Графическое обучение и геометрическое глубокое обучение - Часть 0
Лучший способ предсказать будущее - это создать его - Авраам Линкольн
Подпишитесь на мой Twitter и присоединяйтесь к сабреддиту Geometric Deep Learning, чтобы получать последние новости в этой сфере.
Машинное обучение сегодня в моде, и как только наука догонит эту шумиху, оно, вероятно, станет нормой в нашей жизни. Один из способов, которым мы достигаем следующего шага, - это новая форма глубокого обучения; Геометрическое глубокое обучение. О вдохновении и идеях читайте здесь. Основное внимание в этой серии уделяется тому, как мы можем использовать глубокое обучение на графиках.
Две предпосылки, необходимые для понимания Graph Learning, заложены в самом названии; Теория графов и глубокое обучение. Это все, что вам нужно знать, чтобы понять природу этих двух идей и выработать высокоуровневую интуицию.

Теория графов - ускоренный курс
Что такое график?
Граф в контексте теории графов - это структурированный тип данных, который имеет узлы (объекты, содержащие информацию) и ребра (связи между узлами). который также может содержать информацию). Граф - это способ структурирования данных, но он сам может быть точкой данных. Графики - это тип неевклидовых данных, что означает, что они существуют в трехмерном виде, в отличие от других типов данных, таких как изображения, текст и аудио. Графики могут иметь определенные свойства, которые ограничивают возможные действия и анализ, которые могут быть выполнены с ними. Эти свойства можно определить.
Определения графов
Сначала давайте рассмотрим некоторые определения, полученные с помощью самой простой работы в Photoshop в моей жизни.
В информатике мы много говорим о структуре данных, известной как графики:

Графы могут иметь метки на краях и / или узлах, давайте дадим Грэхему метки для ребер и узлов.

Ярлыки также можно рассматривать как вес, но это остается на усмотрение дизайнера графика.
Ярлыки не обязательно должны быть числовыми, они могут быть текстовыми.

Ярлыки не обязательно должны быть уникальными; Вполне возможно, а иногда и полезно дать нескольким узлам одинаковый ярлык. Возьмем, к примеру, молекулу водорода:

Графики могут иметь функции (также известные как атрибуты) .

Следите за тем, чтобы не перепутать элементы и метки. Легкий способ подумать об этом - использовать аналогию с именами, персонажами и людьми:
узел - это человек, метка узла - это имя человека, а характеристики узла - это характеристики человека.
Графики могут быть направленными или ненаправленными:

Узел в графе может даже иметь ребро, которое указывает / соединяется с самим собой. Это называется зацикливанием.
Графики могут быть:
- Неоднородный - состоит из узлов разных типов.
- Однородный - состоит из узлов одного типа.
и либо:
- Статический - узлы и ребра не меняются, ничего не добавляется и не убирается.
- Динамический - узлы и ребра изменяются, добавляются, удаляются, перемещаются и т. д.
Грубо говоря, графики можно условно описать как
- Плотный - состоит из множества узлов и ребер.
- Редкий - состоит из меньшего количества узлов и ребер.
Можно сделать графики более аккуратными, превратив их в плоскую форму, что в основном означает перестановку узлов таким образом, чтобы края не пересекались.

Эти концепции и терминология пригодятся, когда мы исследуем множество различных методов, которые в настоящее время используются в различных архитектурах GNN. Некоторые из этих основных методов описаны в:
Графический анализ
Для модели машинного обучения доступно множество различных структур графиков (колесо, цикл, звезда, сетка, леденец, плотный, разреженный и т. д.)
Вы можете перемещаться по графику

В этом случае мы проходим неориентированный график. Очевидно, если бы граф был направленным, можно было бы просто следить за направлением ребер. Есть несколько разных типов обходов, поэтому будьте осторожны с формулировками. Вот пара наиболее распространенных терминов обхода графа и их значение:
- Обход: обход графа - закрытый обход - это когда целевой узел совпадает с исходным.
- Маршрут: прогулка без повторяющихся краев - круг - это замкнутая тропа.
- Путь: обход без повторяющихся узлов - c круг - это замкнутый путь.
Основываясь на концепции обходов, можно также отправлять сообщения через граф.

