Искусство эксплуатации памяти

Буфер
Буфер - это временное хранилище, обычно присутствующее в физической памяти, используемой для хранения данных.

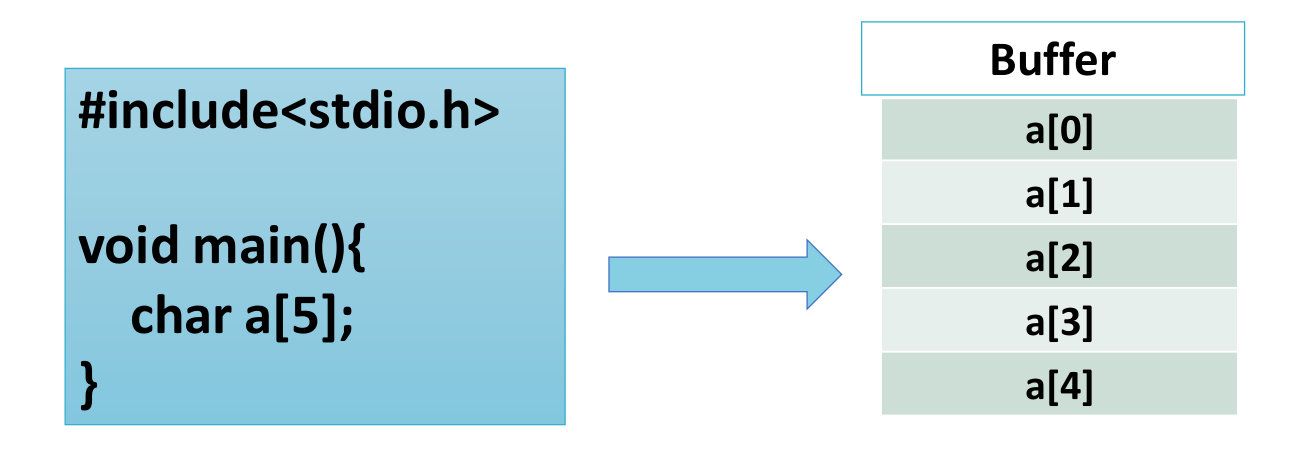
Рассмотрим программу, показанную на левом изображении, где определен символьный буфер длиной 5. В большом кластере памяти для буфера будет назначена небольшая память размером 5 байтов, которая выглядит как изображение справа.
Переполнение буфера
Переполнение буфера происходит, когда в память определенной длины записывается больше данных таким образом, что смежные адреса памяти перезаписываются.
Демо (управление локальными переменными)
Давайте рассмотрим пример приложения для базовой аутентификации, которое запрашивает пароль и возвращает Authenticated!, если пароль правильный.
Не зная, как работает приложение, давайте введем случайный пароль.

Там написано Authentication Declined!, поскольку пароль неверный. Для тестирования нам нужно ввести большие случайные данные.

Вам должно быть интересно, почему он прошел аутентификацию и почему существует Segmentation fault. Посмотрим более подробную версию приложения.
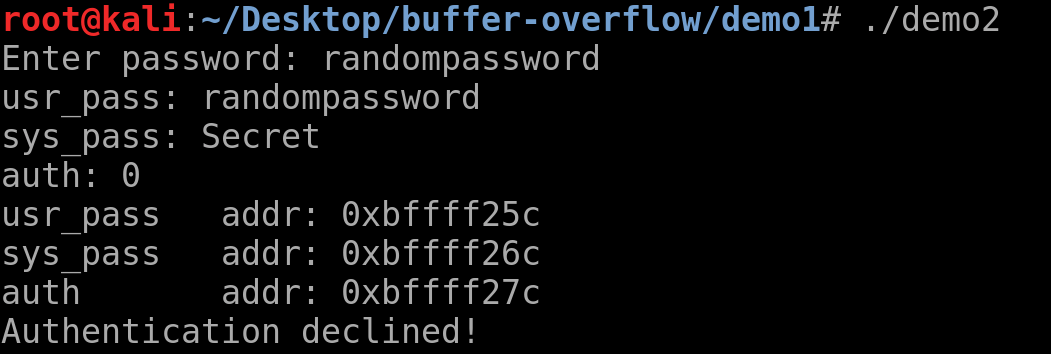
Как видите, есть три переменных: auth, sys_pass и usr_pass.
