
ПРОГРАММНОЕ ОБЕСПЕЧЕНИЕ
Теория сложности алгоритмов
Как мы измеряем скорость наших алгоритмов
Теория сложности - это исследование количества времени, необходимого алгоритму для выполнения, в зависимости от размера входных данных. Разработчикам программного обеспечения очень полезно понимать, что они могут писать код эффективно. Есть два типа сложностей:
Сложность по пространству: сколько памяти требуется алгоритму для выполнения.
Сложность по времени: сколько времени требуется алгоритму для выполнения.
Обычно мы больше беспокоимся о временной сложности, чем о сложности пространства, потому что мы можем повторно использовать память, необходимую для выполнения алгоритма, но мы не можем повторно использовать время, необходимое для выполнения. Купить память легче, чем время. Если вам нужно больше памяти - вы можете арендовать место на сервере у таких поставщиков, как Amazon, Google или Microsoft. Вы также можете купить больше компьютеров, чтобы добавить больше памяти, не арендуя место на сервере. В оставшейся части этой статьи мы расскажем, как оптимизировать временную сложность.
Как мы измеряем сложность времени?
Новый компьютер обычно будет быстрее, чем старый компьютер, а настольные компьютеры обычно будут быстрее, чем смартфоны - так как мы действительно узнаем абсолютное время, которое занимает алгоритм?
Чтобы измерить абсолютное время, мы учитываем количество операций, выполняемых алгоритмом. Строительными блоками любого алгоритма являются операторы if и циклы. Они отвечают на вопросы: (1) Когда делать операции? (2) Сколько раз мы должны их повторить? Мы хотим писать код, используя как можно меньше операторов if и циклов для максимальной эффективности на любой машине.
Для анализа алгоритмов мы учитываем размер ввода n - количество элементов ввода. Мы хотим точно предположить, как время работы алгоритма соотносится с размером входных данных n. Это порядок роста: как алгоритм будет масштабироваться и вести себя с учетом входного размера n.
