных, ориентированных на события. События проходят однонаправленно через серию этапов обработки, связанных между собой темами, каждый из которых выполняет операцию сопоставления перед публикацией преобразованного события в следующую тему. Промежуточные ступени одновременно действуют как потребители и производители и могут масштабироваться автономно и независимо друг от друга в соответствии с их уникальными требованиями к нагрузке. Разбивая сложную проблему на этапы, SEDA улучшает модульность системы. Как правило, SEDA легко найти в хранилищах данных, озерах данных, отчетности, аналитике и других приложениях бизнес-аналитики и часто является элементом приложений для больших данных.
CEP

Комплексная обработка событий (CEP) извлекает значимую информацию и шаблоны в поток дискретных событий или в наборе несвязанных потоков событий. Процессоры CEP, как правило, отслеживают состояние, поскольку они должны иметь возможность эффективно вспоминать предыдущие события, чтобы идентифицировать шаблоны, которые могут охватывать широкий период времени, от миллисекунд до дней, в зависимости от контекста. CEP широко используется в таких приложениях, как алгоритмическая торговля акциями, анализ угроз безопасности, обнаружение мошенничества в реальном времени и системы контроля.
CQRS на основе событий

Разделение ответственности команд-запросов (CQRS) отделяет действия, которые изменяют состояние, от действий, которые запрашивают состояние. Поскольку мутации и запросы обычно демонстрируют противоположные характеристики времени выполнения и требуют совершенно разных, часто противоречащих друг другу решений по оптимизации, разделение этих проблем часто способствует созданию высокопроизводительных систем. Обратной стороной является сложность, требующая нескольких хранилищ данных и дублирования данных - каждое хранилище данных будет иметь уникальную проекцию основного набора данных, но также должно подаваться через свой собственный канал данных. Kafka снижает сложность, присущую архитектурам CQRS, действуя как общий регистр, основанный на событиях, используя концепцию групп потребителей для индивидуального питания различных хранилищ данных, ориентированных на запросы.
Каковы ключевые компоненты Кафки?
На диаграмме ниже представлен краткий обзор компонентной архитектуры Kafka.
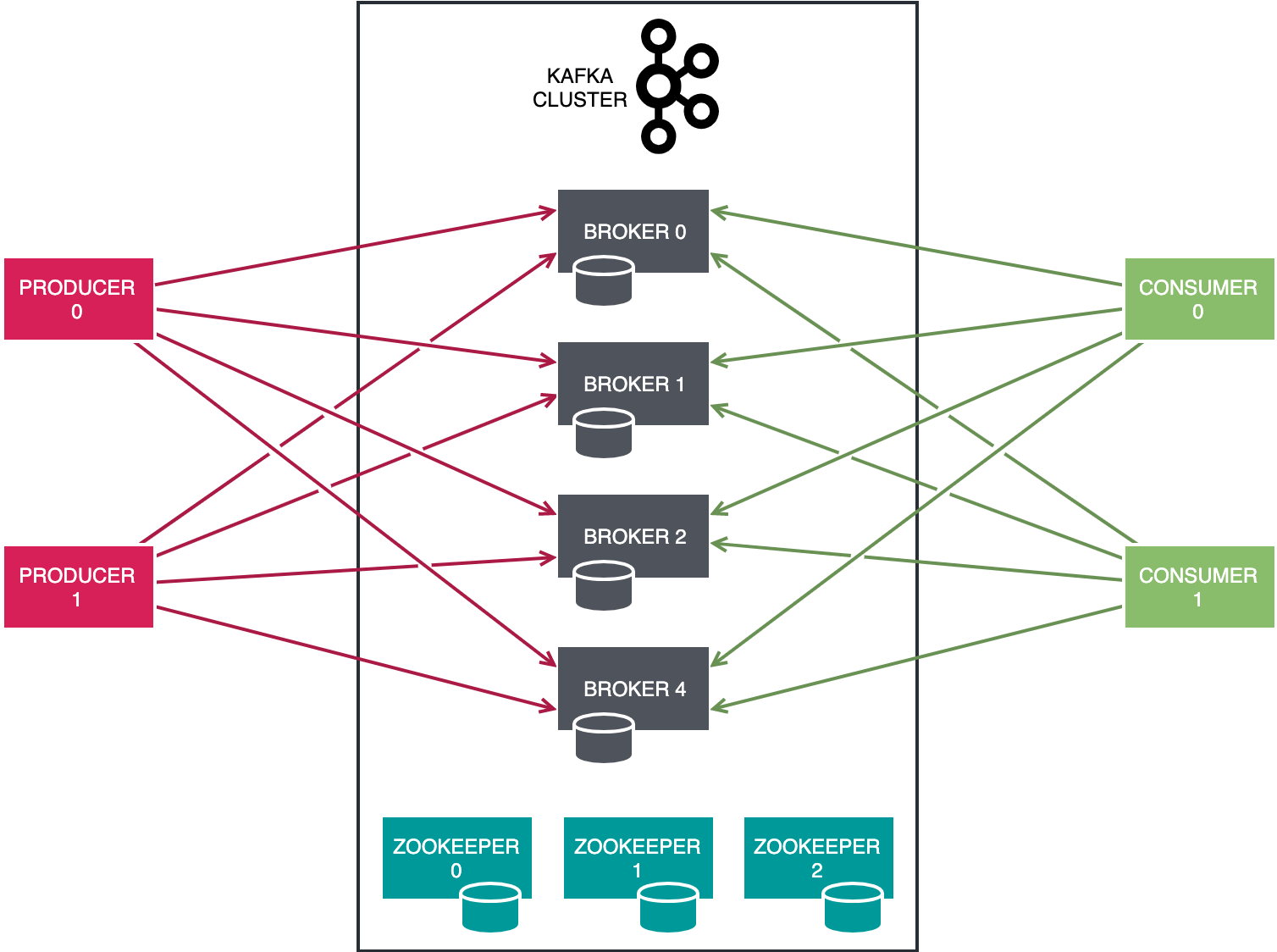
Kafka - это распределенная система, состоящая из нескольких ключевых компонентов:
- Узлы-посредники: отвечают за большую часть операций ввода-вывода и устойчивую работу в кластере. Посредники размещают файлы журнала только для добавления, которые составляют разделы темы, размещенные в кластере. Разделы могут быть реплицированы между несколькими брокерами как для горизонтальной масштабируемости, так и для повышения надежности - это называется репликами. Узел-брокер может выступать в качестве лидера для одних реплик, в то же время являясь последователем для других. Одиночный узел брокера также будет выбран в качестве контроллера кластера, отвечающего за внутреннее управление состояниями разделов. Это включает в себя арбитраж ролей лидер-последователь для любого данного раздела.