Переменная auth определяет, аутентифицирован пользователь или нет, в зависимости от значения (изначально 0). В usr_pass хранится пароль, который вводит пользователь, а в переменной sys_pass указывается правильный пароль.
Как работает приложение, если переменная usr_pass равна sys_pass, тогда переменная auth становится 1. Если переменная auth не равна 0, то пользователь аутентифицирован.
Вы также можете увидеть, как переменные хранятся в памяти. Поскольку адрес указан в шестнадцатеричном формате и разница составляет 1, переменные usr_pass и sys_pass являются буферами длиной 16.
Для проверки переполнения буфера вводится длинный пароль, как показано.
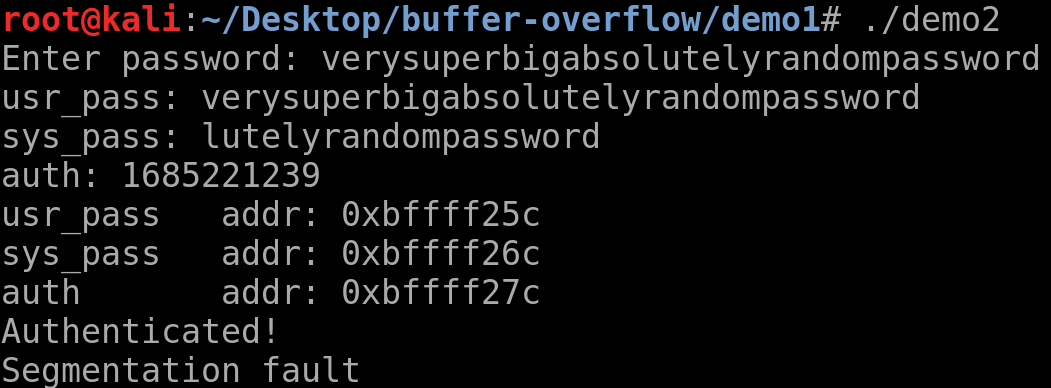
Как видите, пароль, введенный в переменную usr_pass, выходит за пределы переменной sys_pass, а затем переменной auth.
Примечание: функции C, такие как strcpy(), strcmp(), strcat(), не проверяют длину переменной и могут перезаписывать более поздние адреса памяти, что и есть переполнение буфера.
Обратитесь к приведенному ниже коду для лучшего понимания.
#include <stdio.h>
int main(void) {
int auth = 0;
char sys_pass[16] = "Secret";
char usr_pass[16]; printf("Enter password: ");
scanf("%s", usr_pass); if (strcmp(sys_pass, usr_pass) == 0) {
authorized = 1;
} printf("usr_pass: %s\n", usr_pass);
printf("sys_pass: %s\n", sys_pass);
printf("auth: %d\n", authorized);
printf("sys_pass addr: %p\n", (void *)sys_pass);
printf("auth addr: %p\n", (void *)&authorized); if (auth) {
printf("Authenticated!\n");
}
else{
printf("Authentication declined!\n");
}
}
Примечание: это может быть нереалистичный пример и предназначен только для понимания. Вы можете не увидеть таких ситуаций в реальной жизни.
Давайте теперь немного углубимся в концепции.
Разделение памяти для запущенного процесса

Источник: Техно-трюк.
Так выглядит память, назначенная процессу. Существуют различные разделы, такие как stack, heap, Uninitialized data и т. Д., Которые используются для разных целей.
Подробнее о структуре памяти можно прочитать здесь: Структура памяти процесса.
Этот блог посвящен переполнению буфера в стеке, давайте посмотрим на это.
- Стек: структура данных LIFO, широко используемая компьютерами при управлении памятью и т. Д.
- В памяти присутствует несколько регистров, но мы будем интересоваться только EIP, EBP и ESP.
- EBP: это указатель стека, указывающий на основание стека.
- ESP: это указатель стека, указывающий на верхнюю часть стека.
