Депрессия - тихий убийца. Люди могут впадать в депрессию по разным причинам: потеря любимого человека, безработица, видение чего-то тревожного, домогательства и т. Д. Если с депрессией не бороться здоровым образом, она может серьезно ухудшить нашу активность и интерес к жизни.
В этой статье я представляю, как машинное обучение можно использовать для лечения депрессии. Представьте, что вы разговариваете с чат-ботом или голосовой службой, которая определяет настроение в вашем тоне, например гнев, страх или печаль, и на основе этого голосовая служба пытается сделать вас счастливыми. Именно поэтому мне пришла в голову идея разработать чат-бота Depression Assistant с использованием машинного обучения.
Данные:
Для разработки чат-бота я использовал набор данных Tweet Sentiment Classification, доступный по адресу http://saifmohammad.com/WebPages/EmotionIntensity-SharedTask.html. По этой ссылке есть данные для 4 различных эмоций: гнева, страха, радости и печали. В каждой строке данных есть твит, затем эмоция, выраженная в твите, а затем интенсивность этой эмоции. Пример того, как выглядит набор данных, показан ниже:
В моей крови кипит злость 0,875
Но не каждый твит в наборе данных гнева выражает гнев, например:
@someoone Буквально рассмеялся. гнев 0,067
Приведенный выше твит, хотя и присутствует в наборе данных о гневе, не выражает гнев. Это также видно по интенсивности гнева, добавленной в конце твита. Это всего лишь 0,067, что означает, что твит не выражает гнев. То же самое и с другими наборами данных эмоций.
Чтобы разработать полный набор данных, я загрузил твиты для 4 эмоций и проанализировал их, используя порог 0,5, так что в моем наборе данных остались только те твиты, которые «сильно» выражают классифицированную эмоцию.
Предварительная обработка:
Всего у нас 3751 твит в обучающих данных, 938 в тестовых данных и 7578 уникальных слов, включая смайлики. Были реализованы следующие стандартные методы предварительной обработки, используемые в задачах обработки естественного языка (NLP):
- Удаление знаков препинания и специальных символов, включая @ и #, которые присутствуют в твитах.
- Делаем твиты строчными буквами.
- Токенизация каждого твита.
- Выделяя каждое слово по краю, чтобы получить кратчайшую форму каждого слова. Например, «извлечение», «извлекается», «извлекает» сводятся к основанию «извлекать».
- Создание модели пакета слов и горячего кодирования каждого твита. Получаем мешок слов из 7578 уникальных слов. Мы используем подход с горячим кодированием для наших данных, то есть у нас есть вектор длиной 7578, и мы помещаем 1, когда слово в твите соответствует слову в пакете слов, и 0 в другом месте.
- В конце мы перемешиваем набор данных, разделяя данные на обучающий набор 80:20: разбиение тестового набора.
Модель машинного обучения:
Для этой задачи я решил использовать нейронные сети, которые представляют собой модель машинного обучения, и спроектировал ее с нуля без использования библиотек. Я использовал одну нейронную сеть скрытого слоя со 100 нейронами в скрытом слое и 4 нейронами в выходном слое, так как есть 4 класса, основанные на 4 эмоциях (гнев, страх, радость или грусть). Следующий рисунок дает представление о том, как выглядит наша модель нейронной сети со всеми размерами матриц данных, показанными для облегчения понимания.

