Практическое руководство по пониманию одной из важнейших концепций статистики.

Центральная предельная теорема (сокращенно CLT) - одно из важнейших понятий в области статистики.
В этом посте я попытаюсь объяснить эту концепцию простым и нетехническим образом.
Введение
Давайте продолжим с нашего примера средней школы, как обсуждалось в этом сообщении здесь.
Теперь вы решили еще раз изучить эти данные.
Затем вы хотите узнать, каков будет средний рост всех учеников средней школы мужского пола, обучающихся в 10-м классе в США.
Но чтобы получить это точно, вам нужно будет определить рост каждого ученика 10 класса, а затем разделить это значение на общее количество учеников, что практически невозможно.
И здесь нам на помощь приходит Центральная предельная теорема.
Центральная предельная теорема утверждает, что среднее из ваших достаточных выборочных средних будет примерно равно среднему значению генеральной совокупности.
Это означает, что мы можем найти средний рост населения из базовых выборок данных.
Посмотрим как.
Методология

Выберите одну выборку (выборка 1) из приличного размера выборки, примерно 30 студентов из общей популяции, соберите их рост, затем запишите их среднее значение выборки, это также известно как x̄1.

Выберите еще одну выборку (образец 2) из еще 30 студентов, запишите среднее значение x̄2 (среднее значение выборки 2).
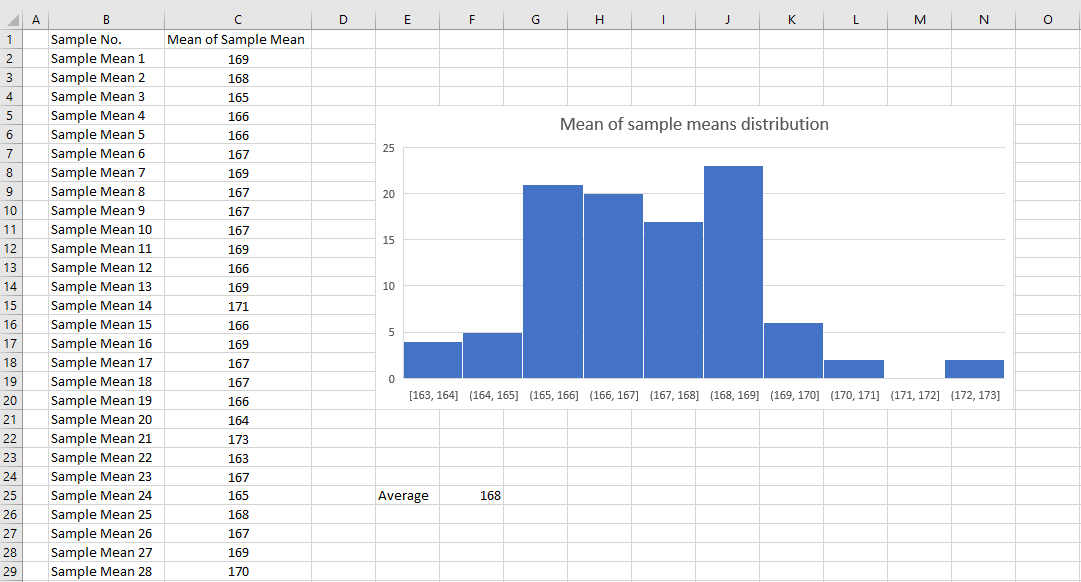
Проделайте это упражнение примерно со 100 образцами, нанесите значения (x̄1, x̄2 .. x̄100) на график и найдите среднее значение этих значений.
По мере увеличения количества выборок приведенный выше график начнет больше походить на нормальное распределение (где данные симметричны относительно среднего, а данные, близкие к среднему, встречаются чаще, чем данные, далекие от среднего)
Среднее значение выборки будет примерно равно среднему значению генеральной совокупности.
Кроме того, это произойдет независимо от распределения данных исходной совокупности (которое может быть нормальным / искаженным / однородным или любым другим распределением).
Сила этой концепции в том, что мы можем даже расширить нашу исходную проблему до гораздо более широкого контекста.
Например. выяснить, какой средний рост будет у учеников 10 класса в разных странах.
Здесь нам нужно будет включить образцы из каждой страны и включить большее количество образцов.
Обратите внимание, что здесь первоначальное распределение населения могло быть искажено, поскольку в некоторых странах было относительно более высокое распределение более высоких студентов.
И если мы построим все точки данных выборки на графике, это будет выглядеть как нормальное распределение.
Практическое применение
Теперь мы знаем, что независимо от того, как распределены точки данных о населении, график выборочных средних всегда будет выглядеть как нормальное распределение.
Для нормального распределения мы знаем, что
- Среднее значение, медиана и мода равны
- Данные симметричны относительно среднего
Используя эти свойства, мы можем сделать выводы о населении в целом.
У этого есть много практических приложений в реальном мире. например, прогнозирование того, какая партия получит большинство на выборах, для расчета ежемесячных долгов семей, проживающих в разных регионах.