- Узлы ZooKeeper. Внутри Kafka нужен способ управления общим статусом контроллера в кластере. Если контроллер отключится по какой-либо причине, существует протокол для выбора другого контроллера из набора оставшихся брокеров. Фактическая механика выбора контроллера, биения сердца и т. Д. В значительной степени реализована в ZooKeeper. ZooKeeper также действует как своего рода репозиторий конфигурации, поддерживая метаданные кластера, состояния лидер-последователь, квоты, информацию о пользователях, списки контроля доступа и другие вспомогательные элементы. Из-за лежащего в основе протокола сплетен и консенсуса количество узлов ZooKeeper должно быть нечетным.
- Производители: клиентские приложения, отвечающие за добавление записей к темам Kafka. Из-за того, что Kafka имеет структуру журналов и возможность делиться темами в нескольких потребительских экосистемах, только производители могут изменять данные в базовых файлах журналов. Фактический ввод-вывод выполняется узлами-брокерами от имени клиентов-производителей. Любое количество производителей может публиковать в одной и той же теме, выбирая разделы, используемые для хранения записей.
- Потребители: клиентские приложения, которые читают по темам. Любое количество потребителей может читать по одной и той же теме; однако, в зависимости от конфигурации и группировки потребителей, существуют правила, управляющие распределением записей среди потребителей. Мы вернемся к этому в ближайшее время.
Какие ключевые понятия мне нужно знать?
Мы уже коснулись брокеров, производителей и потребителей. Их связывают понятия темы и разделы.

Раздел - это полностью упорядоченная последовательность записей, лежащая в основе Kafka. В биологическом смысле это похоже на артерию - отводящую от источника для питания нижележащих органов - потребителей. Запись имеет смещение, а также может иметь ключ и значение; оба являются байтовыми массивами, и оба необязательны. Термин «полностью заказанный» просто означает, что для любого данного производителя записи будут записаны в том порядке, в котором они были отправлены приложением. Если запись P была опубликована до Q, тогда P будет предшествовать Q в разделе. Более того, они будут прочитаны в том же порядке всеми потребителями; P всегда будет прочитан перед Q. Эта гарантия заказа жизненно важна в подавляющем большинстве случаев использования; опубликованные записи, как правило, соответствуют некоторым реальным событиям, и часто важно сохранить временную шкалу этих событий.