На скрытом слое у нас будут следующие вычисления внутри каждого нейрона:
Z1 = W1 * X + b1
где «W1» равно 100 (нейроны в скрытом слое) x 7578 (слова), а «X» - это наш вход, который имеет размер 7578 (уникальные слова) x 3751 (твиты). «B1» - это смещение, равное 100 (нейронов) x 1. На самом деле X составляет 3751 (твитов) x 7578 (уникальных слов) в обучающем наборе, но на приведенном выше рисунке я намеренно показал транспонированные размеры входных данных X, чтобы понять умножение матриц, как В противном случае W1 не даст скалярного произведения на X, поскольку для умножения матриц строки Matrix1 должны быть равны столбцам матрицы 2 и наоборот.
Таким образом, «Z1» будет иметь размер 100 x 3751, который затем будет обрабатываться функцией активации ReLU как,
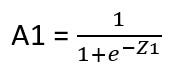
где «A1» означает «Z1», обработанный формулой функции активации ReLU. «A1» будет иметь тот же размер, что и «Z1», то есть 100x3751.
На выходном слое у нас будут следующие вычисления в каждом нейроне. Умножаем «A1» на весовой вектор «W2» как,
Z2 = W2*A1+b2
где «Z2» - скалярное произведение «W2» и «A1», добавленных с вектором смещения «b2», имеющим размер 4 (нейроны в выходном слое) x 1. Наконец, «Z2» будет иметь размер 4x3751, потому что «W2» имеет размерность 4 ( нейроны в выходном слое) x 100 (нейроны в скрытом слое) и «A1» имеет размеры 100x3751. Таким образом, их скалярное произведение, добавленное со смещением «b2», даст нам «Z2» с размерностью 4x3751.
Наконец, мы применяем функцию активации softmax, чтобы определить класс твита как,
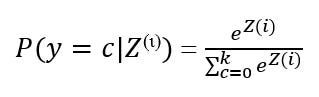
Короче говоря, функция softmax сообщает нам вероятности того, насколько вероятно, что входные данные принадлежат определенному классу. Мы прогнозируем, что класс с вероятностью выше, чем другие, будет прогнозируемым выходным классом.
(Извините, что так много внимания уделяю размерам, но важно понимать, что для работы нейронных сетей)
Тренировочный процесс:
Модель обучена для 50 эпох, скорость обучения сохраняется 0,1. Наблюдается потеря набора после обучения и проверки. Видно, что наша модель хорошо сходится.

Следующая кривая показывает точность нашей модели, которая очень хороша для всех классов.

Чат-бот в работе
После обучения модели мы запускаем нашего чат-бота. Для этого я просто использую команду ввода Python в блокноте jupyter, а затем пользователь вводит свое мнение. Модель пропускает его через обученную модель и сообщает, какая эмоция присутствует, а также насколько она доминирует среди других эмоций.
Если эмоция пользователя выражает гнев / страх / печаль, чат-бот предлагает пользователю шутку. На следующем рисунке показан этот процесс.
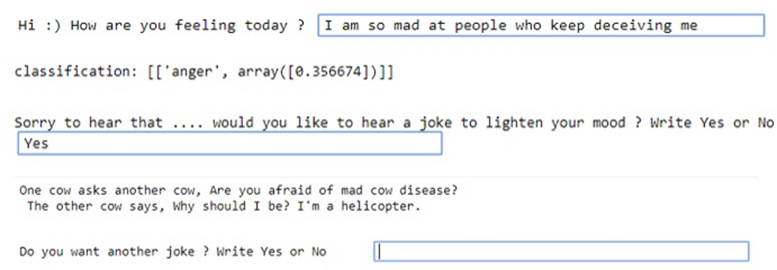
Это продолжается, если пользователь продолжает спрашивать другую шутку. Существует около 70 (на самом деле веселых) шуток, которые загружаются из текстового файла и показываются пользователю. Чат-бот закрывается, когда пользователь пишет «Нет».
Заключение:
Это простое расширение классификации настроений в твитах для чат-бота-помощника по депрессии может оказаться спасительным или подбадривающим средством для людей, переживающих тяжелые времена. Надеюсь, я не потерял своих читателей в матрицах: P
Будущая работа будет включать в себя более эффективную технику, чем один метод горячего кодирования для построения надежной модели.
Это моя первая статья на Medium.com. Я надеюсь, что этот проект будет полезен изучающим машинное обучение, НЛП и нейронные сети. Код вместе со всеми данными присутствует в моем профиле GitHub по адресу https://github.com/shayanalibhatti/Depression-Assistant-Chatbot.
Не забывайте хлопать в ладоши, если вам понравилась эта реализация :)