Сверточные нейронные сети (CNN) появились в результате изучения зрительной коры головного мозга и используются для распознавания изображений с 1980-х годов. За последние несколько лет в области глубокого обучения произошли огромные улучшения, особенно когда речь идет о вычислительных мощностях. Кроме того, исследователи разработали множество уловок для сходимости нейронных сетей, таких как решение проблемы взрывающихся и исчезающих градиентов, повторное использование предварительно обученных слоев, использование более быстрых оптимизаторов (импульс, RMSProp, ...), предотвращение переобучения посредством регуляризации и т. д. Используя эти уловки, CNN удалось реализовать сверхчеловеческие способности при решении некоторых сложных визуальных задач. Они используются в беспилотных автомобилях, системах автоматической классификации видео, системах поиска изображений (дедупликация, сходство, магазин и т. Д.). CNN не ограничиваются визуальным восприятием, они также успешно справляются с другими задачами, такими как обработка естественного языка (NLP) или распознавание голоса, однако в этой статье мы будем специализироваться на визуальных приложениях.
Можно спросить, зачем CNN для задач распознавания изображений? Почему бы просто не использовать обычную глубокую нейронную сеть?
К сожалению, это отлично работает для небольших изображений (например, MNIST), в то время как система не работает для больших изображений из-за огромного количества параметров, необходимых для обучения модели. Например, изображение размером 224x224 имеет 50176 пикселей, и если первый слой содержит всего 1000 нейронов (чего недостаточно), это означает, что у нас будет достаточно 50 миллионов соединений, а это только первый слой. Представьте, сколько подключений у нас будет для всей сети. CNN решает эту проблему, используя частично связанные уровни.

Сверточный слой
Самым важным строительным блоком сети CNN является сверточный слой. Нейроны в первом слое CNN связаны не с каждым пикселем входного изображения (как в обычных нейронных сетях), а только с пикселями в своих рецептивных полях. То же самое относится и к следующему уровню, как показано на изображении ниже (см. Рисунок 2).
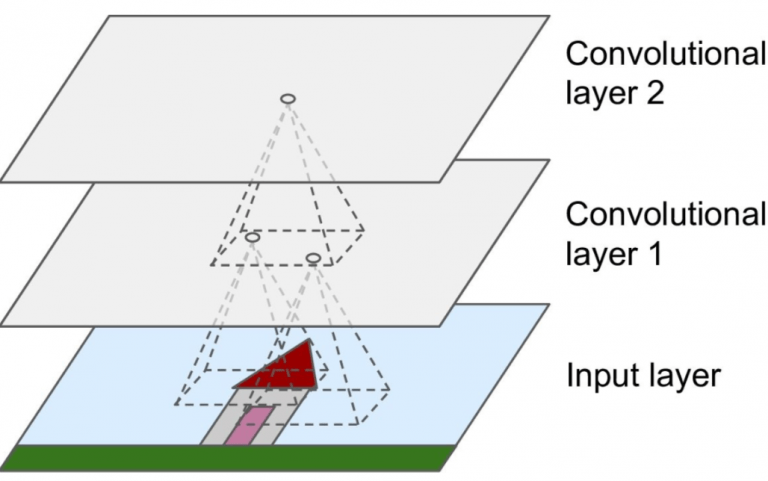
Свертка - это математическая операция, которая накладывает одну функцию на другую и измеряет интеграл от их поточечного умножения. Инженеру по машинному обучению не обязательно понимать формулу, лежащую в основе сверток, но при желании он может углубиться в математику, лежащую в основе сверточных нейронных сетей.
В сверточной нейронной сети каждый сверточный слой содержит серию фильтров, называемых сверточными ядрами.
Примечание: распространенной ошибкой является использование слишком больших ядер свертки, например, вместо использования ядра 5x5, как правило, предпочтительнее складывать 2 слоя с ядрами 3x3, что позволит сети использовать меньше параметров и вычислять быстрее и обычно он работает лучше.
Фильтры
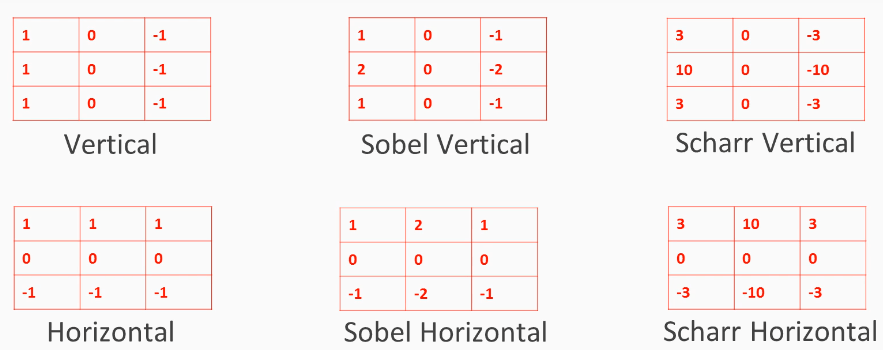
Фильтр - это матрица целых чисел, которая используется для подмножества входных значений пикселей, того же размера, что и ядро. Каждый пиксель умножается на соответствующее значение в ядре, затем результат суммируется для получения единственного значения для простоты представления ячейки сетки, такой как пиксель, на карте функций (карты функций CNN фиксирует результат применения фильтров к входному изображению.). В большинстве случаев инженеры машинного обучения визуализируют карту функций для конкретного входного изображения, чтобы попытаться получить некоторое понимание того, что обнаруживает наша CNN. На изображении ниже мы увидим ряд наиболее часто используемых фильтров в задачах компьютерного зрения.
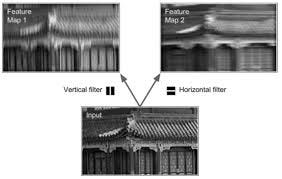
Вот как выглядит карта признаков, если мы применим к входному изображению вертикальный и горизонтальный фильтры. В результате у нас будет две карты функций, которые мы хотели бы сложить вместе.
Короче говоря, сверточный слой одновременно применяет несколько фильтров к своим входам, что делает его способным обнаруживать несколько функций в любом месте своего входа, в то время как обычная глубокая нейронная сеть научилась распознавать шаблон в одном месте, она может распознавать его только в этом конкретном месте. . Фильтр может выполнять обнаружение краев и обучаться обнаруживать абстрактные понятия, такие как граница лица или плечи человека. В CNN фильтры не определены заранее (горизонтальные, вертикальные, по Собелю и т. Д.), Но изучаются в процессе обучения.
Шаг и набивка
После выбора размера фильтра нам также необходимо выбрать шаг и отступ. Stride контролирует, как фильтр вращается вокруг входной громкости. В этом примере (рисунок 5) фильтр 3x3 вращается вокруг входного объема (синяя область), сдвигая по одной единице за раз (мы перемещаемся по горизонтали и вертикали на 1 пиксель за раз). Величина, на которую смещается фильтр, и есть шаг. В этом случае шаг был неявно установлен на 1 (s = 1). Шаг обычно устанавливается таким образом, чтобы выходной объем был целым числом, а не дробью (в противном случае мы преобразуем дробные значения в целые числа). Таким образом, Stride - один из важных гиперпараметров, который представляет собой не что иное, как количество, на которое фильтры скользят по изображению.