Несколько производителей могут публиковать данные в одном разделе, но не существует признанного упорядочивания между производителями; если два (или более) производителя выпускают записи одновременно, эти записи могут материализоваться в произвольном порядке. При этом этот порядок по-прежнему будет соблюдаться единообразно для всех потребителей.
Тема - это логическая композиция разделов. Тема может иметь один или несколько разделов, и раздел должен быть частью только одной темы. Темы имеют фундаментальное значение для Kafka, обеспечивая как параллелизм, так и балансировку нагрузки. Поскольку разделы внутри темы независимы друг от друга, говорят, что в теме используется частичный порядок. Проще говоря, это означает, что определенные записи могут быть упорядочены по отношению друг к другу, но не упорядочены по отношению к некоторым другим записям. Понятия общего и частичного порядка позволяют нам обрабатывать записи параллельно где мы можем, сохраняя порядок там, где мы должны .
Производители диктуют, какие записи могут обрабатываться одновременно, а какие должны быть линеаризованы. При публикации производители могут указать, что записи должны быть взаимно упорядочены, назначив им одинаковый ключ. Другими словами, записи с общим ключом будут опубликованы в одном разделе. (Под капотом Kafka будет хешировать ключ записи, чтобы получить номер раздела.) В качестве альтернативы, если записи имеют разные ключи, они могут публиковаться в разных разделах.
Потребители подписываются на тему как часть всеобъемлющей группы потребителей. Когда первый потребитель в группе присоединяется к теме, он получит все разделы в этой теме. Когда впоследствии подключается второй потребитель, он получает примерно половину разделов, освобождая первого потребителя от половины его предыдущей нагрузки. Когда потребители уходят (отключение или тайм-аут), процесс идет в обратном порядке - оставшиеся потребители поглощают большее количество разделов. Таким образом, группа потребителей уравновешивает нагрузку на разделы; чем больше потребителей вы добавите, тем меньше разделов получит каждый потребитель. Добавление большего количества потребителей, чем разделов, оставит некоторых потребителей в состоянии ожидания; Kafka никогда не назначит раздел нескольким потребителям в одной группе.
Акт использования записи не удаляет ее. Потребители абсолютно не влияют на тему и ее разделы; тема - это реестр, предназначенный только для добавления, который может быть изменен только производителем или самим Kafka. Потребитель внутренне поддерживает смещение, которое указывает на следующую запись в разделе, увеличивая смещение при каждом последующем чтении. В какой-то момент потребитель должен зафиксировать свои смещения, записав их обратно в кластер Kafka. Обычно потребитель читает запись (или пакет записей) и фиксирует смещение последней записи, плюс один. Если новый потребитель принимает тему, он начнет обработку с последнего зафиксированного смещения.

По умолчанию потребитель Kafka будет автоматически фиксировать смещения каждые 5 секунд, независимо от того, завершил ли потребитель обработку записи. Часто это не то, что вам нужно, так как это может привести к смешанной семантике доставки - в случае отказа потребителя некоторые записи могут быть доставлены дважды, а другие могут не быть доставлены вообще. Чтобы включить фиксацию смещения вручную, установите для свойства enable.auto.commit значение false. Контроль точки фиксации смещения обеспечивает большую гибкость в отношении гарантий доставки. Можно перейти от модели доставки не более одного раза к модели доставки хотя бы один раз, просто переместив операцию фиксации с точки до обработка записи начинается до некоторого момента после завершения обработки. В этой модели, если потребитель выйдет из строя на полпути обработки записи, запись будет перечитана после переназначения раздела.
Потребители в группах полностью изолированы. Тема может читаться с разной частотой любым количеством групп потребителей - каждая со своими отдельными разделами и смещениями.
Как он соотносится с традиционными брокерами сообщений?
Традиционные корпоративные брокеры сообщений предлагают несколько различающихся топологий распределения сообщений. С одной стороны, это очередь сообщений - надежный транспорт для обмена сообщениями точка-точка, при необходимости предлагающий балансировку нагрузки потребителя за счет упорядочения сообщений. (Хотя сообщения в очереди упорядочены, это упорядочение эффективно отменяется, если несколько потребителей выходят из очереди.) С другой стороны, тема pub-sub допускает обмен сообщениями в широковещательном стиле, но не предлагает балансировка нагрузки потребителя или надежность сообщений.
