Простое описание технических концепций в интервью

Я видел много вопросов на собеседовании по науке о данных, в которых вас просят «описать мне [вставить концепцию науки о данных], как если бы я был пятилетним ребенком. Обсудив это с моей сестрой, которая учится на учителя начальной школы, мы решили, что этот вопрос немного преувеличен, возможно, для акцента или для того, чтобы привлечь внимание. Поэтому я решил сохранить броское название, но эта статья будет немного больше сосредоточена на объяснении этих концепций взрослому, не имеющему технического образования. Однако, чтобы придерживаться темы, я также создал графику, сопровождающую каждый ответ, чтобы изобразить рисунок, которым я бы сопровождал свое объяснение, если бы у меня был доступ к доске.
Темы следуют в следующем порядке:
- Статистика и подготовка данных
- Концепции модели машинного обучения
- Оценка моделей
Проверка гипотез и Т-тесты
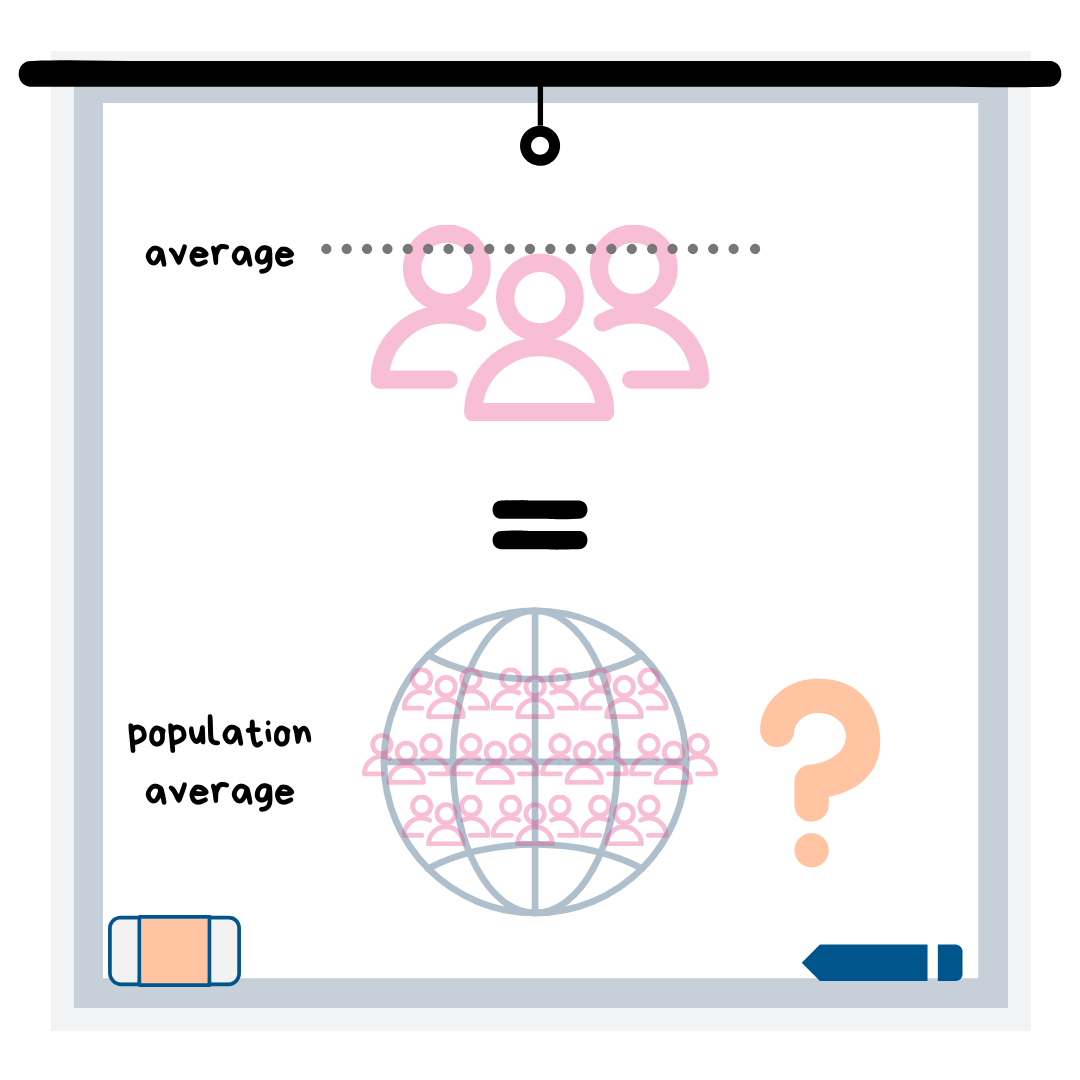
Для проверки гипотез вы сначала начинаете с вопроса о большой группе. Например, каков средний рост американцев? Вы предполагаете, что это 5 футов 8 дюймов (просто исходя из личного опыта). Вы знаете, что не можете реально измерить рост каждого американца, поэтому вы случайным образом выбираете меньшую группу для измерения (случайная выборка).