Все соседи Сэма отправляют ему сообщение, где t обозначает временной интервал. Сэм может открыть свой почтовый ящик и обновить свою информацию. Концепция распространения информации по сети очень важна для моделей с механизмами внимания. В графах передача сообщений - это один из способов обобщения сверток. Подробнее об этом позже.
E-graphs - графики на компьютерах
Изучив все это, вы теперь имеете базовое представление о теории графов! Любые другие концепции, важные для GNN, будут объяснены по мере их появления, но пока есть еще одна последняя тема, касающаяся графов, которую мы должны рассмотреть. Мы должны научиться выражать графики с помощью вычислений.
Есть несколько способов превратить график в формат, который компьютер может обработать; все они представляют собой разные типы матриц.
Матрица заболеваемости (I):
Матрица заболеваемости, которая в исследовательских работах обычно обозначается заглавной буквой I, состоит из единиц, нулей и -1. Матрица заболеваемости может быть составлена по простому шаблону. :

(Взвешенная) матрица смежности (A):
Матрица смежности графа состоит из единиц и нулей , если она не имеет других весов или пометок. В любом случае можно построить, следуя этому правилу:

Матрица смежности неориентированного графа поэтому симметрична по диагонали от верхнего левого объекта до нижнего правого:

Матрицы смежности ориентированных графов покрывают только одну сторону диагональной линии, так как ориентированные графы имеют ребра, идущие только в одном направлении.
Матрица смежности может быть «взвешенной», что в основном означает, что каждое ребро имеет связанное с ним значение, поэтому вместо единиц значение помещается в соответствующие координаты матрицы. Эти веса могут представлять все, что вы хотите. Например, в случае молекул они могут представлять тип связи между двумя узлами (атомами). В социальной сети, такой как LinkedIn, они могут представлять соединения 1-го, 2-го или 3-го порядка между двумя узлами (людьми).
Эта концепция весов для ребер - атрибут, который делает GNN такими мощными; они позволяют нам учитывать как структурную (зависимую), так и единичную (независимую) информацию. Для реальных приложений это означает, что мы можем рассматривать как внешнюю, так и внутреннюю информацию.
Матрица степеней (D):
Матрицу степеней графа можно найти, используя концепцию степеней, о которой говорилось ранее. D - это, по сути, диагональная матрица, где каждое значение диагонали - это степень соответствующего узла.

Обратите внимание, что степень - это просто сумма каждой строки матрицы смежности. Затем эти степени помещаются на диагональ матрицы (линия симметрии для матрицы смежности). Это хорошо ведет к окончательной матрице:
Матрица Лапласа (L):
Матрица Лапласа графа является результатом вычитания матрицы смежности из матрицы степеней:

Каждое значение в матрице степеней вычитается из соответствующего значения в матрице смежности как такового:

Существуют и другие представления матриц графов, такие как Матрица инцидентности, но подавляющее большинство приложений GNN для данных типа графа используют одну, две или все три из этих матриц. Это связано с тем, что они, и в частности лапласианская матрица, предоставляют существенную информацию о объектах (элементе с атрибутами) и отношениях (связи между объектами).
Не хватает только правила (функции, которая сопоставляет сущности с другими сущностями через отношения). Вот здесь и пригодятся нейронные сети.
Если вам нужно немного больше о графиках и их представлениях, я настоятельно рекомендую взглянуть на эту углубленную статью среднего уровня.
Глубокое обучение - ускоренный курс
Теперь давайте быстро рассмотрим вторую половину «Графика нейронных сетей». Нейронные сети - это архитектура, о которой мы говорим, когда кто-то говорит «Глубокое обучение». Архитектура нейронной сети построена на концепции перцептронов, которые вдохновлены взаимодействием нейронов в человеческом мозге.
Искусственные нейронные сети (или просто NN для краткости) и их расширенное семейство, включая сверточные нейронные сети, рекуррентные нейронные сети и, конечно же, графические нейронные сети, являются типами алгоритмов глубокого обучения.
Глубокое обучение - это тип алгоритма машинного обучения, который, в свою очередь, является подмножеством искусственного интеллекта.
Все начинается с простого линейного уравнения.
y = mx + b
Если мы структурируем это уравнение как перцептрон, мы увидим:

Где выход (y) - это сумма (E) смещения (b) и входа (x), умноженная на вес (m).
Нейронные сети обычно имеют функцию активации, которая в основном решает, следует ли считать выходной сигнал нейрона (y) «активированным», и сохраняет выходное значение перцептрона. в разумных и вычислимых пределах. (сигмоида для 0–1, tanh для -1–1, ReLU для 0 OR 1 и т. д.). Вот почему мы прикрепляем функцию активации к концу перцептрона.

Когда мы соединяем группу перцептронов вместе, мы получаем нечто, напоминающее начало нейронной сети! Эти перцептроны передают числовые значения от одного уровня к другому, с каждым проходом приближая это числовое значение к цели / метке, по которой обучается сеть.

Когда вы соединяете несколько перцептронов вместе, вы получаете:

Чтобы обучить нейронную сеть, нам нужно сначала рассчитать, сколько нам нужно для корректировки весов модели. Мы делаем это с помощью функции потерь, которая вычисляет ошибку.

