Учебник по эволюционным алгоритмам
В течение последнего десятилетия глубокое обучение доминировало в сфере машинного обучения, часто в ущерб другим методам. Как специалисту по обработке данных, важно иметь в своем распоряжении множество инструментов, и один класс методов, который, как мне кажется, слишком часто упускается из виду, - это эволюционные алгоритмы. Сказать это (я являюсь промежуточным продуктом давно действующего эволюционного алгоритма) может показаться немного самонадеянным, но я считаю эволюционный метод проектирования прекрасным и во многих случаях более прагматичным, чем традиционные методы машинного обучения. В этом руководстве мы рассмотрим обучение нейронных сетей с использованием эволюционного алгоритма и воспользуемся этим методом для решения задач регрессии, классификации и политик. Для этого мы будем использовать Python и библиотеку NumPy.
Алгоритм
Эволюционные алгоритмы основаны на предпосылке естественного отбора и включают пятиэтапный процесс:
- Создайте начальную популяцию организмов. В нашем случае это будут нейронные сети.
- Оцените каждый организм по некоторым критериям. Это оценка приспособленности организма.
- Возьмите лучшие организмы из шага два и дайте им возможность воспроизвести. Потомство может быть либо идентичными копиями одного родителя (бесполое размножение), либо мозаикой двух или более родителей (половое размножение).
- Мутировать потомство.
- Возьмите новую популяцию мутировавших потомков и вернитесь ко второму шагу. Повторяйте до тех пор, пока не будет выполнено какое-либо условие (например, пройдет фиксированное количество поколений, будет достигнута целевая пригодность и т. Д.).
Шаг 1: Организм
В этом уроке мы будем использовать полностью связанные нейронные сети с прямой связью в качестве наших организмов.

При конструировании наших организмов мы руководствуемся четырьмя руководящими принципами:
- Мы должны иметь контроль над входными и выходными размерами организмов. По сути, мы пытаемся разработать некоторую функцию f, которая отображает ℝᵃ ⟶ ℝᵇ, поэтому a и b должны быть встроены в организм. Мы достигаем этого путем параметризации входных и выходных размеров.
- Мы должны контролировать функцию активации вывода. Вывод организмов должен соответствовать решаемой задаче. Мы достигаем этого путем параметризации активации выхода.
- Мы должны контролировать сложность организмов. Идеальный организм должен быть достаточно сложным, чтобы развивать целевую функцию, и не более того. Мы достигаем этого путем параметризации количества скрытых слоев и их размеров. В более продвинутом алгоритме этого можно достичь, позволив организму развить свою собственную архитектуру и снизив сложность с помощью функции приспособленности.
- Организмы должны быть совместимы для полового размножения. К счастью, вышеуказанные принципы гарантируют, что это будет так. Все организмы будут иметь одинаковую архитектуру, поэтому «обмен генетическим материалом» здесь означает, что потомство получит часть веса слоя от мамы, а часть от папы.
Вот реализация:
В функции __init__ настраиваем сеть. Параметр dimensions - это список размеров слоя, где первый - это ширина ввода, последний - ширина вывода, а все остальные - скрытые размеры. Функция __init__ выполняет итерацию по этим n измерениям для создания весовых матриц n-1 с использованием инициализации Glorot Normal, которые сохраняются как layers. Если смещение включено, ненулевой вектор смещения также сохраняется для каждого слоя. В модели используется активация ReLU для всех внутренних слоев. Активация выхода указывается с помощью параметра output и может быть softmax, sigmoid или linear, как реализовано в методе _activation.
Метод predict многократно применяет ReLU и матричное умножение к входной матрице. Например, если сеть была сделана с тремя скрытыми слоями и выходом softmax, то сеть применила бы функцию
Y = softmax (ReLU (ReLU (ReLU (XW₁ ) W₂) W₃) W₄)
Если X - это входная матрица, Wᵢ - весовая матрица для слоя i, а Y - выходная.
Мы будем создавать популяцию этих организмов, все с одинаковой архитектурой, но каждый с разным случайным весом.