Чтобы узнать, действительно ли средний рост всех американцев составляет 5 футов 8 дюймов, вы должны провести проверку гипотез! В этом примере вам нужно будет использовать t-критерий для одной выборки, который имеет конкретное уравнение, в которое я не буду углубляться. Здесь важно знать, что вам нужно знать количество людей, которых вы измерили, их средний рост и стандартное отклонение их роста (то есть, насколько далеко их рост от среднего).
Когда вы получаете значение (t-значение) из t-теста, вам нужно использовать диаграмму или программу, чтобы оценить, можете ли вы сделать вывод, что уверены - 95% уверены, что это средний рост американцев. . Если ваше значение t больше 1,96 или меньше -1,96, вы бы сказали, что отвергаете свою гипотезу о том, что средний рост всех американцев составляет 5 футов 8 дюймов. Если оно находится в пределах этого диапазона, вы «не можете отклонить «(Это жаргон статистики) ваша гипотеза и сделайте вывод, что это фактический средний рост американцев.
Анализ главных компонентов (PCA)
Иногда у вас есть набор данных, в котором так много столбцов (переменных), с которыми сложно работать. Помещение всех этих переменных в модель приведет к тому, что она будет работать медленно, а также будет трудно визуализировать взаимосвязь между вашей зависимой переменной (той, которую вы пытаетесь предсказать) и всеми другими вашими переменными одновременно. Здесь на помощь приходит PCA!


Внимание, я определенно оставляю объяснения 5-летней давности для этого. С помощью сложной математики (линейной алгебры) PCA преобразует ваши переменные в «компоненты». График слева называется биплотом и показывает, что компонент 1 и компонент 2 состоят из четырех исходных переменных. Однако каждая переменная представлена в одном компоненте больше, чем в другом. Зеленый вектор (переменная 2), например, имеет высокие значения компонента 1, но остается ниже 0,2 для значений компонента 2. Таким образом, переменная 2 составляет более значительную часть компонента 1, чем компонент 2.
Здесь цель состоит в том, чтобы иметь меньшее количество компонентов, чем количество переменных, которые у вас есть (чтобы ваша модель могла работать быстрее). Кроме того, вы хотите, чтобы ваши компоненты сохраняли как можно больше информации об исходных переменных. Чтобы проанализировать это и выбрать, сколько компонентов включить в модель, вы должны взглянуть на показатель, называемый объясненным коэффициентом дисперсии. Этот показатель сообщает вам, какой процент от общей дисперсии в наборе данных «объясняет» каждый компонент. Надеюсь, первая иллюстрация в этом разделе проясняет эту идею. В идеальном сценарии вы должны выбрать количество компонентов для включения в модель, сложив каждый из них объясненный коэффициент дисперсии, пока не достигнете совокупной суммы около 80% или 0,8.
Наконец, еще одно уточнение: вы теряете некоторую способность интерпретировать результаты своей модели, когда используете компоненты PCA. Лучшее, что вы можете сделать, когда выясните, какие компоненты значимы в вашей модели, - это посмотреть на биплоты, подобные приведенному выше, чтобы показать, как каждая из ваших переменных вносит информацию в каждый из ваших компонентов.