Кафка обобщает эти концепции в единую модель; тема из одного источника может удовлетворить широкий круг потребителей без дублирования. Параллелизм и параллелизм лежат в основе архитектуры Kafka, формируя частично упорядоченные потоки событий, которые могут быть сбалансированы по нагрузке в масштабируемой потребительской экосистеме. Простая реконфигурация потребителей и составляющих их групп может привести к совершенно разной семантике распределения и обработки событий; смещение точки фиксации смещения может инвертировать гарантию доставки с модели не более одного раза на модель хотя бы один раз.
Думайте об экосистеме Kafka как о наборе неопубликованных строительных блоков. Вы можете использовать их для постройки небольшой пляжной хижины или небоскреба - они позволяют вам, не слишком ограничивая вас.
Есть ли хорошие инструменты для Кафки?
Когда дело доходит до инструментов, Kafka не включает в себя аккумуляторные батареи. Элементарные инструменты интерфейса командной строки, поставляемые с tar-архивом Kafka, не подходят для всех операций, кроме самых простых. Большинство практиков давно перешли на альтернативные инструменты с открытым исходным кодом и коммерческие инструменты.
Kafdrop

Kafdrop - бесплатный веб-интерфейс для просмотра информации о брокере, конфигурации, навигации по темам, просмотра записей и групп потребителей. Этот инструмент необходим для работы с Kafka, особенно когда вам нужно отладить своих производителей или потребителей. Kafdrop позволяет вам детализировать отдельные разделы, составляющие тему, изолировать диапазон смещения и проверять отдельные сообщения, чтобы вы точно знали, что было опубликовано. Если ваши потребители застряли, вы можете посмотреть на отдельные (для каждого раздела) смещения и определить любых отстающих потребителей. Я уже упоминал, что это бесплатно?
Кафкачат

Хотя веб-инструмент удовлетворит ваши потребности в 99% случаев, всегда найдется тот 1%, когда вы, возможно, не работаете в среде рабочего стола. Утилита Магнуса Иденилла Kafkacat - это то, что вы будете использовать. Он не только позволяет просматривать содержание темы, но и публиковать записи.
Нора

Собственный инструмент LinkedIn Burrow находится в несколько иной категории, чем два других. Он специализируется на мониторинге задержки потребителей, автоматическом профилировании производительности вашего приложения и предупреждении об аномалиях.
Большой! Как мне начать?
Мы собираемся развернуть пару контейнеров Docker - один для Kafka, другой для Kafdrop. Как упоминалось ранее, Kafdrop - это веб-инструмент для получения информации о вашем кластере, который очень пригодится. Вместо того, чтобы запускать их по отдельности, мы будем использовать Docker Compose.
Создайте docker-compose.yaml файл в выбранном вами каталоге, содержащий следующее:
version: "2"
services:
kafdrop:
image: obsidiandynamics/kafdrop
restart: "no"
ports:
- "9000:9000"
environment:
KAFKA_BROKERCONNECT: "kafka:29092"
depends_on:
- "kafka"
kafka:
image: obsidiandynamics/kafka
restart: "no"
ports:
- "2181:2181"
- "9092:9092"
environment:
KAFKA_LISTENERS: "INTERNAL://:29092,EXTERNAL://:9092"
KAFKA_ADVERTISED_LISTENERS: "INTERNAL://kafka:29092,EXTERNAL://localhost:9092"
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: "INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT"
KAFKA_INTER_BROKER_LISTENER_NAME: "INTERNAL"
Примечание. Мы используем изображение
obsidiandynamics/kafkaдля удобства, поскольку оно аккуратно объединяет Kafka и ZooKeeper в одно изображение. При желании вы можете заменить это отдельными изображениями и все это подключить. Изображениеobsidiandynamics/kafkaделает все это за вас, поэтому его настоятельно рекомендуется новичкам (и ленивым профессионалам).
Затем начните с docker-compose up. После загрузки перейдите к localhost: 9000 в своем браузере. Вы должны увидеть экран посадки Kafdrop.