Шаг 2: Организм Фитнес
Измерение того, насколько хорошо работает организм, является ключевым моментом при разработке эволюционного алгоритма, и «хорошая производительность» варьируется от задачи к задаче. В регрессии оценка пригодности может быть отрицательной среднеквадратической ошибкой. В классификации это может быть точность классификации. В игре Pac-Man это может быть количество сожженных шариков перед смертью. Поскольку фитнес-функции зависят от конкретной задачи, мы подождем, чтобы изучить их, пока не появится раздел приложений ниже. На данный момент достаточно понять, что нам нужна функция scoring_function, которая принимает организм в качестве входных данных и возвращает выход с действительным числом, где чем больше, тем лучше.
Шаг 3: воспроизведение
Этап воспроизводства состоит из двух этапов: отбор родителей и создание потомства. Каждому новому организму нужны k родителей. При бесполом размножении k равно 1, а при половом размножении k равно 2 и более. Следовательно, чтобы создать новое поколение n организмов, мы должны выбрать n наборов k организмов из предыдущего поколения; Решение о том, какой организм (ы) будет воспитывать каждого ребенка, должно приниматься на основе их оценки приспособленности, при этом наиболее приспособленные организмы должны производить больше всего потомства. Есть много способов сделать это, в том числе:
- Равномерно выберите каждого родителя из 10% лучших организмов.
- Расположите организмы от лучшего к худшему, затем выберите индекс каждого родителя путем выборки из экспоненциального распределения.
- Примените функцию softmax к количеству оценок каждого организма, чтобы создать вероятность отбора для каждого организма, а затем выполните выборку из этого распределения.
Я выбрал компромисс между методами один и два, где 10% лучших организмов были выбраны в качестве первого родителя ребенка по десять раз каждый, а второй родитель был выбран случайным образом с использованием экспоненциального распределения, как указано выше. Я также потребовал, чтобы клон наиболее эффективных организмов данного поколения был включен в следующее поколение. Вот соответствующий код:
Как видите, организмы оцениваются и сортируются в строках 5 и 6. Затем в цикле в строке 8 создаются population_size новых организмов. Родительский организм выбирается из верхних 10% в строке 9 (holdout - количество организмов которые являются гарантированным потомством, здесь _11 _ // 10). Когда mating включен, родительский номер два выбирается с использованием экспоненциального распределения с λ = holdout. Когда спаривание отключено, родитель спаривается сам с собой, а ребенок является клоном.
После выбора n пар родителей, потомство может быть создано путем случайного объединения признаков из каждой пары. В нашем случае эти характеристики являются весами в слоях нейронной сети. Вот метод Organism класса для создания потомства:
Как видите, метод mate подтверждает, что оба родителя совместимы друг с другом, а затем случайным образом выбирает родителя, от которого следует унаследовать каждый вектор-столбец в каждой матрице весов для дочернего организма.
Шаг 4: Мутация
После создания каждый дочерний организм подвергается мутации (фрагмент 3, строка 18). В этом руководстве шаг мутации реализован как добавление гауссовского шума к каждому весу в сети. Мы не меняем здесь активации или архитектуру сети, хотя более продвинутый эволюционный алгоритм определенно мог бы сделать это, добавляя или удаляя узлы в скрытых слоях. Вот код:
Шаг 5: повторить
Это вряд ли шаг; Все, что остается сделать, - это проверить, выполняется ли какое-либо условие, и вернуться к шагу два, если это не так. Я решил запустить алгоритм для фиксированного количества поколений, но остановка, когда оценка пригодности достигает желаемого порога или после того, как некоторое количество поколений проходит без улучшений, также является хорошим выбором. Вот полный код классов Organism и Ecosystem:
заявка
"Прохладный. Почему я должен переживать?" - ты вероятно
Регресс
Давайте применим этот процесс к проблеме регрессии. Мы будем развивать организм для аппроксимации sin (τ x) в области x ∈ [0, 1]. Очевидно, это тривиальная проблема, и поэтому мы используем ее в качестве примера. Итак, как нам разработать наши организмы?
- Это функция от ℝ¹ до ℝ¹, поэтому размерность входа и выхода будет равна 1.