SQL (язык структурированных запросов) объединяется
Допустим, у вас есть база данных, которая действительно похожа на набор листов или таблиц Excel. Соединения SQL легче всего понять на примере, поэтому вот как выглядят примеры таблиц:
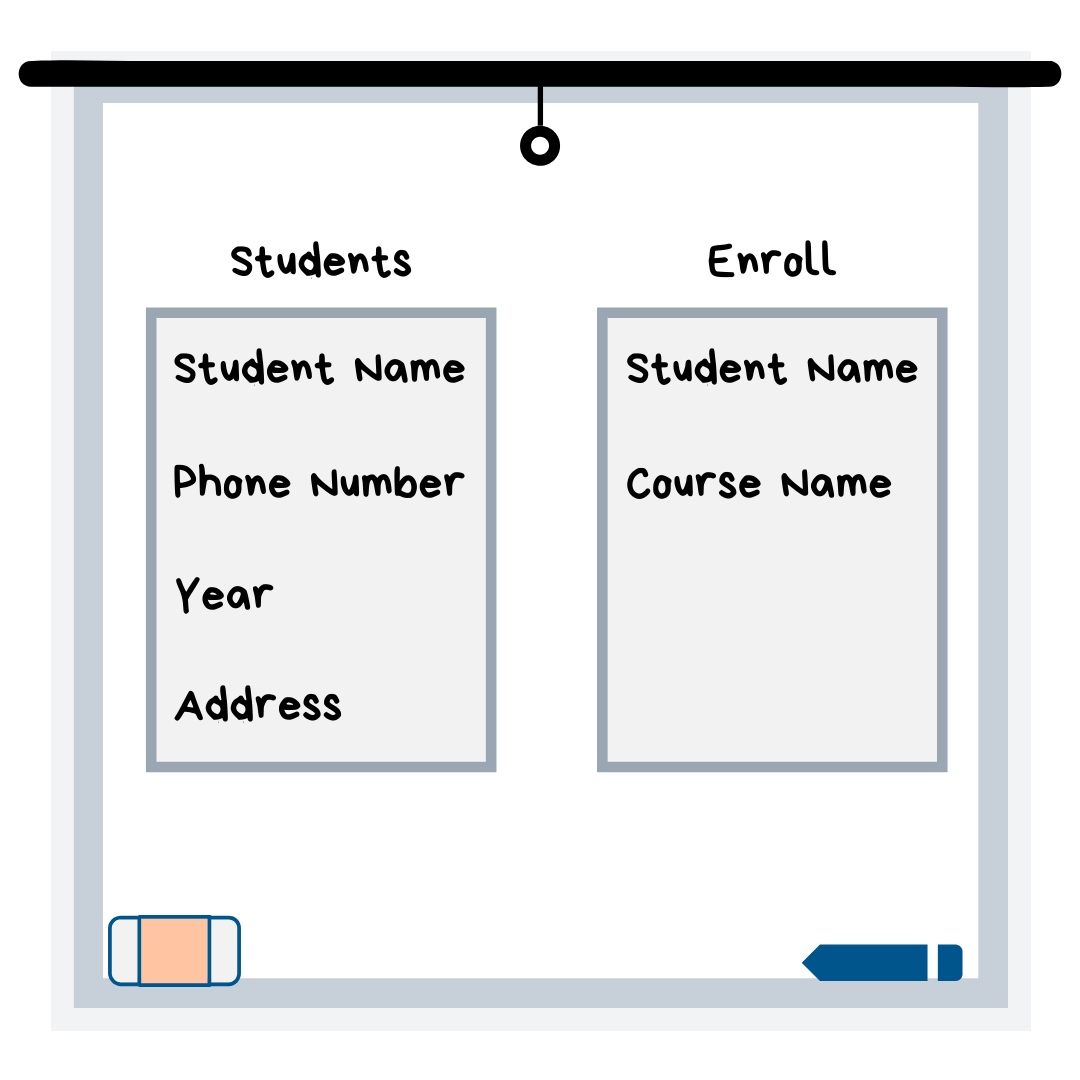
В этом примере предположим, что есть некоторые студенты, информация о которых есть в таблице студентов, но их нет в таблице регистрации, потому что они в настоящее время не записаны в классы. Кроме того, в классы записаны