
Введение
Всемирная организация здравоохранения (ВОЗ) определила, что лихорадка денге является наиболее опасным заболеванием, переносимым комарами, в мире. За последние несколько десятилетий в мире произошло 30-кратное увеличение глобальной заболеваемости лихорадкой денге. Люди, живущие в тропическом и субтропическом климате, наиболее уязвимы к лихорадке денге, а это половина населения мира, подверженная риску. Существует четыре типа серотипов (или «штаммов») вируса денге, поэтому человек может заразиться вирусом денге до четырех раз. При отсутствии специального лечения, связанного с лихорадкой денге, раннее обнаружение для предотвращения размножения комаров Aedes, являющихся переносчиками вируса, является наиболее эффективным методом сокращения вспышек денге.
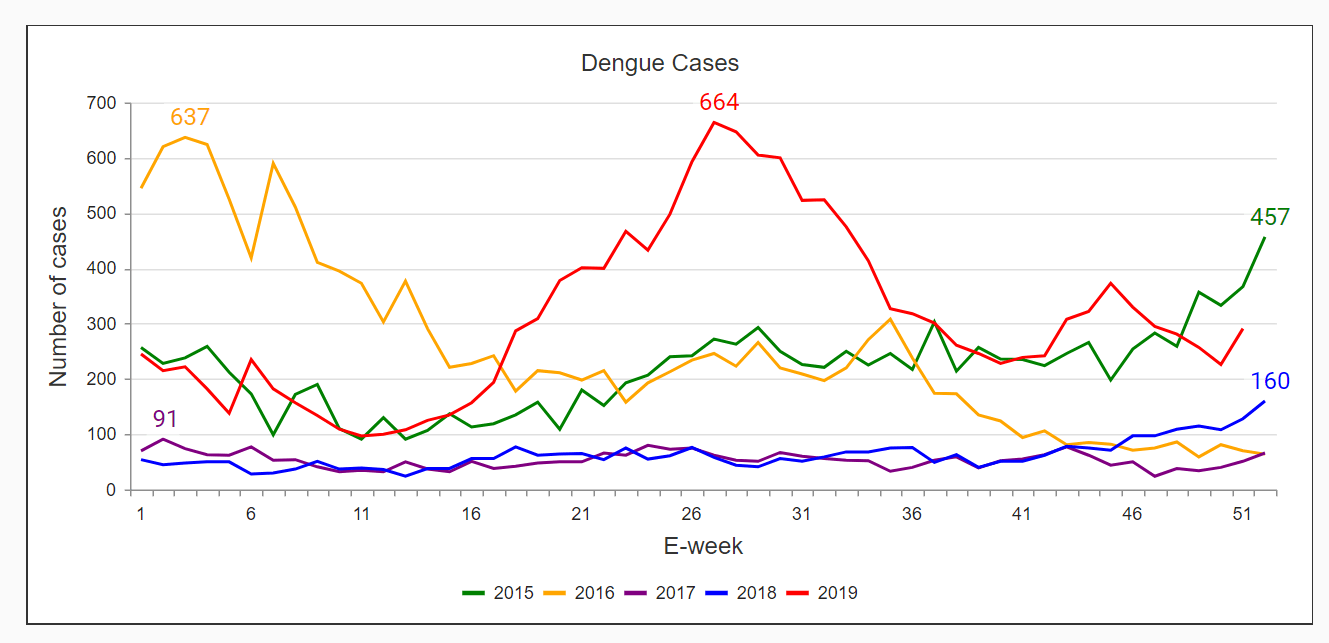
С тех пор, как эпидемия лихорадки Денге охватила Сингапур почти десять лет назад, кампания «Пятиэтапное уничтожение Моззи», запущенная Национальным агентством по охране окружающей среды (NEA), известна каждому жителю Сингапура. Действительно, о вспышках лихорадки денге и всплесках заболеваемости денге периодически сообщалось в Сингапуре, особенно с учетом нашего экваториального климата, весьма благоприятного для размножения комаров. Также проводился пассивный мониторинг стоячей воды, которая является потенциальными местами размножения этих смертоносных вредителей. Лихорадка денге привлекла внимание Сингапура и стала темой повседневных разговоров в 2005 году, когда было зарегистрировано более 14 000 случаев денге. Это привело к нехватке коек в больницах из-за большого притока больных денге. С тех пор вирус денге является постоянной общественной проблемой: в 2019 году было зарегистрировано более 16 000 случаев.
Цель
Цель нашего проекта состоит в том, чтобы предсказать количество случаев денге на основе (1) осадков и (2) измерений температуры в различных местах в Сингапуре, (3) роста населения и (4) эффектов временных рядов. Наши модели будут прогнозировать еженедельное количество случаев денге на срок до восьми недель в будущем. Мы решили, что прогнозирование недельного исхода более идеально, чем ежедневного исхода, чтобы уменьшить вариации значений исхода, поскольку нам также предоставляется количество случаев денге по неделям. Это также значительно снизит вычислительную мощность, необходимую для машинного обучения, что приведет к экономии времени. Используя деревья решений и нейронные сети, мы стремимся создать надежную модель прогнозирования, которая предсказывает предстоящее число случаев лихорадки денге на восемь недель вперед.
Наш набор данных
Мы смогли использовать значительный объем качественных данных для реализации этого проекта благодаря различным министерствам Сингапура, которые смогли собрать важные и актуальные данные. В Сингапуре все практикующие врачи и клинические лаборатории обязаны сообщать в Министерство здравоохранения (МЗ) обо всех клинически подозреваемых и лабораторно подтвержденных случаях лихорадки денге в течение 24 часов после постановки диагноза (согласно разделу 7 Закона об инфекционных заболеваниях).
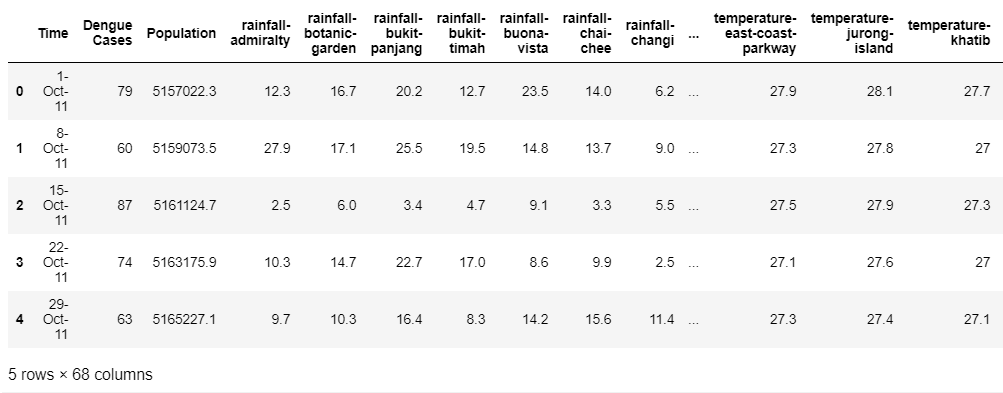
Наш полный набор данных состоит из еженедельных панельных данных с 13 августа 2011 г. по 23 ноября 2019 г. (433 недели). Мы выбрали следующие характеристики, которые будут служить важными переменными, определяющими прогноз случаев денге, — еженедельные данные об осадках (50 мест) и температуре (15 мест) в различных местах Сингапура и годовая численность населения Сингапура. Данные о населении были интерполированы на отдельные недели в течение года, чтобы облегчить их обработку вместе с другими недельными данными.
Наша зависимая переменная, которую мы хотим предсказать, — это количество случаев денге в неделю, вплоть до 8 недель в будущем.
Обоснование использования этих данных следующее:
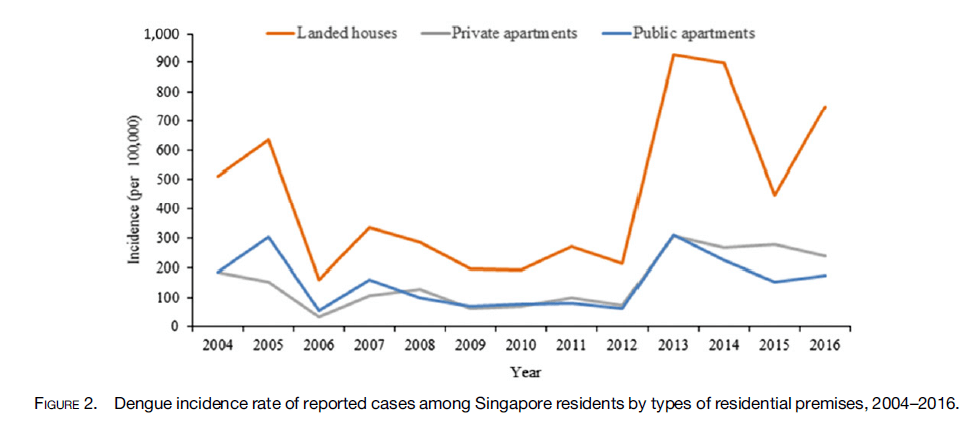
- Данные о погоде (например, количество осадков и температура): это факторы, влияющие на размножение Aedes aegypti и Aedes albopictus комаров и, следовательно, связаны с риском заражения лихорадкой денге. Высокие температуры создают благоприятную и благоприятную среду для размножения комаров, а также приводят к их более агрессивному поведению при кормлении. И наоборот, обильные осадки приводят к более высокой вероятности скопления стоячей воды, которую можно было бы не контролировать, например, на крышах частных жилых домов, что создает идеальные условия для размножения комаров.