Где e - ошибка, Y - ожидаемый результат, а Ŷ - фактический результат. На высоком уровне ошибка рассчитывается как фактический результат (прогноз NN) минус ожидаемый результат (цель). Цель состоит в том, чтобы минимизировать ошибку. Ошибка сводится к минимуму за счет регулировки веса каждого слоя с помощью процесса, известного как обратное распространение.
По сути, обратное распространение распределяет корректировки по сети, начиная от выходного уровня до входного. Регулируемая величина определяется функцией оптимизации, которая получает ошибку в качестве входных данных. Функцию оптимизации можно представить в виде шара, катящегося с холма, при этом местоположение шара является ошибкой. Следовательно, когда мяч катится к основанию холма, ошибка минимальна.
Кроме того, необходимо определить некоторые гиперпараметры, одним из наиболее важных из которых является скорость обучения. Скорость обучения регулирует скорость применения функции оптимизации. Скорость обучения подобна настройке гравитации; чем выше сила тяжести (выше скорость обучения), тем быстрее мяч катится с холма, и то же самое верно и в обратном направлении.

Нейронные сети имеют множество различных макро- и микроконфигураций, которые делают каждую модель уникальной с разным уровнем производительности, но все они основаны на этой ванильной модели. Позже мы увидим, насколько это верно, особенно для обучения графам. Такие операции, как свертки и повторения, будут вводиться по мере необходимости.
Глубокое обучение - это теория графов
Чтобы связать все, что мы исследовали, и проверить наши знания, мы обратимся к слону в комнате. Если вы прислушивались, то могли заметить тонкий, но очевидный факт:
Искусственные нейронные сети - это на самом деле просто графики!
Сетевые сети - это особый граф, но они имеют одинаковую структуру и, следовательно, одинаковую терминологию, концепции и правила.
Напомним, что структура перцептрона по сути:
Изображение перцептрона (изменено)
Мы можем представить входное значение (x), значение смещения (b) и операцию суммирования (E) как 3 узла в графе. Мы можем думать о весе (m) как о ребре, соединяющем входное значение (x) с операцией суммирования (E).
Конкретный тип графа, который больше всего похож на NN, - это многочастные графы. Многодостаточный граф - это граф, который можно разделить на разные наборы узлов. Узлы в каждом наборе могут иметь общие ребра между наборами, но не внутри каждого набора.