Пора опубликовать несколько сообщений. Мы будем использовать встроенные инструменты командной строки Kafka. Поскольку у нас уже есть образ Kafka, работающий как часть нашей docker-compose установки, все, что нам нужно сделать, - это запустить его в оболочку.
docker exec -it kafka-kafdrop_kafka_1 sh -c "cd /opt/kafka/bin && /bin/bash"
Опубликуйте несколько записей по теме с именем test (которая будет создана автоматически):
./kafka-console-producer.sh --broker-list localhost:9092 --topic test
Начни печатать. Нажмите Enter, чтобы начать новую запись. Когда закончите, нажмите CTRL+D. Затем обновите Kafdrop - в списке должна появиться тема test. Щелкните тему, а затем нажмите «Просмотр сообщений». В конце концов, вы попадете на экран, который выглядит примерно так:

Чтобы получать сообщения из командной строки, вернитесь в оболочку Docker и выполните следующее:
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --group test --from-beginning
Это начнёт отслеживать тему с первой записи. Для завершения нажмите CTRL-C.
Использование интерфейса командной строки - это нормально для начала, но в конечном итоге вы захотите публиковать и использовать записи из своего приложения. И для этого вам понадобится клиентская библиотека. Существуют библиотеки практически для любого языка.
Приведенные ниже примеры относятся к Java. Начиная с производителя:
final Properties producerProps = new Properties();
producerProps.setProperty("bootstrap.servers", "localhost:9092");
producerProps.setProperty("key.serializer",
StringSerializer.class.getName());
producerProps.setProperty("value.serializer",
StringSerializer.class.getName());
producerProps.setProperty("max.in.flight.requests.per.connection",
String.valueOf(1));
try (Producer<String, String> producer =
new KafkaProducer<>(producerProps)) {
while (true) {
final String value = new Date().toString();
System.out.format("Publishing record with value %s%n", value);
producer.send(new ProducerRecord<>("test", "myKey", value));
Thread.sleep(1000);
}
}
Этот простой пример будет публиковать запись один раз в секунду, установив для полезной нагрузки текущую дату / время. Свойство bootstrap.servers определяет список брокеров, к которым необходимо подключиться, через запятую. В нашем примере у нас только один - образ Kafka Docker. Вы можете предоставить альтернативные значения для свойств key/value.serializer, но использование сериализатора строк является наиболее гибким вариантом, поскольку он позволяет публиковать любое содержимое, выражаемое в виде строки Unicode.
Переходя к потребителю:
final Properties consumerProps = new Properties();
consumerProps.setProperty("bootstrap.servers",
"localhost:9092");
consumerProps.setProperty("key.deserializer",
StringDeserializer.class.getName());
consumerProps.setProperty("value.deserializer",
StringDeserializer.class.getName());
consumerProps.setProperty("group.id", "myGroup");
consumerProps.setProperty("auto.offset.reset", "earliest");
consumerProps.setProperty("enable.auto.commit",
String.valueOf(false));
try (Consumer<String, String> consumer =
new KafkaConsumer<>(consumerProps)) {
consumer.subscribe(Collections.singleton("test"));
while (true) {
final ConsumerRecords<String, String> records =
consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.format("Got record with value %s%n",
record.value());
}
consumer.commitAsync();
}
}
Это будет опрашивать Kafka в цикле, распечатывая каждую полученную запись и фиксируя смещения, когда это будет сделано. Запустите два приложения бок о бок. Вы должны увидеть одну публикацию записей, каждая из которых почти мгновенно появляется у потребителя. Переключитесь на Kafdrop, вы также должны увидеть, что записи сохраняются в теме test.
В качестве эксперимента вы можете запускать производственные и потребительские приложения в другом порядке, оставляя между ними некоторое время. Посмотри, что получится.
Примечание: большая часть разработки сосредоточена в основной библиотеке Java и rdlibkafka на основе C. Клиентские библиотеки на других языках, являющиеся оболочками для rdlibkafka стремятся быть стабильными, например Python и .NET. Однако будьте осторожны с некоторыми инди-библиотеками, которые изначально реализуют проводной протокол Kafka. По возможности используйте основную библиотеку или оболочку, написанную на вашем языке.
Вот и все. Вы сделали свой первый шаг к знанию Кафки. Есть чему поучиться, но это только начало.
Это быстро?