- Диапазон синуса [-1, 1], поэтому активация выхода будет линейной.
- Функция приспособленности будет отрицательной среднеквадратической ошибкой продукции организма.
- Мы будем использовать три скрытых слоя шириной 16, потому что это, вероятно, достаточно сложно для этой простой задачи.
Вот код:
Полученные результаты:
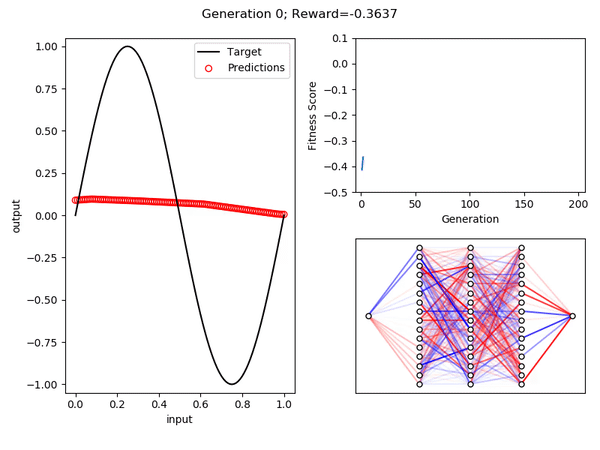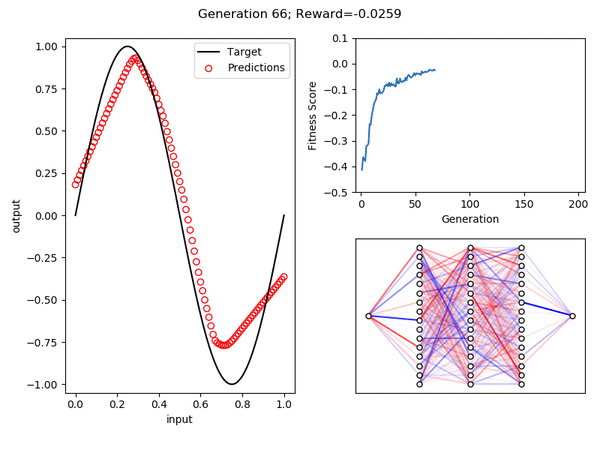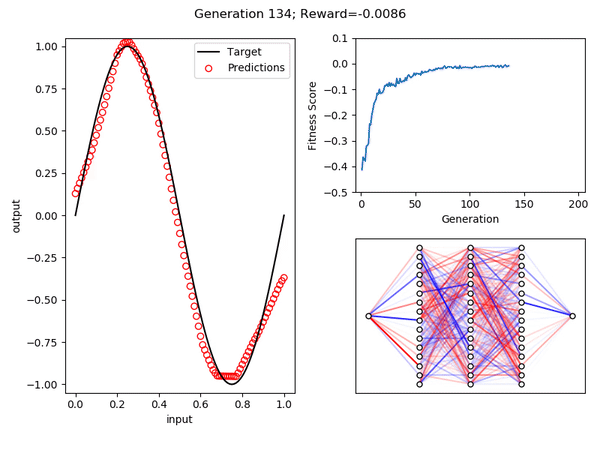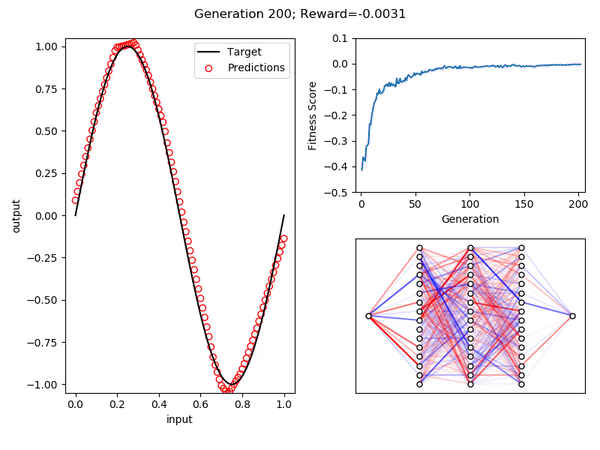
Как видите, после 200 поколений развился организм, который дает довольно хорошее приближение функции синуса в области [0, 1].