1. Input 10 items -> 10 ms 2. Input 100 items -> 100 ms (Good, linear growth) 3. Input 1,000 items -> 10,000 ms (Bad, exponential growth)
В приведенном выше примере, когда мы вводим 10 элементов, запуск занимает 10 мс. Когда мы вводим 100 элементов, это занимает 100 мс - это хорошо, поскольку рост нашего ввода увеличивается пропорционально времени выполнения.
Однако на следующем шаге мы вводим 1000 элементов, а это занимает 10 000 мс. Теперь на выполнение требуется в 10 раз больше времени по сравнению с увеличением размера ввода n. Теперь у нас экспоненциальный рост времени выполнения вместо линейного роста. Чтобы лучше понять различные порядки роста, мы рассмотрим нотацию большого О.
Диаграмма сложности Big-O
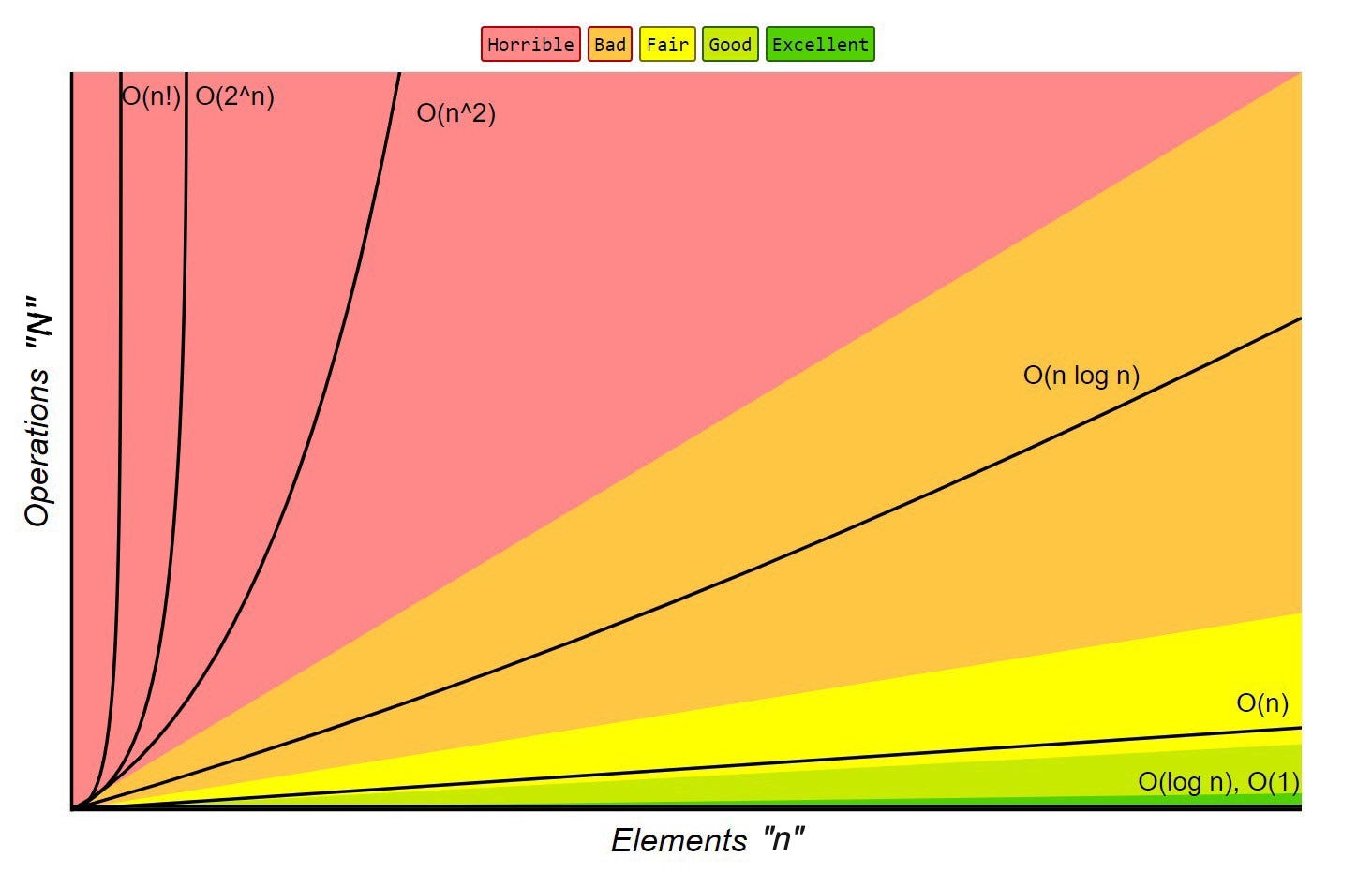
Обозначение большого o описывает ограничивающее поведение алгоритма, когда время выполнения стремится к определенному значению или бесконечности. Мы используем его для классификации алгоритмов по тому, как они реагируют на изменение размера входных данных. Мы обозначаем размер нашего ввода как n, а количество операций, выполняемых с нашими входами, как N. Мои примеры будут написаны на Python.
Мы предпочитаем алгоритмы, у которых есть линейнофмический порядок роста с точки зрения ввода или более быстрые, потому что более медленные алгоритмы не могут масштабироваться до больших размеров ввода. Вот список сложности выполнения в порядке убывания:
- O (1): Постоянная сложность по времени
- O (log (n)): Логарифмическая сложность
- O (n): Линейная сложность
- O (n * log (n)): линейная сложность
- O (n ^ k): Полиномиальная сложность (где k ›1)
- O (c ^ n): Экспоненциальная сложность (где c - константа)
- O (n!): Факторная сложность
Постоянная сложность времени: O (1)
Алгоритм выполняется за постоянное время, если время выполнения ограничено значением, не зависящим от размера ввода.