- Мы также включили демографическую тенденцию Сингапура, чтобы выяснить, приводят ли изменения в численности населения к значительным изменениям числа случаев лихорадки денге с годами. Мы надеемся, что сможем объяснить часть увеличения числа случаев денге за эти годы из-за увеличения населения.
Методология предварительной обработки данных
Работа с высококоррелированными данными
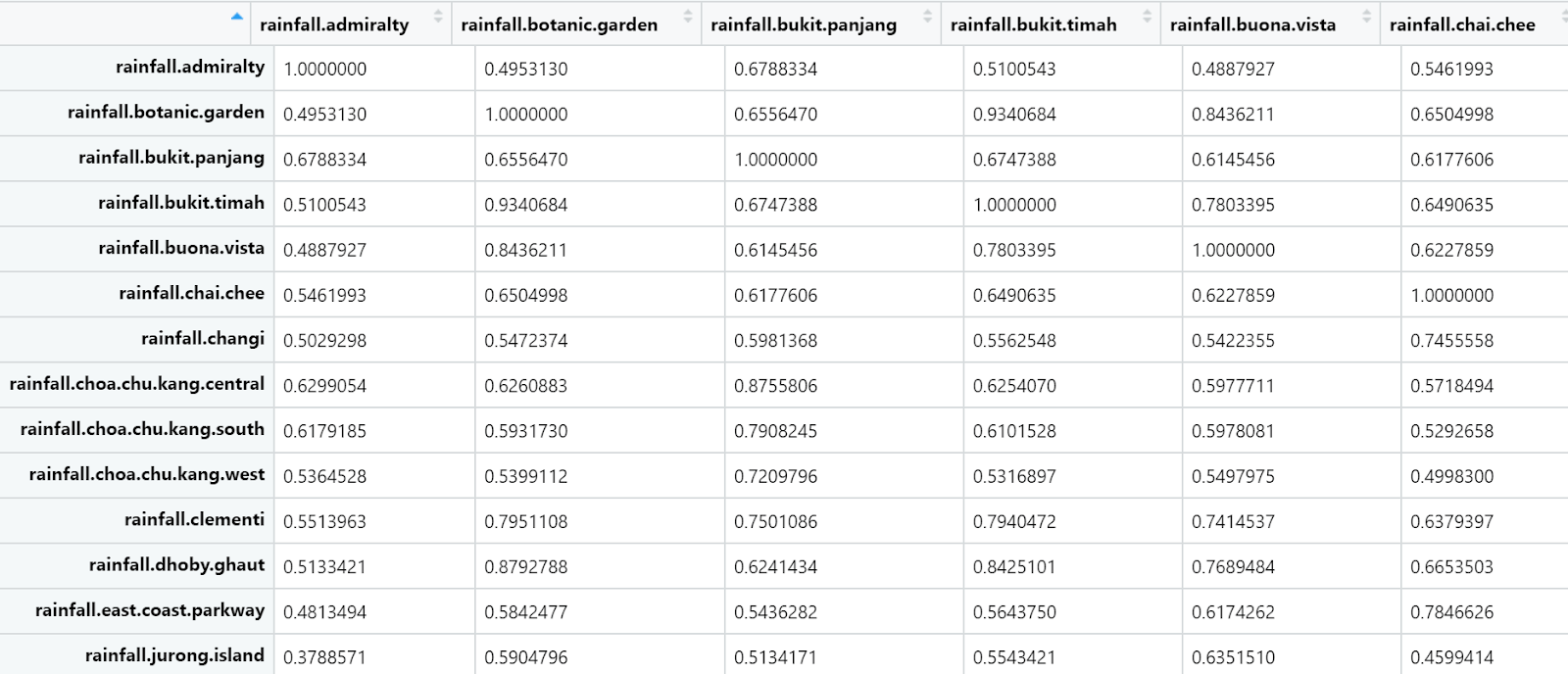
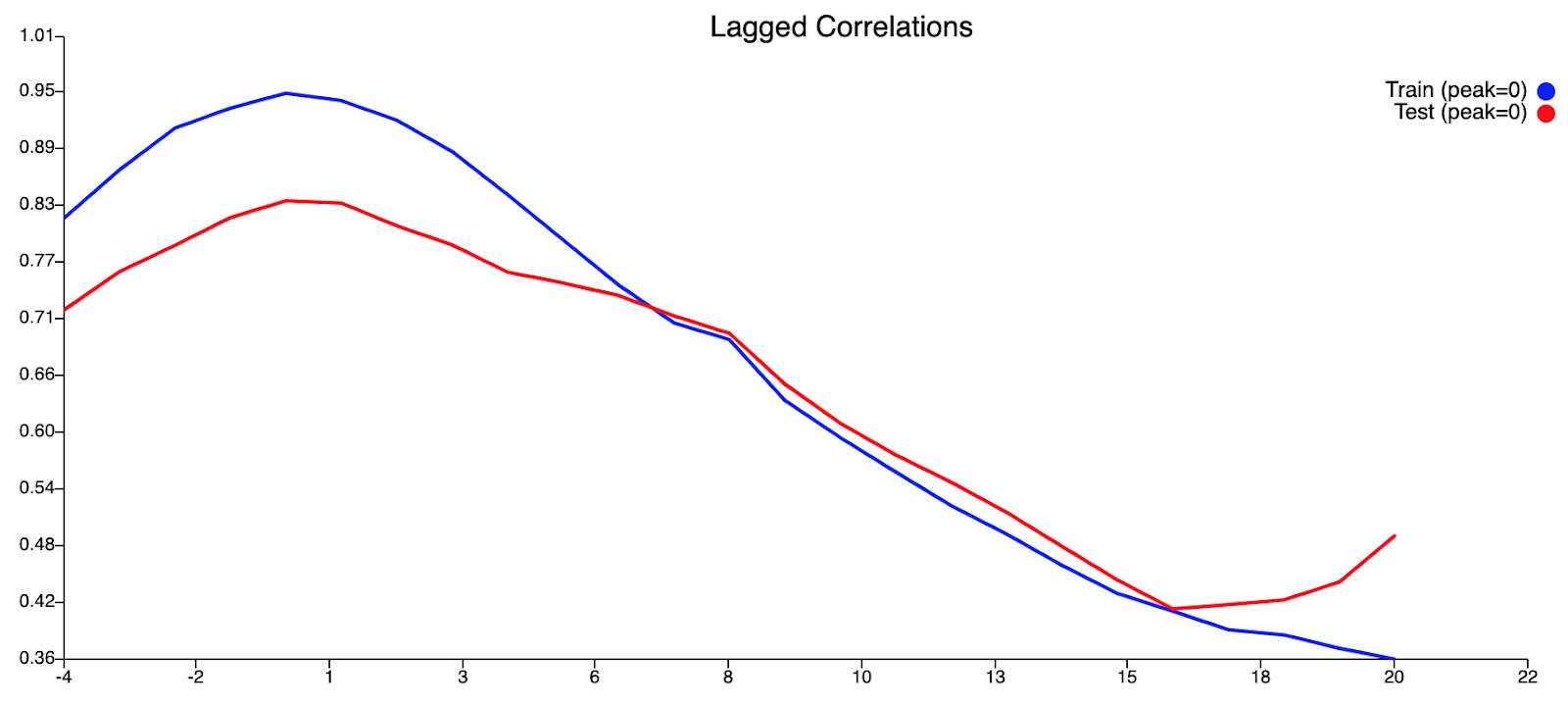
Глядя на графики корреляции на Рисунке 4 выше, мы заметили, что многие станции осадков и температуры сильно коррелируют друг с другом. Это имеет смысл, учитывая, что небольшая площадь суши Сингапура должна сделать большую часть острова атмосферно однородной. Основываясь на географическом местоположении, результаты корреляции логичны и ожидаемы, учитывая, что в таких местах, как Доби-Гаут и Сомерсет (оба расположены в южной части Сингапура), наблюдаются очень похожие тенденции количества осадков. Стоит отметить, что в исходном наборе данных (который датируется 2000 годом) была значительная часть отсутствующих данных об осадках или температуре. Вот почему мы сузили диапазон данных, которые мы используем, до восьми лет. Затем мы заменили отсутствующие значения осадков или температуры на основе метода корреляции в пределах этого 8-летнего диапазона.