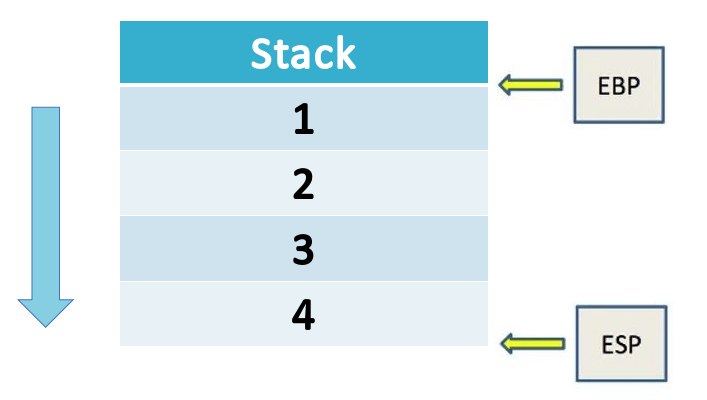
5. EIP: содержит адрес следующей инструкции, которая должна быть выполнена.
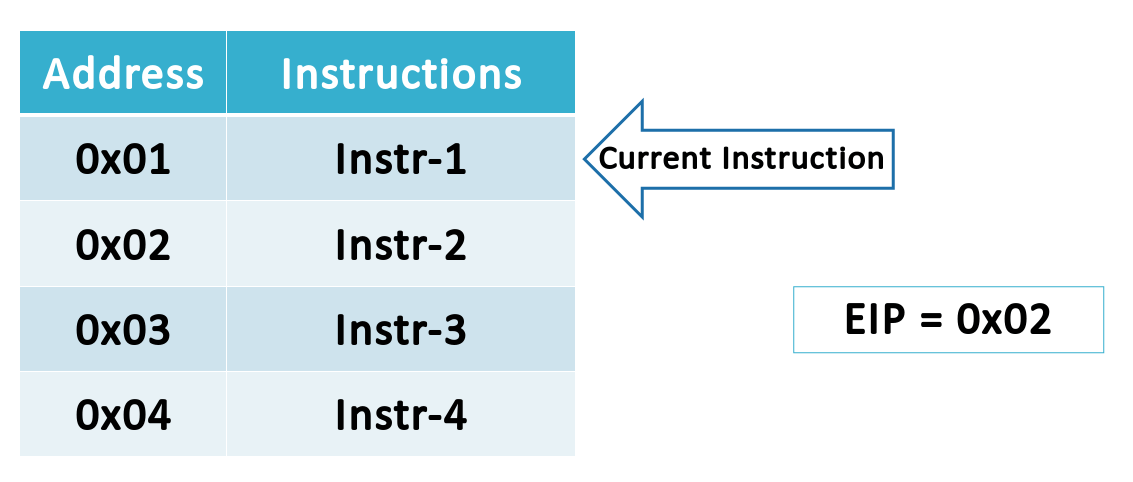
Макет стека

На изображении выше показано, как выглядит stack. Это может показаться устрашающим, но поверьте мне, это не так.
Давайте посмотрим на некоторые важные моменты, связанные со стеком:
- Стек заполняется от более высокой памяти до более низкой памяти.
- В стеке доступ ко всем переменным осуществляется относительно EBP.
- В программе каждая функция имеет свой собственный стек.
- Все ссылается на регистр EBP.
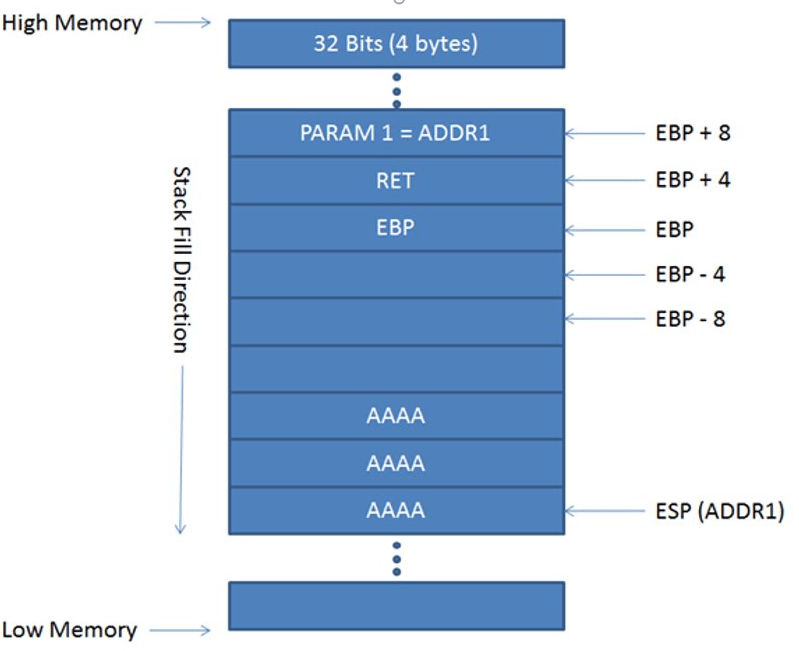
Источник: IT & Security Stuff.