Первый пример алгоритма с постоянным временем - это функция обмена двумя числами. Если бы мы изменили определение функции, приняв миллион чисел в качестве входных данных, и оставим тело функции прежним, она все равно будет выполнять только те же три операции плюс оператор возврата. Среда выполнения не меняется в зависимости от размера ввода.
def swapNums(num1, num2):
temp = num1
num1 = num2
num2 = temp
return (num1, num2)В этом втором примере мы сначала проверим, является ли входящее сообщение “Hello World!”, и изменим сообщение на другое значение, если оно есть. После этого он будет повторяться три раза, выполняя еще один цикл, который распечатает сообщение 100 раз, то есть сообщение будет напечатано 300 раз. Несмотря на все эти операции - поскольку функция не будет выполнять больше операций в зависимости от размера ввода - этот алгоритм по-прежнему работает с постоянным временем.
def printMessage300Times(message):
if(message == "Hello World!")
message = "Pick something more original!"
for x in range(0, 3):
for x in range(0, 100):
print(message)
Логарифмическая сложность времени: O (log (n))
Логарифмический алгоритм очень масштабируем, потому что отношение количества операций N к размеру ввода n уменьшается, когда размер ввода n увеличивается. . Это связано с тем, что логарифмические алгоритмы не получают доступа ко всем элементам входных данных, как мы увидим в алгоритме двоичного поиска.
При двоичном поиске мы пытаемся найти наш входной номер num в отсортированном списке num_list. Наш входной размер n - это длина num_list.
Поскольку наш список отсортирован, мы можем сравнить num, который мы ищем, с числом в середине нашего списка. Если num больше среднего числа, мы знаем, что наш num может находиться только в большей части списка, поэтому мы можем полностью отбросить нижний конец списка и сэкономить время, не нуждаясь в процесс над ним.
Затем мы можем рекурсивно повторить этот процесс (который ведет себя как цикл) для большей половины списка, отбрасывая половину оставшихся num_list при каждой итерации. Вот как мы можем достичь логарифмической временной сложности.
def binarySearch(num_list, left_i, right_i, num):
if right_i >= left_i:
midpoint = left_i + (right_i - left_i)/2
if num_list[midpoint] == num:
return midpoint
elif num_list[midpoint] > num:
return binarySearch(num_list, left_i, midpoint-1, num)
else:
return binarySearch(num_list, midpoint+1, right_i, num)
else:
return "Number not in collection"
Сложность линейного времени: O (n)
Алгоритм выполняется за линейное время, когда время выполнения увеличивается максимально пропорционально размеру входных данных n. Если мы умножим ввод на 10, время выполнения также должно умножиться на 10 или меньше. Это связано с тем, что в алгоритме линейного времени мы обычно выполняем операции над каждым элементом ввода.
Нахождение максимального значения в несортированном наборе чисел - это алгоритм, который мы могли бы создать для работы в линейном времени , поскольку мы должны проверять каждый элемент во входных данных один раз, чтобы решить проблему:
def findMaxNum(list_of_nums): max = list_of_nums[0]for i in range(1, len(list_of_nums.length)): if(list_of_nums[i] > max): max = list_of_nums[i]return max
В цикле for мы перебираем каждый элемент нашего ввода n, обновляя при необходимости максимальное значение, прежде чем возвращать максимальное значение в конце. Другие примеры алгоритмов линейного времени включают проверку дубликатов в неупорядоченном списке или поиск суммы списка.
Сложность линейного времени: O (n * log (n))
Алгоритмы с линейным временем немного медленнее, чем алгоритмы с линейным временем, и по-прежнему масштабируемы.