Извлечение признаков для создания кластеров дендрограммы
Ввиду высокой корреляции между характеристиками температуры и осадков, соответственно, мы хотим уменьшить количество характеристик температуры и осадков. Однако мы по-прежнему хотим сохранить способность нашей модели объяснять изменчивость случаев денге. Таким образом, мы провели уменьшение размерности за счет извлечения признаков, чтобы обработать сильно коррелированные признаки и предотвратить переоснащение.
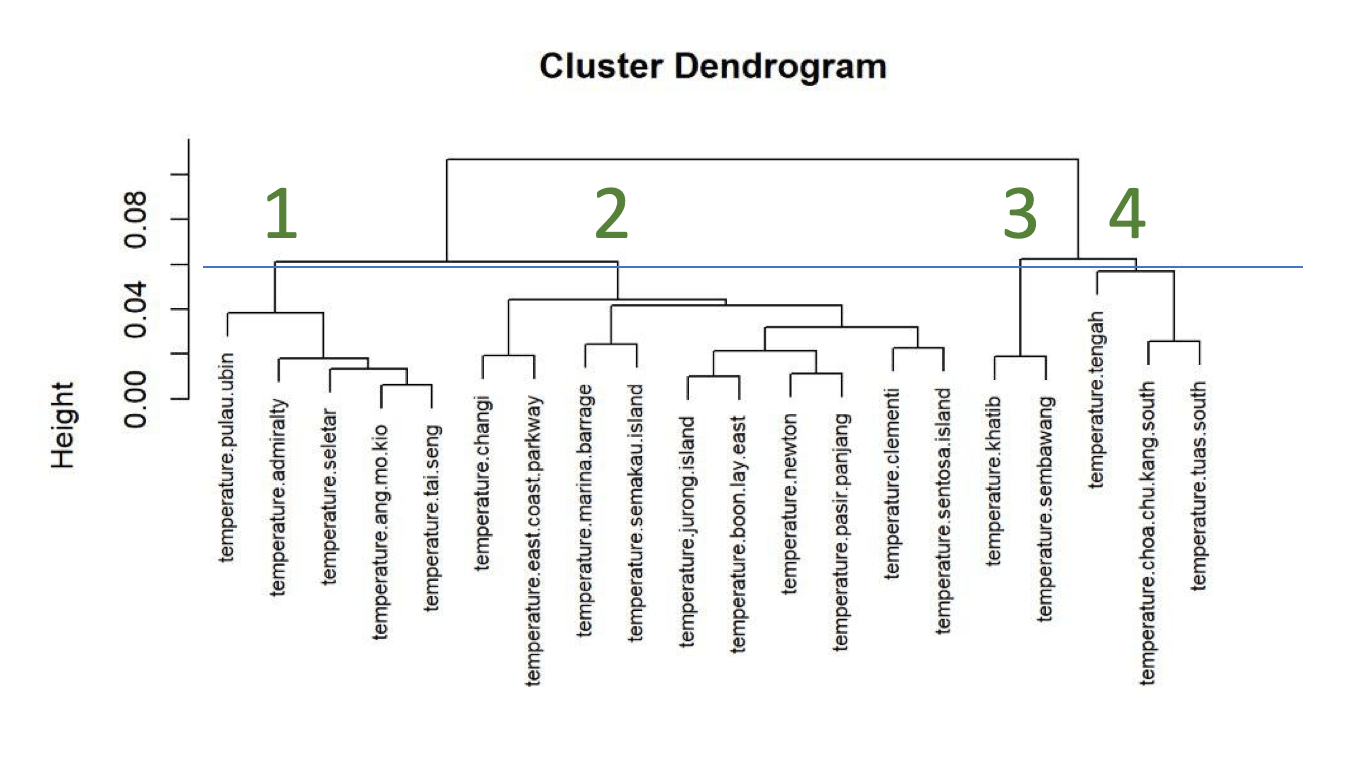
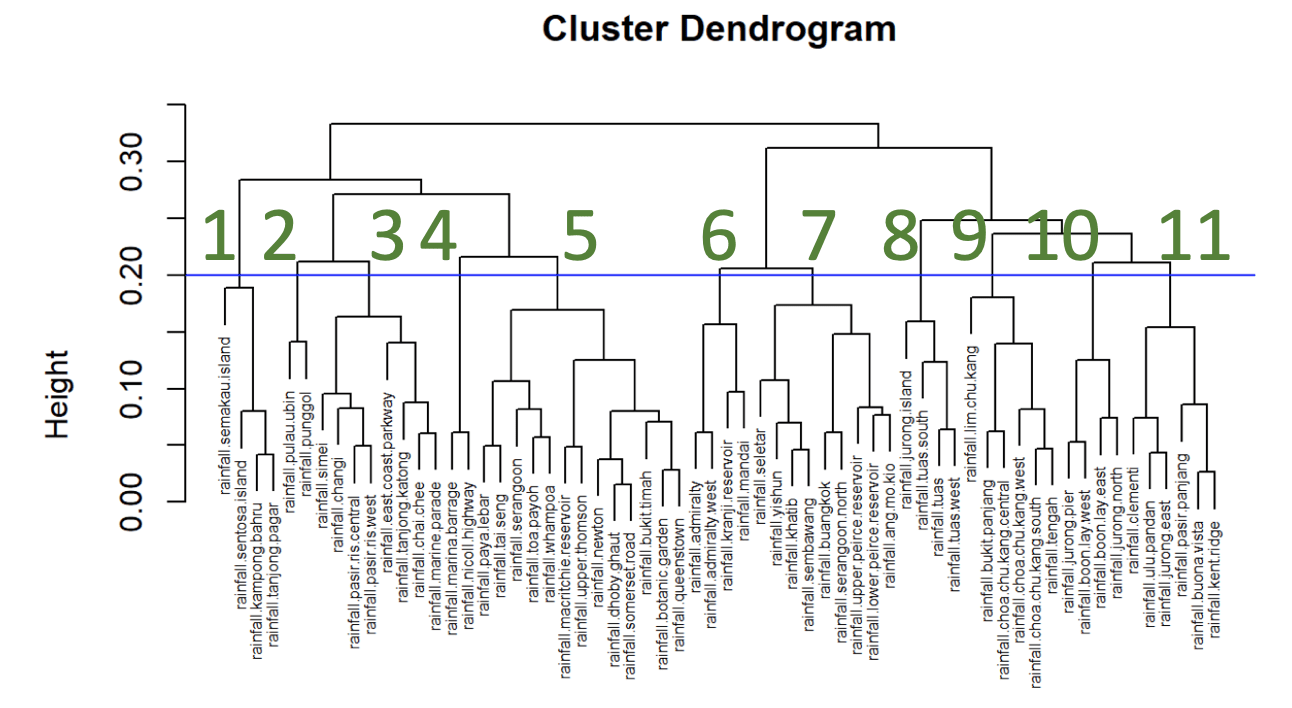
Мы построили две дендрограммы, по одной для недельных осадков и температуры. Дендрограммы были основаны на расстоянии парной корреляции (1 минус корреляция) между двумя местоположениями. На основе результатов мы получили 11 кластеров осадков и 4 кластера температуры, чтобы представить тренды осадков и температуры в различных частях Сингапура.
Что делать с отсутствующими данными
В наборе данных были патчи с отсутствующими данными. Для некоторых метеостанций в наборе данных отсутствуют данные о длительных периодах осадков и температуре. Учитывая локальный характер осадков, мы приблизительно оценили уровни осадков, используя значения осадков на ближайших метеорологических станциях (в пределах одного кластера). Мы полагали, что это приведет к более точному представлению тренда количества осадков/температуры по сравнению с заменой отсутствующих значений другими статистическими данными, такими как среднее количество осадков за 8 лет на соответствующих станциях осадков.
Функция Нормализация количества осадков, температуры и других значений
Чтобы определить недельную температуру или количество осадков или каждый из 11 кластеров осадков и 4 кластеров температуры, мы взяли среднее значение всех значений температуры или осадков в каждом кластере. Это усреднение выполняется для данных за каждую неделю по всем станциям в кластере, в результате чего каждую неделю получаются средние кластерные значения как для температуры, так и для количества осадков. Чтобы проиллюстрировать это, температуры на метеорологических станциях Хатиб и Сембаванг образуют кластер 3. Таким образом, недельные температуры кластера 3 будут средними недельными температурами этих двух станций.
Затем мы разделили наш набор данных на обучающий набор (с 13 августа 2011 г. по 17 марта 2018 г.) и тестовый набор (с 24 марта 2018 г. по 23 ноября 2019 г.). Затем мы нормализовали значения в каждом кластере температуры или количества осадков в обучающей выборке. Медиана и диапазон, используемые для нормализации обучающей выборки, также использовались для нормализации значений тестовой выборки. Используемая формула приведена ниже.