ученики, информация о которых у нас отсутствует в таблице учеников. Вот что вам скажет каждый тип соединения:
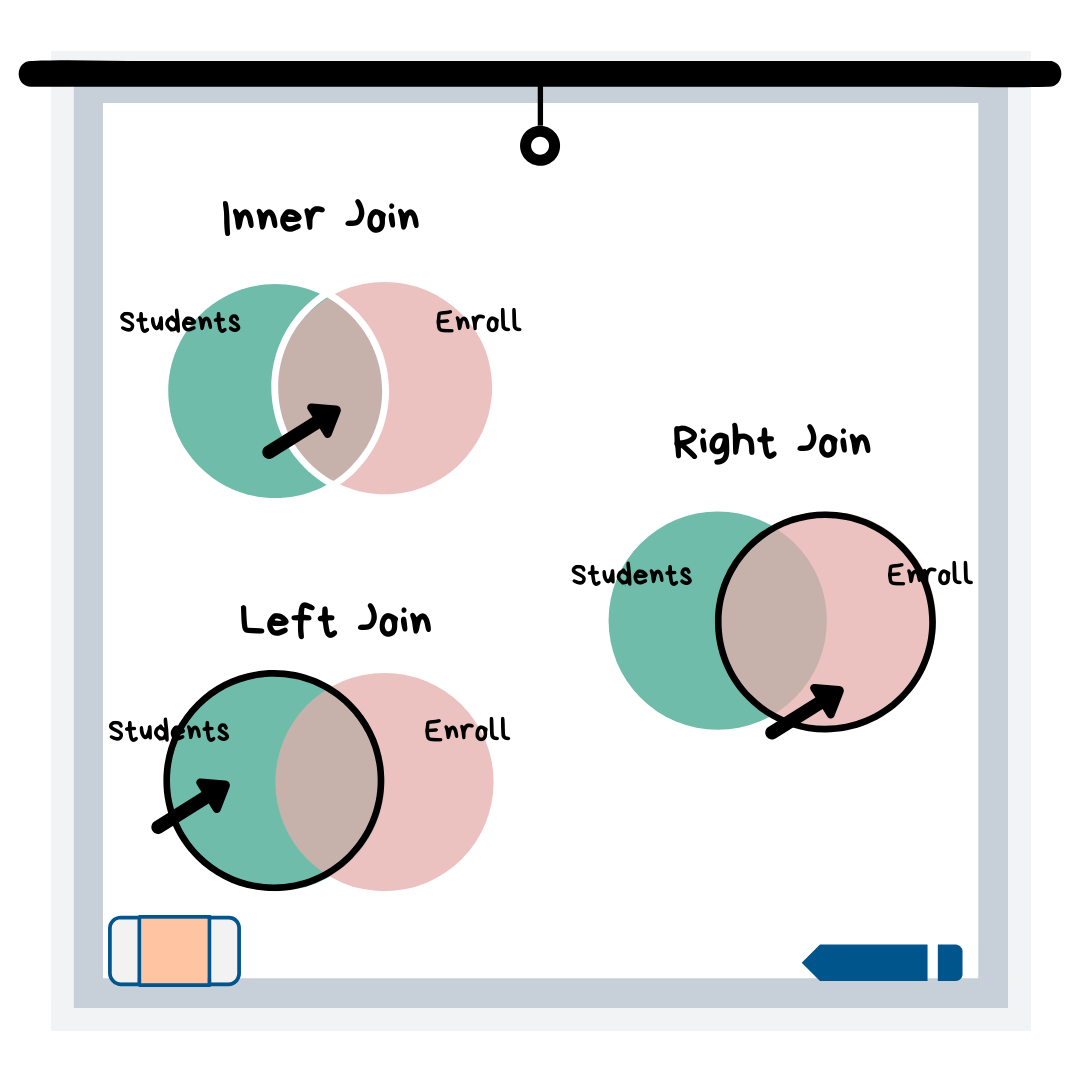
- Внутреннее присоединение: запись + информация о студенте для каждого студента, которая указана как в таблице студентов , так и в таблице регистрации.
- Правое присоединение: запись + информация об учащемся только для учащихся, зарегистрированных в классе.
- Левое соединение: информация об учащемся + информация о зачислении только для учащихся в таблице учащихся.