Это умеренная сложность, которая колеблется вокруг линейного времени, пока ввод не достигнет достаточно большого размера. Самыми популярными примерами алгоритмов, работающих за линейное время, являются алгоритмы сортировки, такие как mergeSort, quickSort и heapSort. Посмотрим на mergeSort:
def mergeSort(num_list):
if len(num_list) > 1:
midpoint = len(arr)//2
L = num_list[:midpoint] # Dividing "n"
R = num_list[midpoint:] # into 2 halves
mergeSort(L) # Sort first half
mergeSort(R) # Sort second half
i = j = k = 0
# Copy data to temp arrays L[] and R[]
while i < len(L) and j < len(R):
if L[i] < R[j]:
num_list[k] = L[i]
i+=1
else:
num_list[k] = R[j]
j+=1
k+=1
# Checking if any element was left in L
while i < len(L):
num_list[k] = L[i]
i+=1
k+=1
# Checking if any element was left in R
while j < len(R):
num_list[k] = R[j]
j+=1
k+=1
«MergeSort» работает:
- Рекурсивное деление
num_list, пока элементы не станут двумя или меньше - Итеративная сортировка каждой из этих пар элементов
- Итеративное слияние наших результирующих массивов
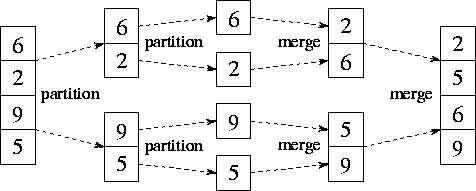
При таком подходе мы можем достичь линейного времени, потому что весь ввод n должен повторяться, и это должно происходить O (log (n)) раз (ввод может только быть уменьшенным вдвое O (log (n)) раз). Итерация n элементов log (n) раз приводит к времени выполнения O (n * log (n)), также известному как линейное время .
Сложность полиномиального времени: O (n ^ c), где c ›1
Алгоритм выполняется за полиномиальное время, если время выполнения увеличивается на тот же показатель c для всех входных размеров n.
На этот раз сложность и последующие не масштабируются! Это означает, что по мере увеличения размера ввода ваше время выполнения в конечном итоге станет слишком длинным, чтобы сделать алгоритм жизнеспособным. Иногда у нас возникают проблемы, которые нельзя решить более быстрым способом, и нам нужно проявить творческий подход к тому, как мы ограничиваем размер наших входных данных, чтобы мы не сталкивались с долгим временем обработки, создаваемым полиномиальными алгоритмами. Примером полиномиального алгоритма является bubbleSort:
def bubbleSort(num_list):
n = len(num_list)
for i in range(n):