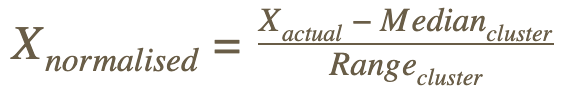
Мы нормализовали значения кластера, чтобы минимизировать величину используемых значений, что ускорит обучение нейронной сети, а также предотвратит любые ошибки при запуске нейронной сети из-за больших чисел.
Выбор функций
Для предварительного отбора признаков мы использовали деревья регрессии с использованием алгоритма XGBoost. Мы начали наш выбор функций с начального набора переменных, состоящего из:
- уровни лихорадки денге в Т+8 (т.е. через восемь недель в будущем)
- уровни лихорадки денге на момент T+0 (т. е. когда неделя = 0)
- максимальные и средние значения каждого кластера осадков от периодов T-3 (т.е. три недели назад) до T+0
- минимальные значения каждого температурного кластера от периодов Т-12 до Т-4
Идея использования среднего значения каждого кластера осадков от периодов T-3 до T+0 заключается в том, что количество осадков за эти три недели может предсказать вспышку денге через восемь недель. Этот диапазон (от T-3 до T+0) был выбран с учетом жизненного цикла комаров Aedes и времени инкубации вируса денге (количество времени, которое требуется вирусу, чтобы вызвать симптомы у люди). После контакта с водой яйцам комаров требуется около трех недель, чтобы вырасти во взрослую особь, что приводит к появлению симптомов у зараженного человека. Важно отметить, что этот первоначальный всплеск популяции Aedes может привести к экспоненциальному увеличению количества яиц, откладываемых в течение восьминедельного окна прогноза, и будет полезен для прогнозирования всплеска случаев денге.
Что касается температурных кластеров, были выбраны минимальные значения каждого температурного кластера от периодов Т-12 до Т-4, поскольку мы предположили, что самые низкие температуры за последние 12 недель могут предвосхитить период более высоких температур через восемь недель. Это также связано с тем, что вспышки традиционно происходят в период с июня по октябрь, при этом июнь обычно является самым жарким месяцем в году. Мы хотим предвидеть повышение температуры, потому что это приводит к сокращению времени репликации вируса внутри комаров, т. е. сокращает время, в течение которого комары становятся заразными для людей. Это еще больше усугубляется более агрессивным пищевым поведением комаров, что увеличивает вероятность заражения человека инфицированным комаром. Таким образом, более высокие температуры в период вспышки являются важным предиктором. Нам бы очень хотелось заглянуть в прошлое (например, Т-15), но мы не могли этого сделать из-за серьезной нехватки тестовых данных.