Kafka оптимизирован для пропускной способности, легко достигая миллионов записей в секунду на стандартном оборудовании. Уловка заключается в использовании журналов только для добавления, которые в значительной степени ограничены последовательным вводом-выводом, который выполняется быстро на самых разных носителях. Кроме того, Kafka будет накапливать несколько записей в пакете, что дополнительно способствует его производительности, особенно когда включено сжатие (поскольку сжатие обычно становится более эффективным с увеличением размера данных). Кроме того, пакетная обработка в основном выполняется как операция на стороне клиента, которая передает нагрузку на клиента и снижает использование полосы пропускания сети.
В целом, на стороне потребителя возникает изрядная тяжелая работа - к тому моменту, когда записи попадают к брокеру, они уже имеют хеширование ключей, контрольную сумму и выравнивание в промежуточном аккумуляторе потребителя - брокер в большинстве случаев просто выгружает их прямо на диск при получении. Брокеры также будут использовать прямые буферы, чтобы свести к минимуму ненужное переключение между ядром и пользователем и хранить данные вне кучи (таким образом, вне поля зрения GC).
В отличие от традиционных брокеров в стиле MQ, которые удаляют сообщения в точке потребления (что приводит к штрафу за случайный ввод-вывод), Kafka не удаляет сообщения после их использования - вместо этого он независимо отслеживает смещения в каждой точке. уровень группы потребителей. Ход смещений публикуется во внутренней теме Kafka __consumer_offsets. Опять же, поскольку это операция только для добавления, это быстро. Содержание этой темы дополнительно сокращается в фоновом режиме (с использованием функции сжатия Kafka), чтобы сохранить только последние известные смещения для любой данной группы потребителей.
Потребители в Kafka «дешевы», поскольку они не изменяют файлы журналов (это разрешено делать только производителю или внутренним процессам Kafka). Это означает, что большое количество потребителей может одновременно читать из одной и той же темы, не перегружая кластер. Поэтому вполне нормально видеть, что одна тема используется в нескольких потребительских экосистемах. Опять же, это то, чего вы не увидите в обычных брокерах сообщений.
Еще одна фундаментальная причина производительности Kafka, но это малоизвестный факт: Kafka на самом деле не вызывает fsync при записи на диск перед подтверждением записи; единственное требование для ACK - запись была записана в буфер ввода-вывода. Фактически это то, что на самом деле заставляет Kafka работать так, как если бы это была очередь в памяти, потому что для всех целей и целей она является дисковой очередью в памяти (ограниченной размером буфер / кэш страницы).
Какие у него недостатки?
- Задержка для начала. Поскольку Kafka оптимизирован почти исключительно для обеспечения пропускной способности, это не то, что вы могли бы назвать платформой обмена сообщениями с «низкой задержкой». Сквозные задержки могут достигать десятков или сотен миллисекунд. И хотя вы можете добиться улучшений, настроив некоторые параметры, Kafka не сравнится с некоторыми специализированными решениями с низкой задержкой, которые могут комфортно работать в субмикросекундном диапазоне. Не используйте его в таких приложениях, как высокочастотная торговля, где низкая предсказуемая задержка является обязательной.
- Слишком много настраиваемых регуляторов. Количество параметров конфигурации в Kafka может быть огромным не только для новичков, но и для опытных профессионалов. Добавьте в закладки официальную документацию Kafka, она вам понадобится.
- Небезопасные настройки по умолчанию. Авторы Kafka делают несколько смелых заявлений о надежности своих гарантий заказа и доставки. Тогда вам будет простительно предположить, что значения по умолчанию разумны, поскольку они должны отдавать предпочтение безопасности над другими конкурирующими качествами. Значения по умолчанию Kafka, как правило, оптимизированы для повышения производительности, и их необходимо явно переопределить на клиенте, когда безопасность является критически важной задачей. Обратите внимание на некоторые особенности:
enable.auto.commit- по умолчаниюtrue, что приводит к тому, что потребители фиксируют смещения каждые 5 секунд (настраиваетсяauto.commit.interval.ms), независимо от того, завершил ли потребитель обработку записи. Это может привести к смешанной семантике доставки - в случае отказа потребителя некоторые записи могут быть доставлены дважды, а другие могут не быть доставлены вообще. Установите значениеfalse, чтобы ваше приложение могло определять точку фиксации.max.in.flight.requests.per.connection- по умолчанию5, что может привести к тому, что сообщения будут опубликованы не по порядку, если время ожидания одного (или нескольких) помещенных в очередь сообщений истекает и повторяется. Установите1.