# Last i elements are already in place
for j in range(0, n-i-1):
# Swap if the element found is greater
# than the next element
if num_list[j] > num_list[j+1] :
temp = num_list[j]
num_list[j] = num_list[j+1]
num_list[j+1] = temp
bubbleSort будет перебирать все элементы в нашем списке снова и снова, меняя местами соседние числа, когда обнаруживает, что они вышли из строя. Он останавливается только тогда, когда обнаруживает, что все числа находятся в правильном порядке.
На картинке ниже у нас всего семь предметов. Алгоритм выполняет итерацию по всему набору три раза, чтобы отсортировать числа - но если бы это было 100 чисел, легко увидеть, как время выполнения может стать очень длинным. Не масштабируется.
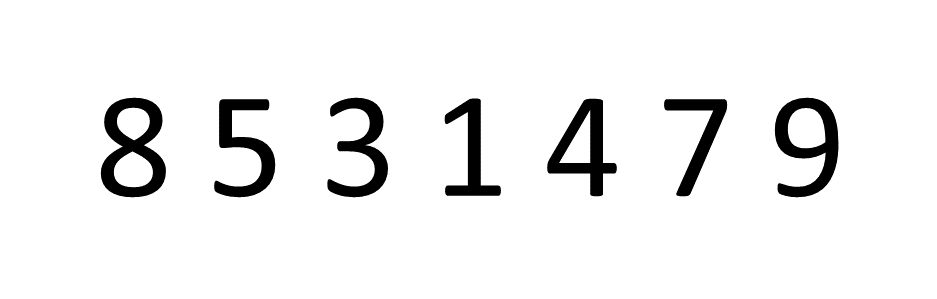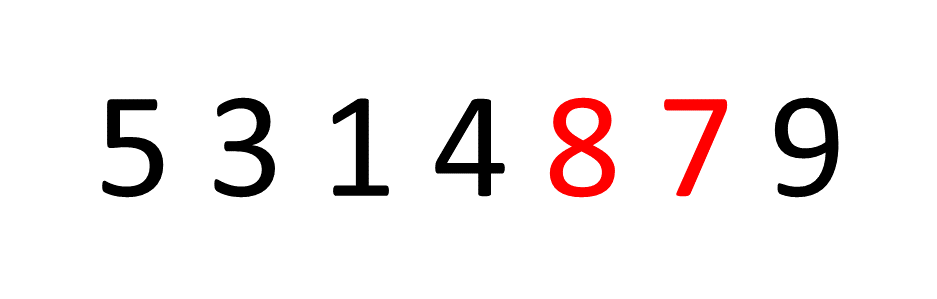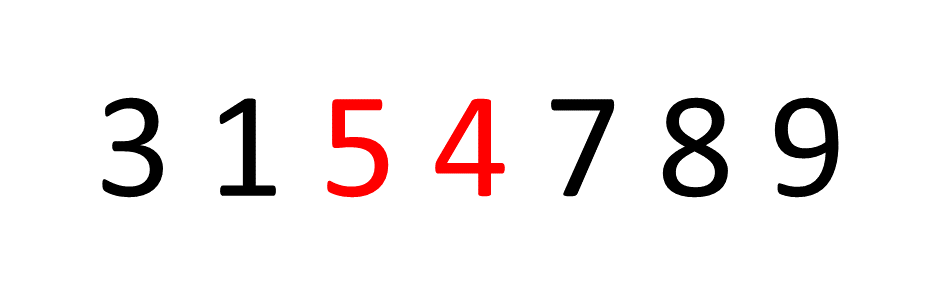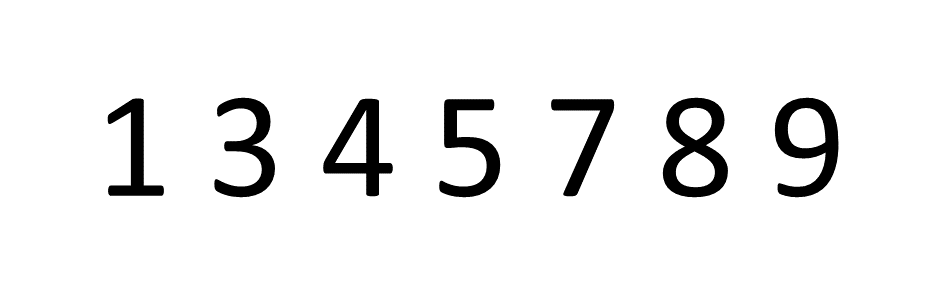
Экспоненциальная сложность времени: O (c ^ n), где c - константа
Алгоритм выполняется за экспоненциальное время, когда время выполнения удваивается при каждом добавлении к входному набору данных. Рекурсивное вычисление чисел Фибоначчи является примером алгоритма экспоненциального времени:
def fibonacci(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return fibonacci(n-1) + fibonacci(n-2)
Этот алгоритм дважды вызывает себя в последней строке - один раз с n-1 и один раз с n-2. Это означает, что если бы мы начали с n = 7, мы бы вызывали функцию всего 25 раз! Запускать по мере роста ввода очень дорого.
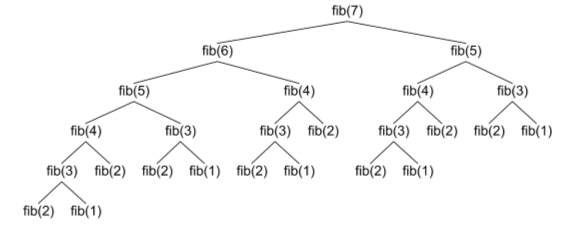
Факторная временная сложность: O (n!)
Наконец, алгоритм выполняется за факториальное время , если он повторяет входные данные n количество раз, равное n умножается на все положительные целые числа меньше n. Это самая медленная временная сложность, которую мы обсудим в этой статье, и она в основном используется для вычисления перестановок коллекции:
def getListPermutation(items_list):
results = []
i = 0
l = len(items_list)
while i < l:
j, k = i, i + 1
while k <= l:
results.append(" ".join(items_list[j:k]))
k = k + 1
i = i + 1
print resultsЗаключение
Спасибо за прочтение! Я хотел бы услышать ваши отзывы или ответить на любые ваши вопросы.