Построение модели
Первоначальные результаты с использованием деревьев регрессии
Сначала мы запустили оптимизацию параметров дерева регрессии на начальном наборе переменных. Мы использовали дерево регрессии для извлечения признаков просто потому, что оно быстрое. Наиболее подходящие для наших данных параметры указаны ниже. Используя эти оптимизированные значения, мы затем начали сокращать количество кластеров, чтобы свести к минимуму проклятие размерности, когда мы перейдем к использованию нейронных сетей. Редукция кластеров выполнялась следующим образом:
- Используйте первоначальные результаты (с использованием всех кластеров температуры и осадков) в качестве эталона. Результаты, на которые следует обратить внимание, — это среднеквадратическая ошибка (MSE), прогнозы обучения, прогнозы тестов и запаздывающие корреляции.
- Удалите переменные, принадлежащие наименьшему кластеру осадков, который расположен на крайних концах Сингапура, например. Кластер 1 и 2.
- Посмотрите на бенчмарки для сравнения. Если они работают одинаково или модель работает лучше без удаленной переменной, они удаляются из последующих моделей для тестирования. Это делается для того, чтобы создать модель как можно меньшего размера. Если результаты хуже предыдущих, то этот кластер снова добавляется в модель.
- В случае незавершенного прогона (т. е. линия проигрыша в тесте не пересекала линию проигрыша в тренировке) количество раундов увеличивалось.
- Это выполнялось итеративно, и тот же метод использовался для выбора полезных температурных кластеров.
- Любые варианты окончательного набора переменных были добавлены в модель для тестирования. Как и раньше, если результаты были эквивалентны или хуже результатов предыдущей тестируемой модели, переменная удалялась.
Наилучшие параметры для дерева регрессии, основанные на нашем исходном наборе переменных, следующие: [количество раундов = 20; максимальная глубина деревьев = 1250; скорость обучения = 0,1; количество параллельных деревьев = 10; подвыборка = 0,1, выборка столбцов по деревьям = 1]. Затем мы обнаружили, что наши лучшие параметры:
Средние уровни денге от T-4 до T-1, от T-8 до T-5 и от T-9 до T-12
Средние дифференцированные значения денге от T-4 до T-1 и T-9 до T-12
Уровни населения при T+0
Максимальные и средние значения от T-3 до T+0 кластера осадков 2, 4, 5, 6, 7, 8, 9 10 и 11< br /> Средние и минимальные значения от T-7 до T-4 и от T-12 до T-8 для температурных кластеров 2, 3 и 4
Результаты нашей модели дерева регрессии (с квадратом ошибки 0,12095)приведены ниже:
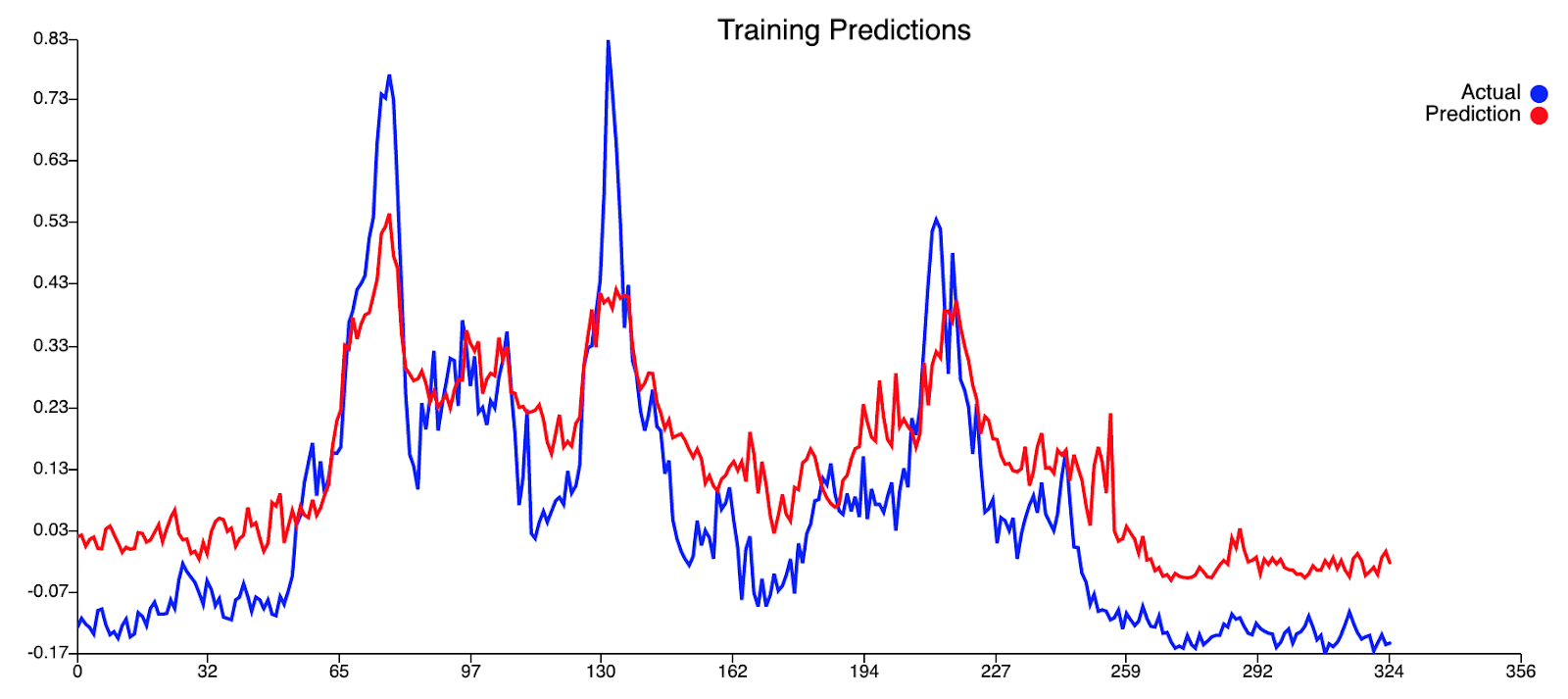
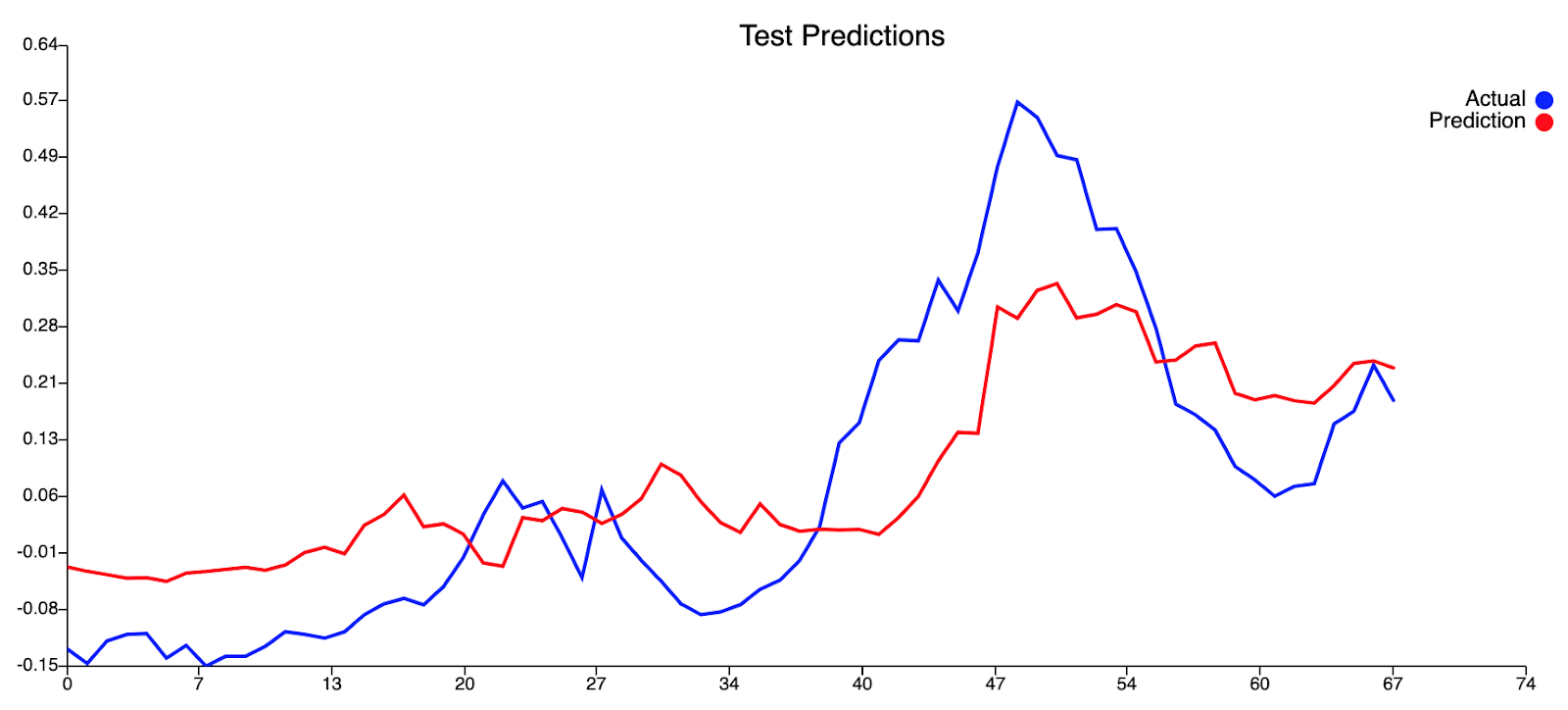
Построение модели глубокого обучения
Метрики, используемые для модели глубокого обучения, аналогичны метрикам, используемым в модели дерева регрессии. На этом этапе было бы полезно упомянуть, что мы решили обойтись без проверочного набора из-за небольшого количества точек данных в нашем наборе данных. Вместо этого мы будем полагаться исключительно на евклидовы потери, а также на график тестового прогноза, чтобы определить, хорошо ли работает наша модель. Кроме того, когда мы смотрели на уровни лихорадки денге в 2017–2018 годах, они были в основном ровными. Таким образом, мы подумали, что даже если мы сделаем набор для проверки, он будет включать в себя большинство этих значений. Это может дать нам ложное представление о том, насколько хорошо работает наша модель, поскольку уровни лихорадки денге в 2019 году начали колебаться и даже достигли своего пика. Важно отметить, что мы могли оптимизировать модель, чтобы она соответствовала проверочному набору, у которого нет пика (соответствующего вспышке). С учетом времени мы решили просто использовать евклидовы потери и тестовое предсказание. Конечно, мы учли и отставание.
Ориентиром производительности нашей модели является потеря устойчивости, которая в нашем тестовом наборе данных была рассчитана как 0,015698. Оценка была рассчитана с использованием значений денге тестового набора. Это был один столбец в нашем Excel, который служит нашими значениями T+0. В соседний столбец мы скопировали и вставили значения денге, начиная с T+8. Этот столбец служит нашими значениями T+8. Выступающие концы столбцов T+0 и T+8 были усечены. После чего мы вычислили квадрат разницы двух столбцов в новом столбце. В отдельной ячейке мы усреднили сумму всех квадратов различий и разделили это среднее значение на два, чтобы получить постоянство потерь.
Методология глубокого обучения
Затем мы переключили наше внимание на нейронные сети с окончательным набором функций, полученных на этапе дерева регрессии. Возможно, способность нейронных сетей хорошо обобщать более сложные закономерности позволила бы нам делать более точные прогнозы.
Мы провели начальный тест на простой трехслойной нейронной сети всего с тремя конфигурациями: 16, 32 или 64 узла. Это было с учетом времени. Мы выполнили 10 000 итераций для каждой конфигурации с помощью оптимизатора Adam. Весь процесс был повторен 5 раз, чтобы гарантировать, что начальные веса не привели к чрезмерно предвзятым или чрезмерно оптимальным результатам. Нашей тренировочной меткой были уровни лихорадки денге на уровне T+8.