Над EBP хранятся параметры функции.
Например:
void foo(int a, int b, int c){
//Function body
}
Здесь a, b и c - параметры функции, хранящиеся над EBP.
- Все локальные переменные функции хранятся под EBP.
Old %ebp- это значение EBP предыдущей функции. Поскольку после выполнения функции она должна вернуться к более старой функции, нам нужно сохранить значения как старого EBP, так и EIP.- Регистр ESP хранит адрес нижней части стека.
Например:
void foo(int a, int b, int c){
int x;
int y;
int z;
}
Здесь x, y, z - это локальные переменные функции, которые хранятся ниже EBP.
Использование переполнения буфера
Пришло время заняться эксплуатацией переполнения буфера с помощью стека.
Перед этим давайте попробуем понять, как строится стек для любой функции.
Давайте посмотрим на пример ниже:
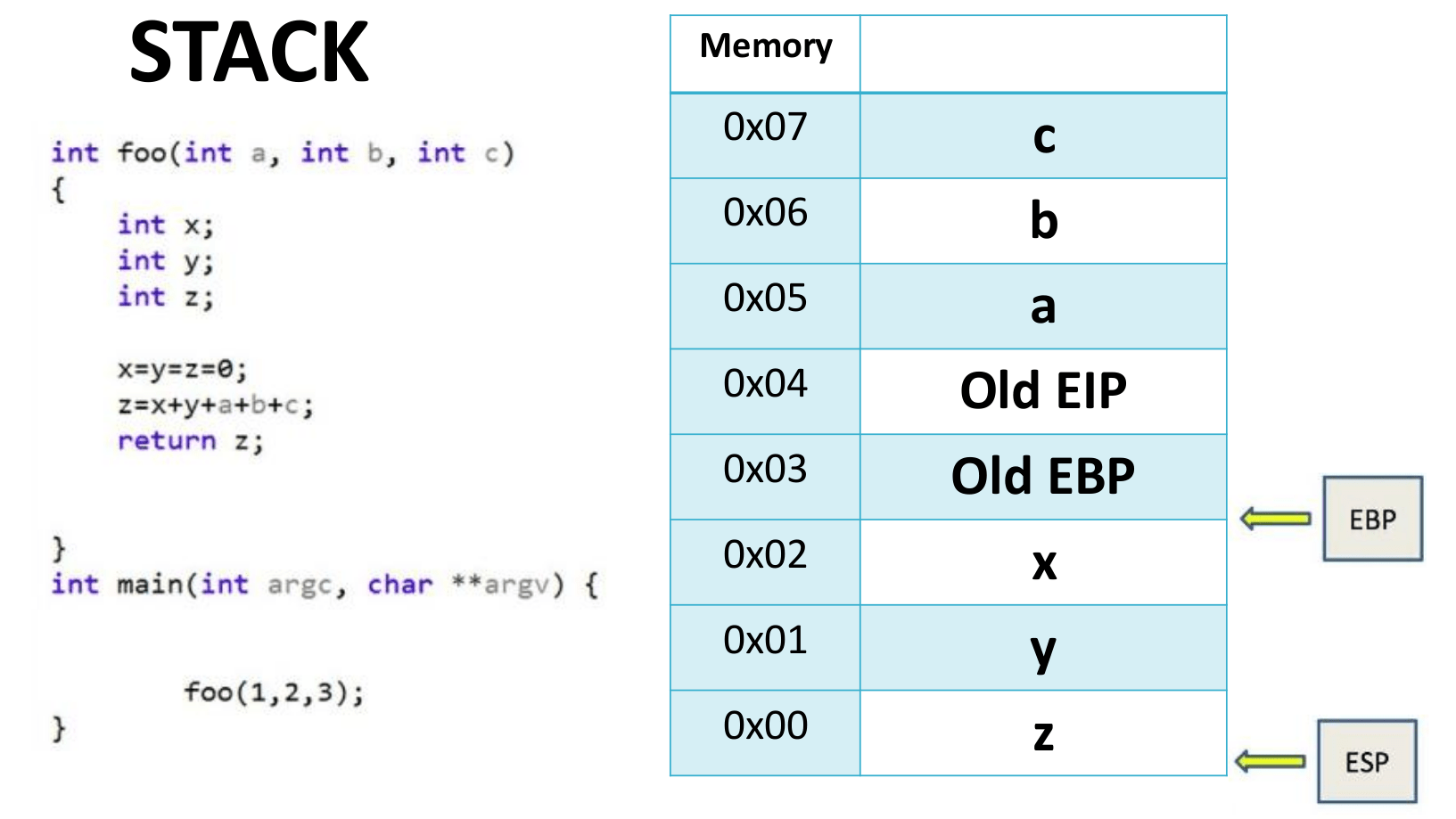
Стек справа - это функция foo, как показано на левом изображении.
- Поскольку
a,bиcявляются параметрами, передаваемыми функции, они хранятся над EBP. Кроме того, поскольку стек заполняется сверху вниз, а параметры считываются справа налево, сначала в память записываетсяc, за которым следуютbиa. x,yиz- это локальные переменные, хранящиеся ниже EBP.- Также необходимо сохранить
Old EIPиOld EBPфункцииmainв стеке, чтобы знать, куда вернуться после выполнения функции.
Теперь, как показано в предыдущей демонстрации, вы можете увидеть, как происходит переполнение буфера, используя локальные переменные.

Источник: Security Sift.
Представьте себе ситуацию, когда вы переполняете переменные x, y и z таким образом, что старый EIP изменяется и сохраняет адрес памяти, в которой размещен вредоносный код.
Обратитесь к изображению ниже для лучшего понимания.