Кроме того, одним из важных приемов применения фильтров для включения входных данных является использование отступов. Это дополнительный слой, который мы можем добавить к границе изображения. В качестве примера см. Рисунок выше (рис.5).
Представьте, что мы применяем задачу классификации изображений или задачу распознавания лиц. Пиксель в углу будет покрыт только один раз, но если мы возьмем средний пиксель, он будет покрыт более одного раза. Это означает, что у нас будет больше информации об этом среднем пикселе, в то время как пиксель в углу может содержать релевантную информацию, на которую сеть не фокусируется.
Уровень объединения
Как только мы поймем, как работает сверточный слой, будет легко уловить смысл, стоящий за объединяющими слоями. Их цель - уменьшить входное изображение, чтобы уменьшить вычислительную нагрузку, очевидно, , использование памяти и количество обучаемых параметров, предотвращающих переобучение сети.
Подобно сверточному слою, каждый нейрон в слое объединения подключен к выходам ограниченного числа нейронов из предыдущего слоя, расположенных в небольшом прямоугольном воспринимающем поле (см. Рисунок 1.). Как и в слое Conv, нам нужно определить его размер, шаг, тип заполнения (то же самое, допустимое). Тем не менее, уровень объединения не имеет весов, он только агрегирует входные данные, используя функцию агрегации, такую как максимальное или среднее значение. Наиболее распространенные типы объединения - это максимальный пул и средний пул.
В приведенном ниже примере мы используем ядро пула 2x2, шаг 2 и отсутствие отступов. Обратите внимание, что в левой матрице только максимальное входное значение в каждом ядре попадает на следующий уровень, в то время как в матрице справа идея среднего пула заключается в вычислении среднего значения каждого пула ядра.

Теперь мы знаем все строительные блоки для создания сверточной нейронной сети. Давайте посмотрим, как их собрать. Я считаю, что изучение эволюции победивших статей - хороший способ понять, как работают CNN.