Лучшими результатами стали:
Потери при тестировании: 0,0060406
Количество входных данных: 36
Итераций: 10000
Алгоритм оптимизации: Адам
Количество персептронов в самом верхнем слое: 128
Количество слоев в нейронной сети: 3
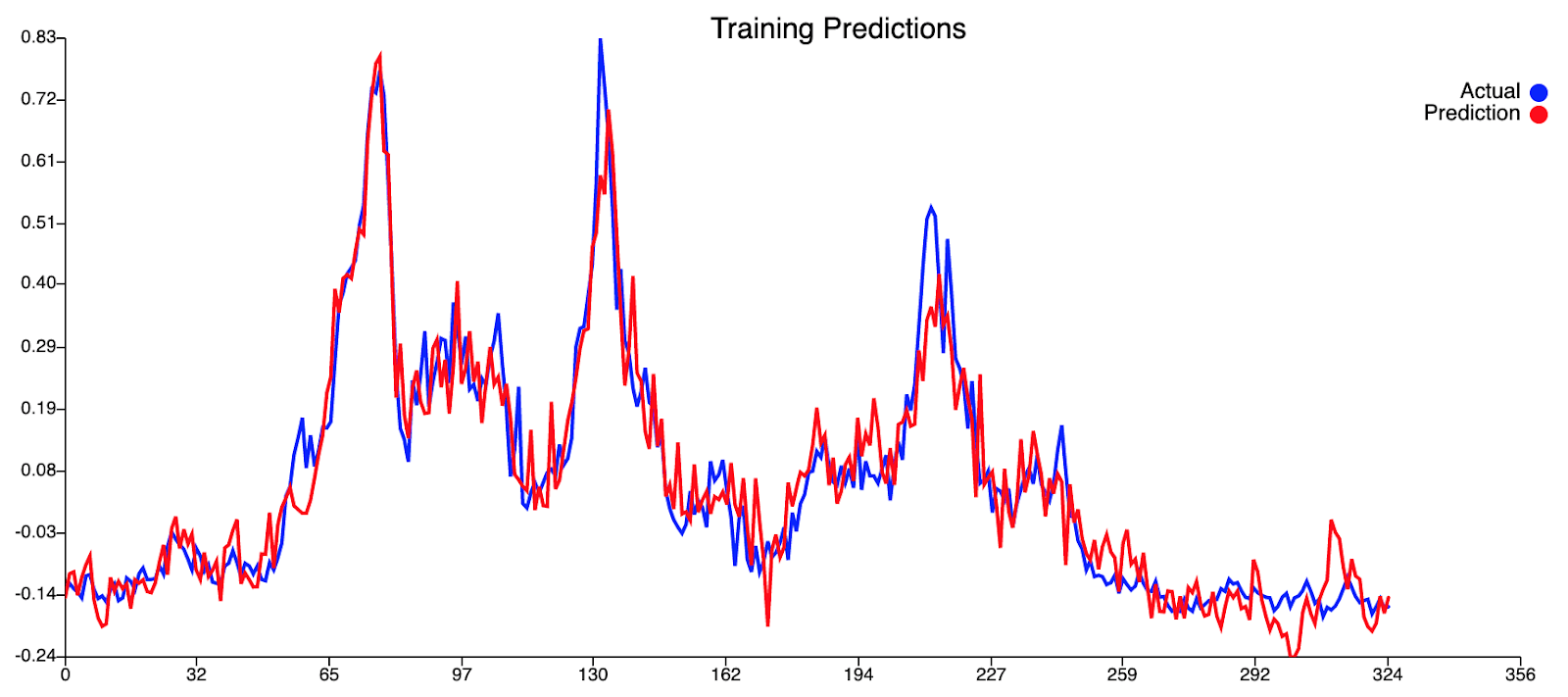
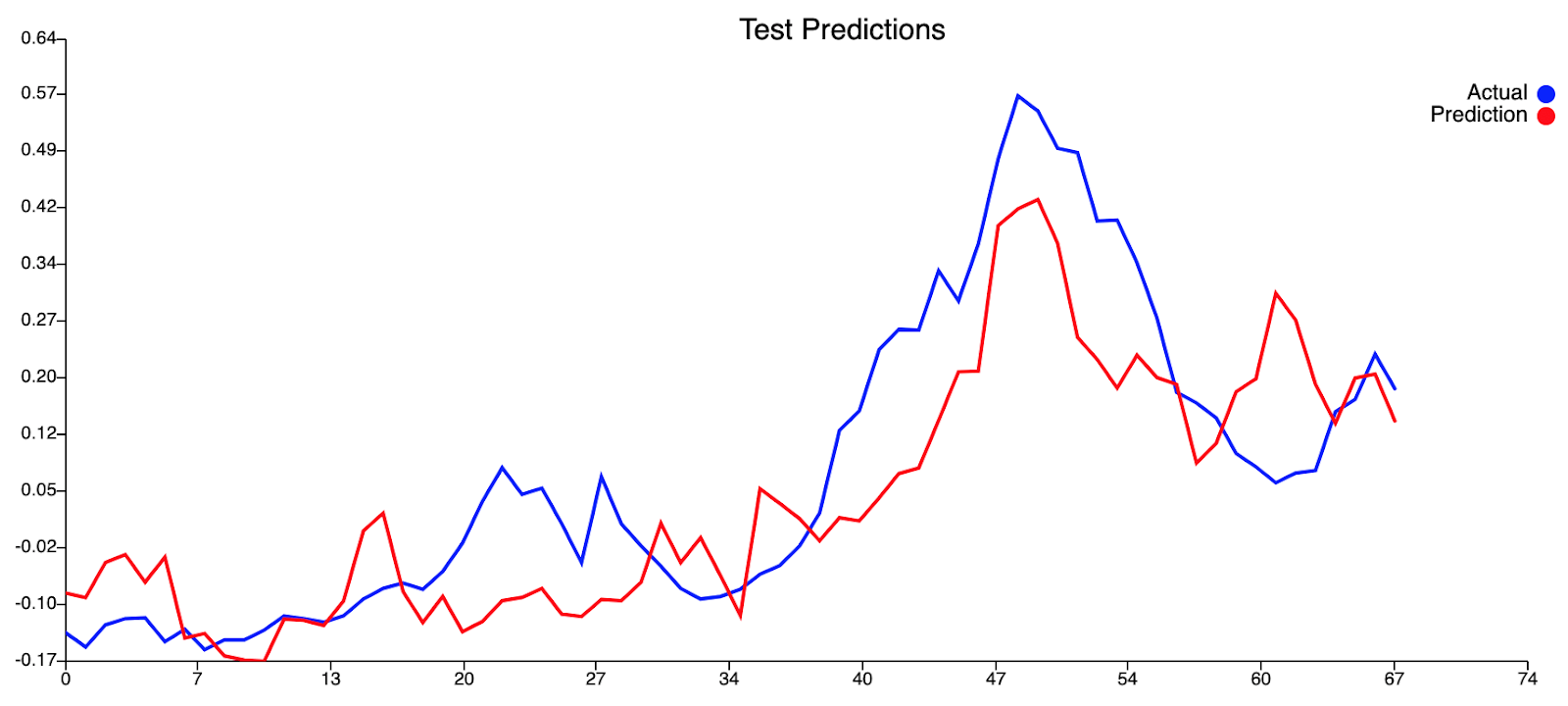
Результаты были неплохими, но мы хотели большего. Кроме того, был второй всплеск в прогнозах, который произошел сразу после реального всплеска, который был ложным всплеском уровней денге. Мы хотели бы удалить или свести к минимуму этот ложный всплеск, насколько это возможно.
Во время нашего второго раунда оптимизации нейронных сетей мы экспериментировали с более крупными нейронными сетями, которые имели 3, 4 или 5 слоев. Оттуда мы также обнаружили, что еще один параметр значительно улучшил наши результаты, а именно второй дифференциальный порядок уровней лихорадки денге от T-4 до T-1. Таким образом, наш окончательный набор параметров:
Средние значения T-4 до T-1, T-8 до T-5 и T-9 до T-12 уровней денге
Средние дифференцированные значения уровней денге первого порядка от T-4 до T- 1 и от T-9 до T-12
Средние дифференцированные значения второго порядка уровней лихорадки денге от T-4 до T-1
Уровни популяции при T+0
Максимальные и средние значения T от -3 до T+0 для групп осадков 2, 4, 5, 6, 7, 8, 9, 10 и 11
Максимальные и средние значения от T-7 до T-4 и от T-12 до T-8 для температурных кластеров 2, 3 и 4
Мы также сравнили эти результаты с результатами использования более крупных нейронных сетей из 6, 7 и 8 слоев. Размеры узлов, протестированные в более крупных нейронных сетях, были одинаковыми, то есть 32, 64 и 128. Мы также пытались использовать оптимизатор SGD вместо оптимизатора Adam. Тем не менее, более простые нейронные сети и оптимизатор Адама по-прежнему работали лучше всего. Мы провели наш окончательный анализ с 20 повторениями, чтобы получить наилучшие результаты, как показано ниже:
Потери при тестировании:0,00453716
Количество слоев в нейронной сети: 4
Количество персептронов в самом верхнем слое: 64
Количество входов: 37
> Итерации: 10 000
Алгоритм оптимизации: Адам
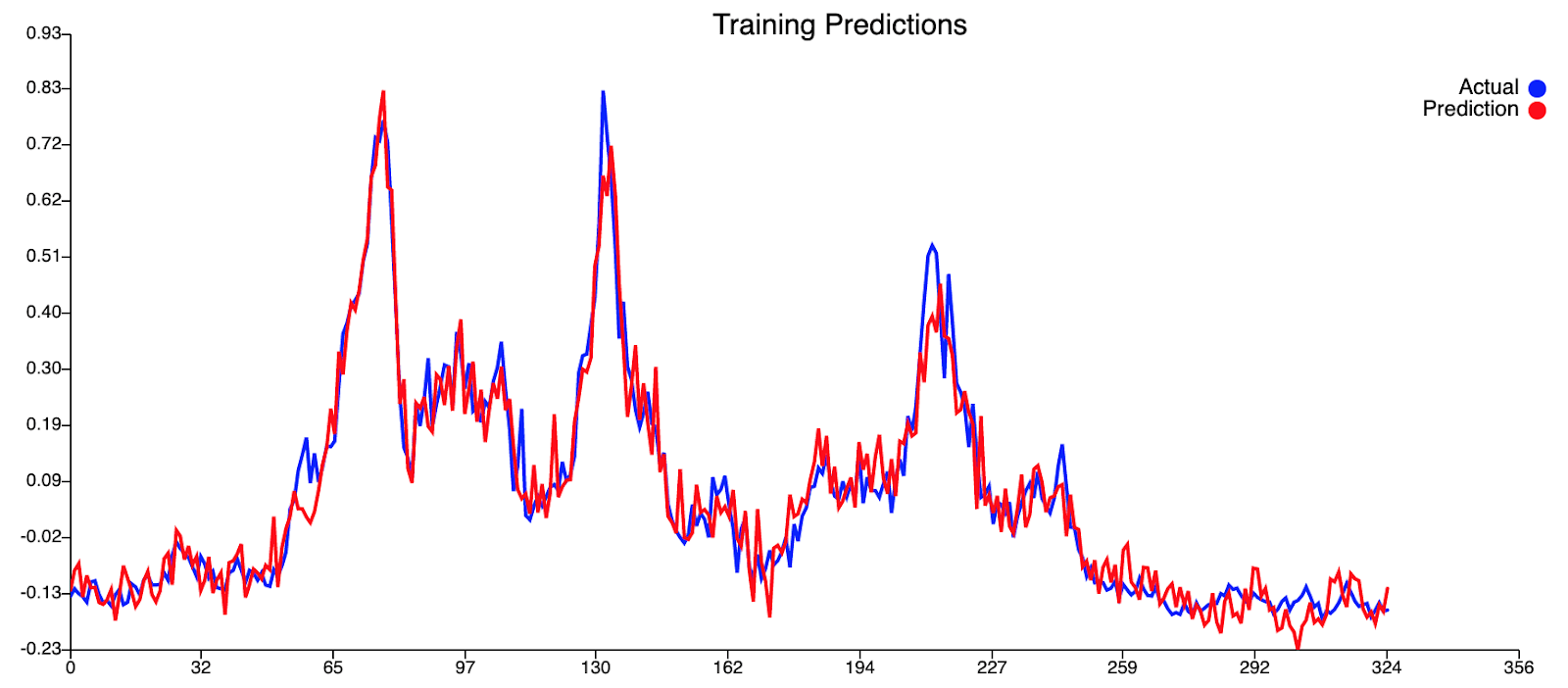
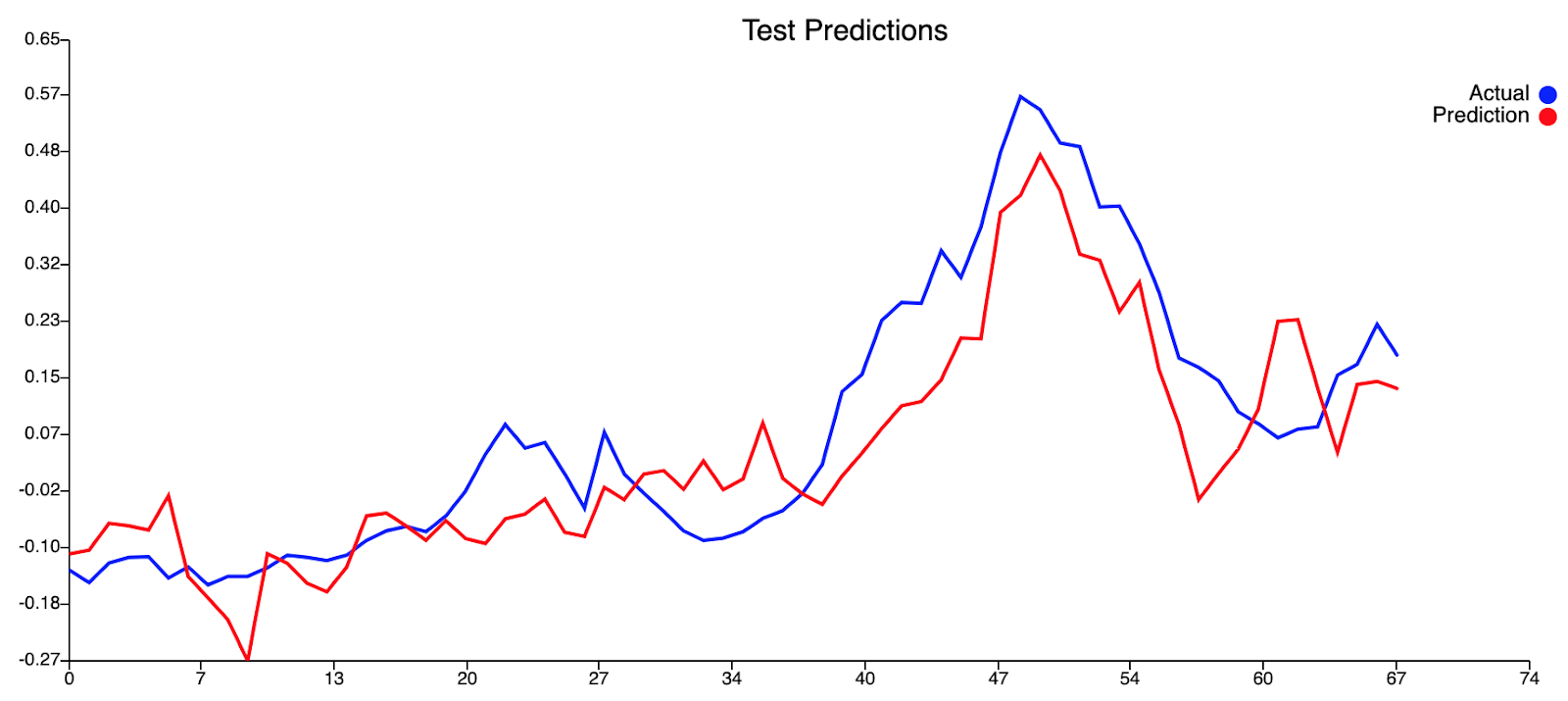
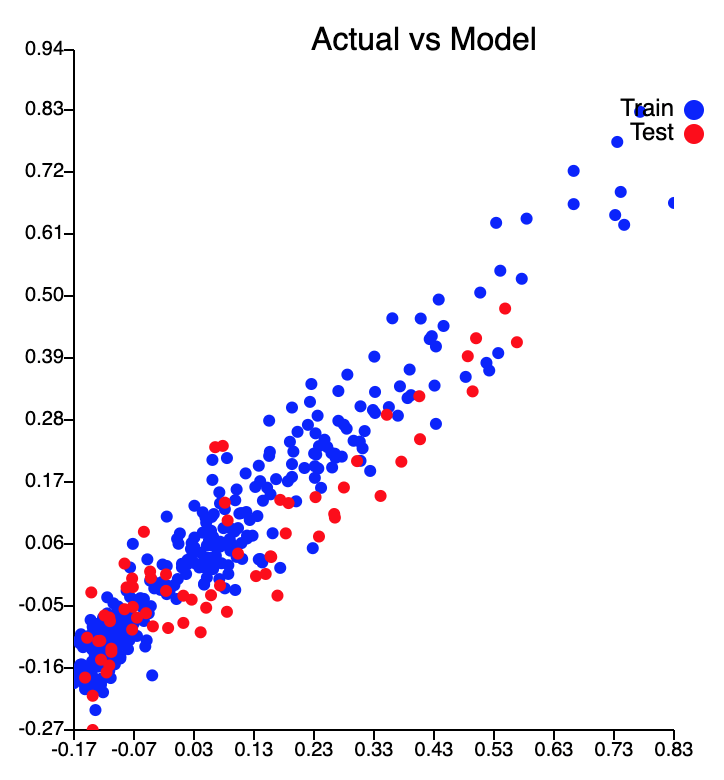
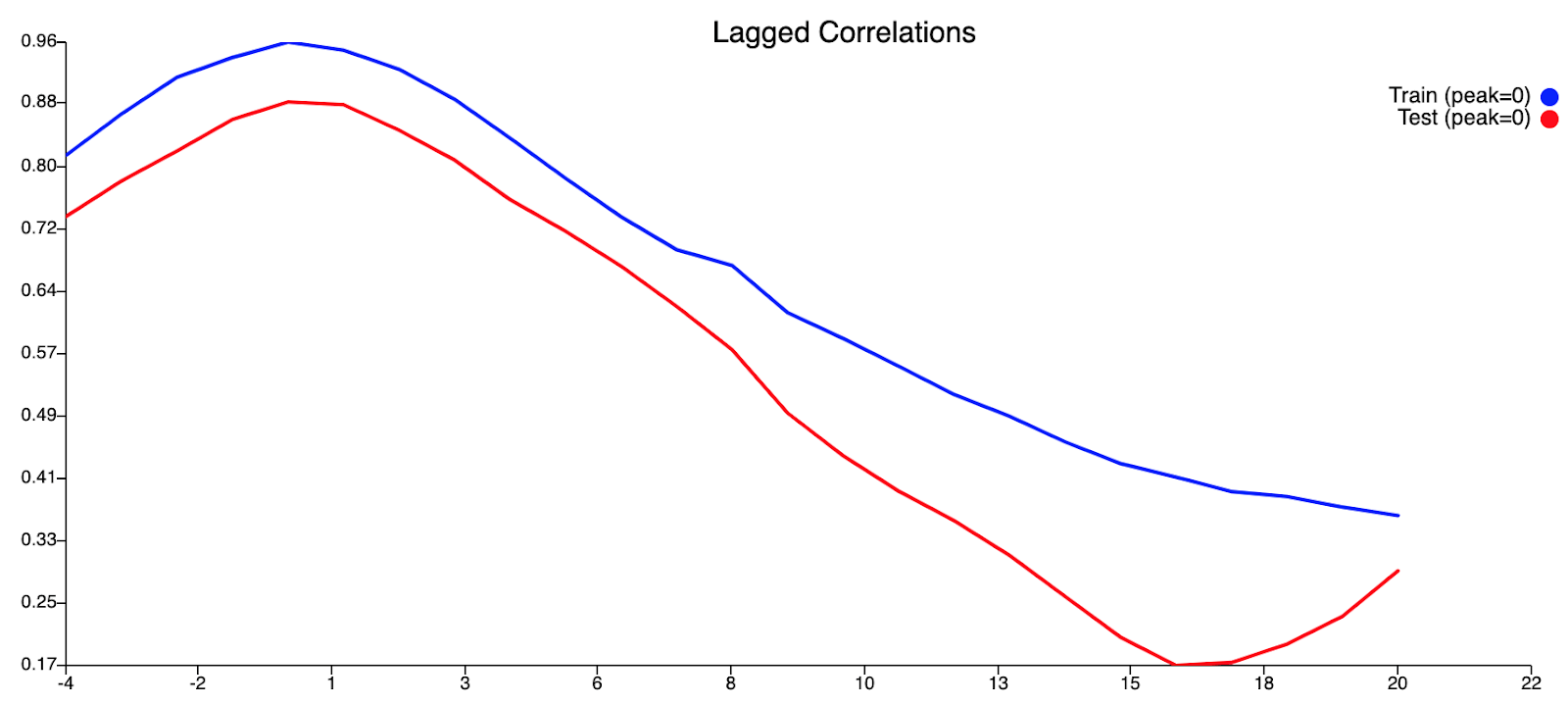
Достигнув оценки потери 0,00453716, наша модель превосходит устойчивость примерно на 0,01, что составляет треть потери устойчивости.