Итак, тип соединения SQL, который вы хотите использовать в своем запросе (также известный как ваш код, который вы отправляете в базу данных для возврата данных), зависит от информации, которую вы хотите знать. Если вы хотите узнать номера телефонов студентов, которые зачислены в классы, используйте внутреннее соединение. Если вам нужны имена и год обучения каждого ученика, а также классы, в которых они учатся, если они участвуют в чем-либо, тогда вы должны использовать левое соединение.
Теперь мы переходим на территорию моделирования.
Компромисс смещения / отклонения
Это сложно объяснить нетехнической аудитории, так что потерпите меня.
Компромисс смещения / дисперсии - это классическая концепция науки о данных, которая гласит, что при создании моделей существует неизбежный компромисс между смещением и дисперсией. Я начну с описания обоих этих терминов, а затем кратко объясню, почему между ними есть компромисс.
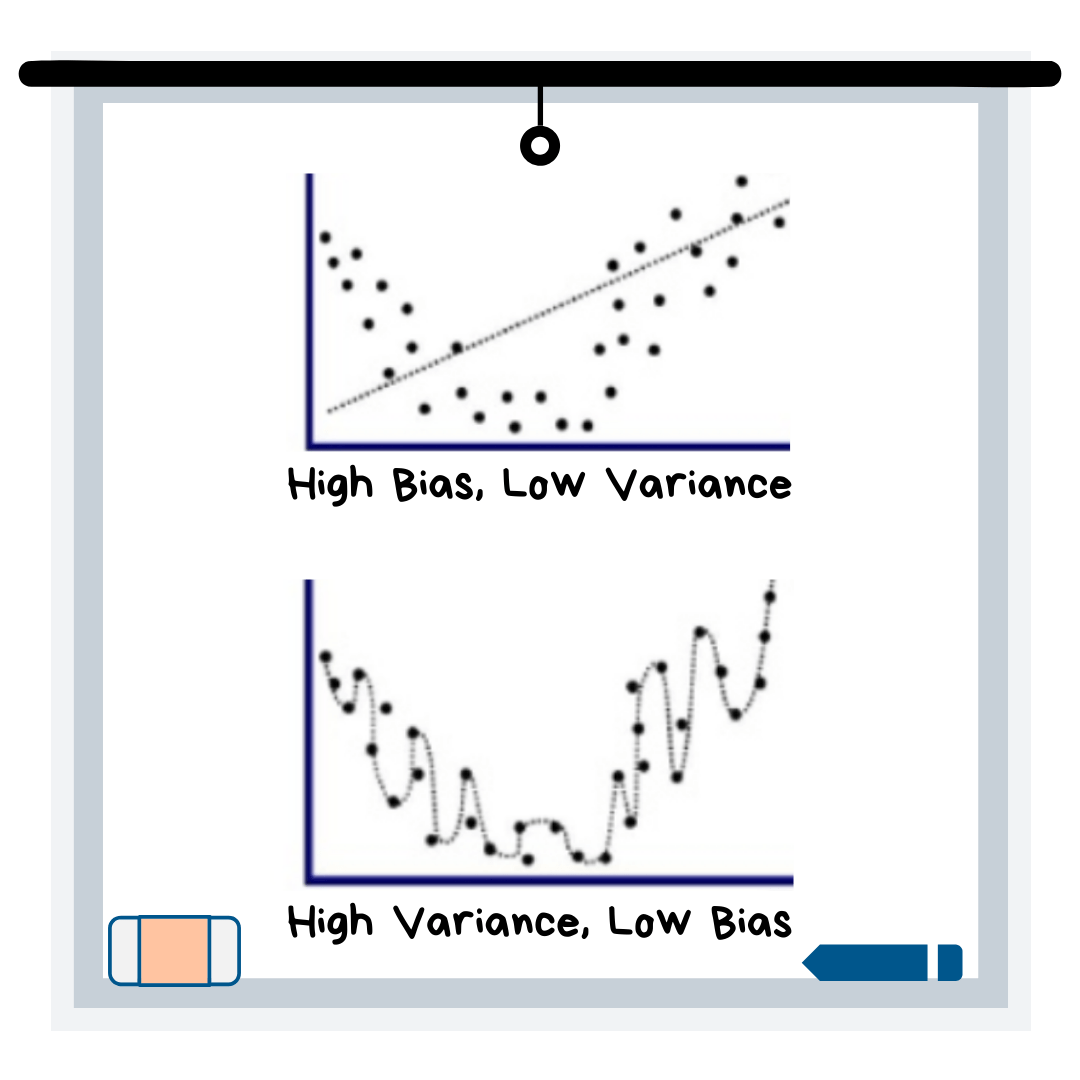
Смещение. Модель с большим смещением не очень хорошо "соответствует" данным. Другими словами, его точность низкая для данных, которые вы используете для создания модели (обучающих данных), и данных, которые вы используете для тестирования модели (подробнее о тестирование, см. раздел перекрестной проверки). Высокая систематическая ошибка указывает на то, что в ваших данных чего-то не хватает или вы используете неправильную модель! Пример: ваши данные выглядят как полином 2-го порядка (x²), но вы пытаетесь использовать линейную модель (x) для прогнозов, как на верхнем графике на иллюстрации.