Это далеко не исчерпывающий список. Для этого я веду отдельную страницу Kafka Gotchas.
Знает ли Кафка о географии?
Географическая репликация не встроена в брокеры, и общепринято, что высокопроизводительные кластеры Kafka и растянутые топологии (где кластер охватывает географические регионы) несовместимы. Существует проект с открытым исходным кодом - MirrorMaker, который по сути представляет собой конвейер для перекачки записей из одного кластера в другой без сохранения каких-либо критических метаданных (например, смещений). Confluent предлагает собственный инструмент - Replicator, который сохраняет метаданные, но является частью лицензированного пакета Confluent Enterprise.
Поддерживает ли Kafka мультитенантность?
По словам разработчиков Kafka, он поддерживает мультиарендность. Но не слишком волнуйтесь. Его конструкция ограничена списками управления доступом (ACL) для разделения тем и поддержания квот, что создает иллюзию изоляции для клиентов, но не создает изоляцию в административной плоскости. Это все равно, что сказать, что ваш холодильник поддерживает несколько арендаторов, потому что он позволяет хранить продукты на разных полках. Настоящее многопользовательское решение предусматривает создание нескольких логических кластеров в более крупном физическом кластере. Эти логические кластеры можно администрировать отдельно; неправильная конфигурация ACL в одном логическом кластере, например, не повлияет на другие логические кластеры.
Это безопасно?
Конфигурация по умолчанию довольно упрощена с точки зрения безопасности, но это легко исправить. Kafka предоставляет несколько уровней контроля безопасности, которые работают аддитивно для обеспечения целостности и конфиденциальности данных. Они показаны на схеме ниже.

- Безопасность транспортного уровня. Kafka поддерживает TLS до версии 1.2 с идентификацией имени хоста, с индивидуально подписанными закрытыми ключами, назначаемыми каждому брокеру. Клиент настроен с использованием сертификата X.509, что дает ему уверенность в том, что брокеры на самом деле являются теми, кем они себя называют. В качестве дополнительной меры вы можете дополнительно включить сертификаты на стороне клиента, которые в дополнение к сертификатам сервера проверяют идентичность клиентов брокерам. (Это также называется взаимным TLS.)
- Аутентификация участника-пользователя: Kafka использует SASL (Simple Authentication and Security Layer) для привязки подключений к отдельным пользователям, например, индивидуальному разработчику или учетной записи службы. SASL поддерживает несколько подключаемых методов аутентификации, включая Kerberos, OAuth, SCRAM и некоторые другие.
- Авторизация с использованием ACL: Kafka поддерживает списки управления доступом (ACL) для ограничения действий аутентифицированных участников. Вы можете указать ограничения на чтение и запись тем, операции на уровне кластера, действия группы потребителей и транзакции. Вы также можете просматривать ACL с помощью Kafdrop.
Кроме того, вы должны разместить брандмауэр перед своим кластером Kafka, прежде чем открывать его для всего мира, оставив открытым только порт 9092 (или какой бы порт вы ни настроили для прослушивателей). ZooKeeper должен быть полностью заблокирован от внешнего мира - нет веских причин для предоставления клиентам доступа к ZooKeeper.
В заключение…
Мы только что прикоснулись к удивительно мощной технологии. Неповторимая и легко адаптируемая модель Кафки предлагает, казалось бы, безграничные возможности. Его можно использовать для реализации практически любого стиля распределенной системы при сохранении производительности и безопасности. Мы также признали его недостатки - в частности, некачественный инструментарий и сложность параметров конфигурации.
Если вы только начинаете, большинство уроков еще впереди. У вас есть основы и необходимые инструменты, и в Интернете нет недостатка в информации. Без сомнения, лучший способ научиться - засучить рукава и что-нибудь построить. Вы можете начать с того, что взяли существующее приложение и разбили его на набор слабосвязанных сервисов. Или вы можете пойти дальше и построить что-то новое с нуля. Попробуйте то, что вы всегда хотели, но никогда не могли найти подходящую возможность. Потому что вот оно.
Была ли эта статья вам полезна? Я хотел бы услышать ваши отзывы, так что не сдерживайтесь. Если вас интересуют Kafka, Kubernetes, микросервисы или потоковая передача событий, или у вас просто есть вопросы, подписывайтесь на меня в Twitter. Я также являюсь сопровождающим Kafdrop и автором Effective Kafka.