Классификация
Давайте посмотрим, как эта техника справляется с проблемой классификации. Здесь мы используем набор данных радужки. Для непосвященных (добро пожаловать!) Набор данных ириса - это многолетний набор значений длины и ширины чашелистиков и лепестков из 150 цветков ириса. Каждый цветок принадлежит к одному из трех видов, и задача состоит в том, чтобы классифицировать цветок по видам на основе его четырех измерений. Так что это значит для наших организмов?
- Каждый цветок имеет четыре действительных размера, поэтому наше входное измерение будет равно четырем.
- Есть три разных класса, поэтому наше выходное измерение будет три.
- Поскольку мы выбираем один класс, наша активация вывода будет softmax.
- Мы протянем треть данных от обучения для тестирования. Это сделано для того, чтобы организм не запоминал ответы.
Вот код:
Полученные результаты:

Каждая диаграмма рассеяния представляет собой пару различных функций, нанесенных друг на друга. Каждая точка представляет собой цветок, где цвет контура представляет истинный класс, а цвет заливки представляет предсказанный класс. Тренировка и тестирование лучшего организма в каждом поколении показаны на линейном графике, а лучший организм показан на правой центральной панели. Всего за 15 поколений экосистема развивает сеть, которая правильно классифицирует весь набор тестов!
Политика
Давайте попробуем разработать организм, способный играть в «игру» OpenAI CartPole, включенную в пакет AI Gym. Вот пример с YouTube:
Шест прикрепляется к тележке, которая движется по бесконтактной дорожке, с помощью незадействованного шарнира. Система управляется приложением к тележке силы +1 или -1. Маятник запускается вертикально, и цель состоит в том, чтобы не допустить его падения. Награда +1 предоставляется за каждый временной шаг, когда шест остается в вертикальном положении. Эпизод заканчивается, когда штанга отклоняется от вертикали более чем на 15 градусов или тележка перемещается более чем на 2,4 единицы от центра.
На каждом временном шаге игры состояние игры представлено как вектор из четырех действительных чисел, соответствующих горизонтальному положению тележки, горизонтальной скорости тележки, углу полюса и угловой скорости полюса. Затем игрок должен применить действие (применить силу +1 или -1), и игра продвинется на один временной шаг. Игрок «выиграл» игру, если он смог избежать проигрыша за 500 временных шагов.
Итак, что это значит для нашей экосистемы и организмов?
- Каждый временной шаг имеет четыре измерения с действительным знаком, поэтому наше входное измерение будет равно четырем.
- Возможны два действия, поэтому наше выходное измерение будет равно двум.
- Поскольку мы выбираем одно действие, наша активация выхода будет softmax.
- Фитнес-функция - это количество оставшихся временных шагов. Для надежности мы запустим моделирование 5 раз и возьмем среднее количество оставшихся временных шагов.
Вот код:
Неужели все так просто? Что ж, вот результаты:

Верно, в экосистеме появился организм, который победил в игре всего за 6 поколений. Я сам был немного шокирован; в строке 31 вы заметите, что я ожидал, что для этого потребуется гораздо больше. Я намеревался показать физическую пригодность с течением времени, как и в двух других задачах, но не буду беспокоить вас этим, поскольку шесть точек данных не дают интересных цифр.
Заключение
Эволюционные алгоритмы интуитивно понятны и эффективны. Хотя приведенные выше примеры были довольно простыми, они демонстрируют, что эволюционные алгоритмы применимы к широкому классу задач. Эволюционные алгоритмы особенно полезны в ситуациях, когда пригодность решения поддается измерению, но не таким образом, чтобы легко допускать обратное распространение градиента, как в игре CartPole. По этим причинам стоит добавить эволюционные алгоритмы в ваш набор инструментов машинного обучения. Следите за обновлениями в моей следующей статье, в которой я подробно расскажу о фитнес-функциях и о том, как разумные предположения могут привести к невероятно плачевным результатам.