Дисперсия. Модель с высокой дисперсией очень чувствительна к небольшим изменениям независимых переменных набора данных. Эта проблема связана с переобучением, когда ваша модель соответствует данным, которые вы обучаете с помощью слишком хорошо, потому что она определяет шум (или случайность) в наборе данных как важный, хотя на самом деле это не так. Таким образом, когда вы вводите новые данные, которых раньше не было, у них низкая производительность при прогнозировании. Пример: вы подбираете данные, которые имеют отношение полинома 2-го порядка (x²) с полиномом 20-го порядка, x²⁰ (см. Графики выше).
Компромисс между этими двумя проблемами существует, потому что по мере того, как вы настраиваете свою модель для лучшего соответствия вашим данным, вы уменьшаете смещение, но обязательно увеличиваете дисперсию. Существует противоречие между недостаточным и чрезмерным соответствием модели собранным вами данным.
Деревья решений и случайные леса

Изображение слева - одно из самых простых деревьев решений, которые вы могли бы сделать. Вы начинаете сверху и задаете вопросы о своем наблюдении (строка в наборе данных) и следуете по дереву вниз, пока не достигнете результата, который будет вашим прогнозируемым значением y.
С помощью деревьев решений легко приспособить их к вашим данным. Худший вариант этого был бы, если бы каждый результат вашего дерева представлял ровно одно наблюдение в вашем наборе данных.
Для решения этой проблемы используются модели случайного леса. По сути, программа сгенерирует набор деревьев решений, и каждое из них будет выглядеть немного по-разному из-за случайности, связанной с тем, где модель разделяет решение. Затем результаты всех этих деревьев усредняются, чтобы получить окончательный прогноз. Этот метод позволяет создавать деревья меньшего размера и уменьшать дисперсию модели, сохраняя при этом ее точность, поэтому он очень популярен.
И, наконец, немного о проверке ваших моделей.
Перекрестная проверка
Перекрестная проверка - лучший способ оценки любой модели машинного обучения. На изображении ниже показано, как бы вы разделили набор данных, если бы хотели выполнить перекрестную проверку 3 раза (3-кратная перекрестная проверка).

Для каждого разбиения приведенных выше данных вы должны построить свою модель на сегментах поезда и протестировать ее (сгенерировать прогнозы) на тестовом наборе. Затем вы можете усреднить оценку точности для каждого разделения, чтобы получить хорошее представление о том, насколько хороша ваша модель. Специалисты по обработке данных делают это, потому что тогда они могут использовать меньший общий объем данных и могут тестировать свою модель на большем количестве данных, которые модель не видела раньше.
Когда работодатели задают эти вопросы, они, кажется, хотят оценить две вещи:
- Достаточно ли вы знаете эту концепцию, чтобы разбить ее на части?
- Можете ли вы объяснить сложные технические концепции интуитивно понятным, простым и лаконичным образом?
Я надеюсь, что эта статья помогла вам разобраться в концепциях, пытаетесь ли вы понять их сами или лучше объяснить другим. Если у вас есть ребенок около 5 лет, было бы замечательно, если бы вы могли объяснить ему один из них и сообщить мне, как все прошло. (Я предполагаю, что они могут быть немного запутаны.) Кроме того, если какая-либо из этих тем все еще остается для вас непонятной, сообщите мне!
Спасибо за прочтение! Посмотрите мою вторую статью в этом мини-сериале здесь:
Вся графика сделана на www.canva.com