Предположим, что буфер длиной 500 определен в функции. Теперь он переполнен таким образом, что в нем есть какие-то случайные данные, за которыми следует шелл-код (вредоносный код), а затем адрес возврата, который указывает на шелл-код.
Итак, после выполнения функции выполняется инструкция, на которую указывает адрес возврата, и именно так выполняется наш шелл-код.
Примерно так происходит переполнение буфера.
Вы должны посмотреть это видео: Атака переполнения буфера - Computerphile, чтобы получить более реалистичное представление о переполнении буфера. Коды, использованные в приведенном выше видео, находятся на GitHub.
Меры безопасности
- Используйте языки программирования, такие как Python, Java или Ruby, в которых происходит динамическое распределение памяти, а сам язык управляет памятью за вас.
- В таких языках, как C и C ++, перед записью данных в буфер выполните все соответствующие проверки и проверку ввода.
- Прежде чем использовать какие-либо внешние библиотеки, проверьте их на наличие уязвимостей.
- Используйте инструменты анализа исходного кода для статического анализа уязвимостей.
- Использовать неисполняемый стек: это означает, что даже если машинный код вводится в стек, он не может быть выполнен, поскольку эта конкретная область памяти не является исполняемой. Это делается установкой бита NX.
Примечание. Даже после принятия этих мер возможно использование переполнения буфера. Следовательно, это всего лишь уровни безопасности, которые могут помочь предотвратить использование переполнения буфера.
использованная литература
- Разбить стопку ради удовольствия и прибыли
- Использование переполнения буфера и меры противодействия
- Уязвимости и атаки, связанные с переполнением буфера
Не забывайте оставлять аплодисменты, если вам понравился блог :)
Давайте подключимся?
LinkedIn: https://linkedin.com/in/ashwigoel
Сайт: https://ashwingoel.com
Электронная почта: [email protected]