Некоторые нейронные сети даже имеют полностью связанные узлы, условные узлы и другие сумасшедшие архитектуры, которые придают NN их универсальность и мощь торговой марки; вот некоторые из самых популярных архитектур:
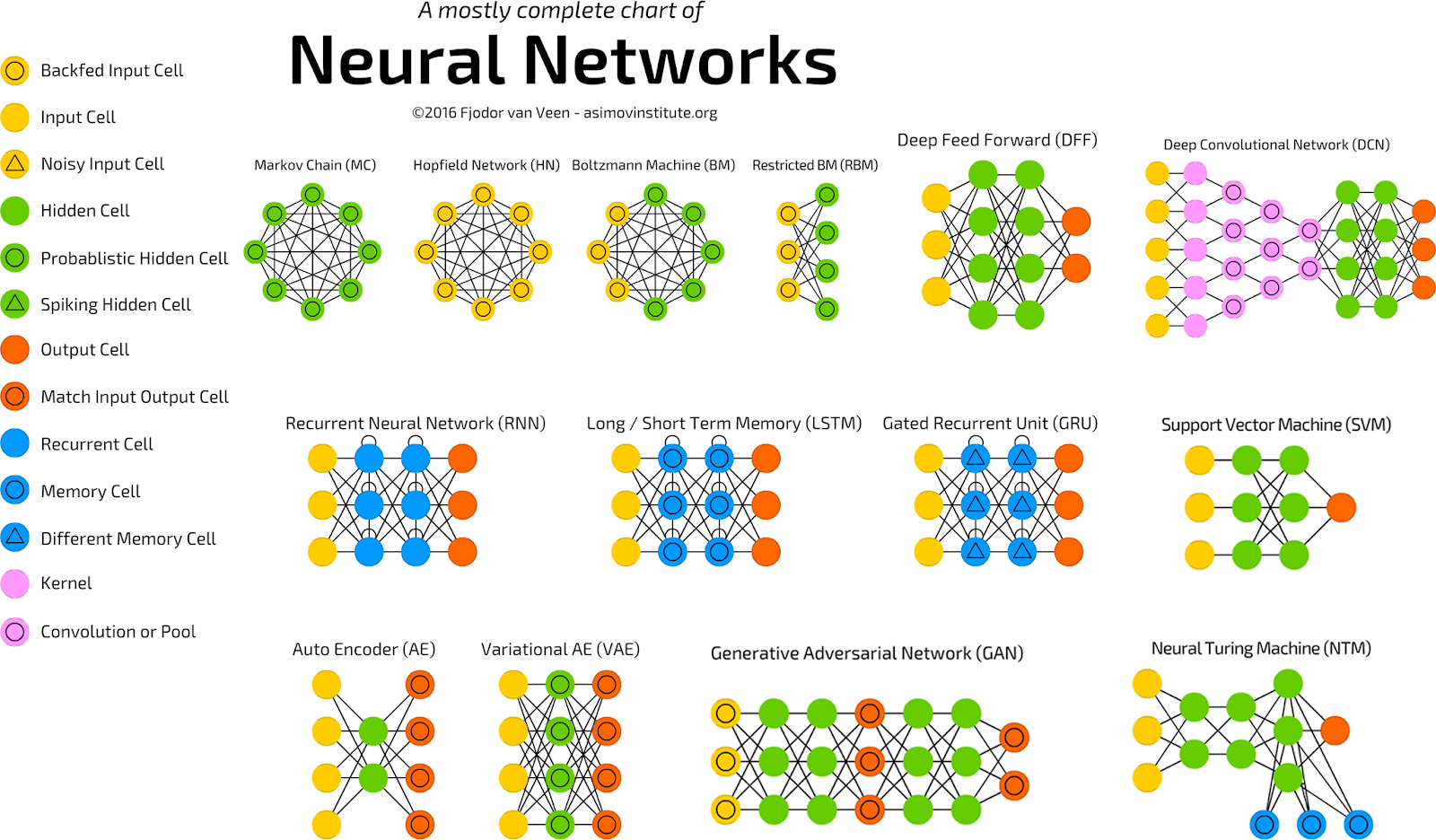
Каждый цвет соответствует разному типу узла, который можно расположить множеством различных способов. Распространение данных вперед или назад по сети аналогично передаче сообщений в виде графиков. Элементы ребер или узлов на графике аналогичны весам в нейронной сети. Обратите внимание на то, что некоторые узлы даже имеют упомянутые ранее петли (присущие RNN - рекуррентным нейронным сетям).
Нейронные сети - не единственные модели машинного обучения, которые имеют графоподобную структуру.
- K-означает
- K-ближайшие соседи
- Решение tress
- Случайные леса
- Цепи Маркова
все они структурированы как сами графики или выводят данные в виде графической структуры.
Следовательно, подразумевается, что модели Graph Learning могут использоваться для обучения на самих алгоритмах машинного обучения. Есть потенциальное применение в оптимизации гиперпараметров. Именно так поступили авторы этой удивительной статьи.
Возможности только начинают проявляться по мере того, как мы узнаем больше об обобщении глубокого обучения на геометрических данных.
В сущности
Мы рассмотрели много, но, резюмируя, мы погрузились в 3 концепции
- Теория графов
- Глубокое обучение
- Машинное обучение с теорией графов
Имея в виду предварительные условия, можно полностью понять и оценить Graph Learning. На высоком уровне Graph Learning дополнительно исследует и использует взаимосвязь между Deep Learning и Graph Theory с использованием семейства нейронных сетей, предназначенных для работы с неевклидовыми данными.
Ключевые выводы
Есть много ключевых выводов, но основные из них:
- Все графики имеют свойства, определяющие возможные действия и ограничения, для которых они могут быть использованы или проанализированы.
- Графики представлены вычислительным способом с использованием различных матриц. Каждая матрица предоставляет различный объем или тип информации.
- Глубокое обучение - это разновидность машинного обучения, которая примерно имитирует то, как человеческий разум работает с нейронами.
- Глубокое обучение обучается за несколько итераций, передавая информацию вперед по сети и распространяя корректировки нейронов в обратном направлении.
- Нейронные сети (и другие алгоритмы машинного обучения) тесно связаны с теорией графов; некоторые сами по себе являются графиками или выводят их.
Теперь у вас есть все предпосылки, чтобы погрузиться в чудесный мир обучения графам. Хорошим местом для начала было бы изучение разновидностей графических нейронных сетей, которые были разработаны к настоящему времени.
Хотите увидеть больше подобного контента?
Подпишитесь на меня в LinkedIn, Facebook, Instagram и, конечно же, на Medium, чтобы получить больше контента.
Весь мой контент находится на моем веб-сайте, а все мои проекты - на GitHub
Я всегда хочу познакомиться с новыми людьми, сотрудничать или узнать что-то новое, поэтому не стесняйтесь обращаться к [email protected]
Вверх и вперед, всегда и только 🚀