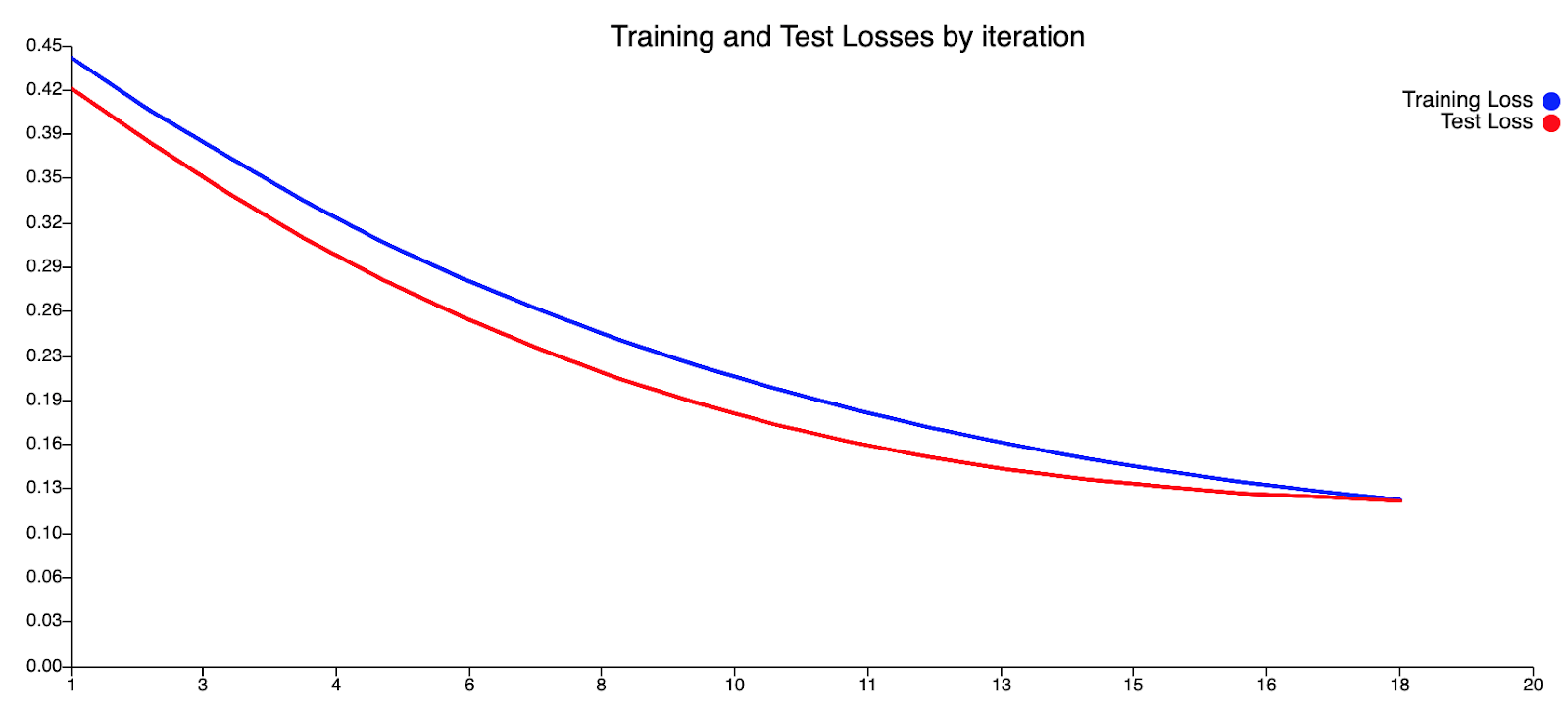
Из нашей кривой прогнозирования обучения кажется, что наш текущий набор переменных не позволяет модели оценивать пики, присутствующие в этом наборе данных. Это видно по тому, что обучение, по-видимому, происходит достаточно хорошо при более низких уровнях денге, но наша модель всегда не позволяет прогнозировать более высокие уровни денге, когда фактические уровни денге достигают пика. Это говорит о недостатке информации в нашей модели. Что касается кривой предсказания тестов, то кривая на самом деле очень хорошо подходит. Прогнозируемые значения не слишком далеки от фактических значений для низких уровней денге, а пик случаев денге был обоснованно предсказан с отставанием в 0 (что потрясающе!). Хотя наш прогноз не смог предсказать больше случаев денге, чем фактические значения случаев денге, что было бы благоприятным, он, тем не менее, смог предсказать пик случаев денге. Следует также учитывать второй меньший пик, следующий за первоначальным пиком. Мы считаем, что мог быть второй пик, но этого не произошло из-за большего вмешательства, проведенного АЯЭ в этот период, т.е. повышенное запотевание, хотя это всего лишь теория.
Потенциальные риски использования нашей модели
Если есть оговорка в отношении результатов нашей модели, мы считаем, что наша модель не совсем способна к завышенным прогнозам (чего мы и хотели добиться). Организация, использующая эту модель, должна по своему усмотрению уведомить соответствующие медицинские работники об этой тенденции и предложить им предвидеть больше случаев. Кроме того, поскольку прогноз пиковых значений денге в тестовой выборке был ниже, чем фактические значения денге, мы не можем быть уверены, сможет ли наша модель точно предсказать уровни денге в случае очень сильной вспышки. Возможно, существует пороговое значение случаев денге, которое может предсказать наша модель, но нам нужно больше данных, чтобы определить, существует ли такое пороговое значение.
Кроме того, учитывая, что эта модель была разработана на основе данных из Сингапура, было бы благоразумно доверять ее точности при использовании в районах со сходными с Сингапуром характеристиками. Некоторые характеристики, которые следует учитывать, включают: площадь Сингапура (751,2 км²), которая неизбежно влияет на режимы осадков и температуры, плотность населения, а также на пространственно-временные модели движения.
Заключение и обзор
В целом, мы думаем, что справились довольно хорошо, и было совсем не просто попасть в золотую середину с низким результатом теста, приемлемым шаблоном прогнозирования и приемлемым шаблоном отставания. Хорошие оценки модели также были достигнуты за счет использования различных вариаций четырех переменных: уровней денге, численности населения Сингапура, температуры и количества осадков.
Найти соответствующие переменные без негативного изменения результатов было непросто. Мы попытались включить тренды поиска Google в отношении «денге», чтобы посмотреть, будет ли это важным предиктором, но результаты были неоднозначными. Кроме того, корреляция и причинно-следственная связь между тенденциями поиска в Google и самой вспышкой не были широко изучены, поэтому в конце концов мы решили отказаться от этого.
Мы также считаем, что эту модель можно улучшить, еще больше настроив компоненты модели, включив больше переменных (что мы не смогли сделать из-за ограниченности данных, доступных в Интернете). Дополнительные эксперименты с вариациями архитектуры нейронной сети, а также предоставление на этапе обучения большего количества данных также могут быть полезны для улучшения модели.
Тем не менее, мы разработали модель нейронной сети, которая способна довольно точно прогнозировать уровни лихорадки денге. Двигаясь вперед, мы считаем, что более качественные модели прогнозирования лихорадки денге могут быть созданы с использованием более качественных данных, например. серотипы лихорадки денге, уровни популяции Aedes и т. д., которые могут помочь объяснить различия в уровнях лихорадки денге. Дополнительные данные потенциально могут улучшить нашу модель и текущий набор переменных, которые мы предлагаем использовать для прогнозирования вспышек денге.
Сценарий: Бенита, Кларенс, Ричард, Вэнь Хао, Цзы Ю