Для начала вам не понадобится много опыта в машинном обучении.

Две недели назад мы были на воркшопе Машинное обучение в продакшене, который проводили мои друзья из @TheGurusTeam. Во время этого, среди прочего, мы настроили сервер отслеживания MLflow и использовали его для развертывания нескольких моделей ML локально (на виртуальную машину сервера MLflow) и в облаке (AWS Sagemaker).
И вскоре стало ясно, что культура DevOps очень важна в среде науки о данных. Стандартного способа развертывания моделей в производстве не существует. С MLflow легко разделить процесс создания и обучения моделей и их использования для прогнозирования в производственной среде.
С помощью MLflow мы можем значительно сократить разрыв между обоими мирами, поскольку легко запускать новые модели в производство без повторной реализации какого-либо кода и с минимальными инженерными усилиями.
Хорошо, но этот пост не (только) о MLflow.
Я хотел пойти дальше и сказать, что Microsoft полностью поддерживает MLflow с открытым исходным кодом в Машинном обучении Azure. Это означает, что мы, как разработчики, можем использовать API отслеживания MLflow (даже без настройки сервера отслеживания) для отслеживания запусков и развертывания моделей в облаке (служба машинного обучения Azure).
НЕОБХОДИМЫЕ УСЛОВИЯ
Для репликации содержимого этого поста вам потребуется учетная запись Azure, среда разработки Python (предпочтительнее Linux) (мы используем Pycharm, VirtualBox, MobaXterm, git и т. д.). желательно знание bash, Docker, Kubernetes, языка Python, машинного обучения и облака Azure :-)
Шаг 0
Прежде всего, мы должны создать рабочую область Azure ML. Впоследствии мы получим его следующим скриптом:
# workspace.py def get_workspace(): ws = Workspace.get(name=WORKSPACE_NAME, subscription_id=SUBSCRIPTION_ID, resource_group=RESOURCE_GROUP) return ws
Разбивая лед (ванильное Azure ML)
Предположим, у вас есть обученная модель (или представьте, что ваш специалист по данным дал ее вам) сериализованную. В нашем репозитории он называется худшим.pickle и расположен в папке `artifacts` (основан на простой обученной модели регрессии Ridge с помощью scikit-learn). Вы можете зарегистрировать модель в рабочем пространстве Azure ML, используя следующий скрипт:
# model.py from azuremite.workspace import get_workspace def model_register(): ws = get_workspace() model = Model.register(workspace=ws, model_path=”../artifacts/worst.pickle”, model_name=”worst-model”) return model
После регистрации модели вы можете легко получить ее путь:
# model.py def get_model_path(): ws = get_workspace() model_path = Model.get_model_path(‘worst-model’, _workspace=ws) return model_path
Впоследствии, чтобы получить объект модели, вы также должны десериализовать его:
# score.py from azuremite.model import get_model_path from sklearn.externals import joblib def get_model(): model_path = get_model_path() _model = joblib.load(model_path) return _model
Теперь мы готовы разработать простой скрипт подсчета очков:
# score.py
from sklearn.externals import joblib
from azuremite.model import get_model_path
import pandas as pd
def get_model():
model_path = get_model_path()
_model = joblib.load(model_path)
return _model
def init():
global model
# retrieve the path to the model file using the model name
model = get_model()
def run(raw_data):
df = pd.DataFrame(data)
jsonContent = pd.DataFrame.to_json(df, orient=’split’)
print(f”invocaremos con {jsonContent}”)
# make prediction
y_hat = model.predict(df)
# you can return any data type as long as it is JSON-serializable
return y_hat.tolist()
if __name__ == ‘__main__’:
init()
data = [[2000]]
prediction = run(data)
print(prediction)
В этот момент вы можете представить, что следующим шагом будет предоставление метода run как REST API. Да, это будет простая операция, и когда вы ее сделаете, модель будет готова делать прогнозы, доступ к ней можно получить несколькими простыми способами (REST API, любые «конвейеры» и т. Д.).
Но я полагаю, вы это уже знали. Я надеюсь, что с этого момента содержание станет определенно интересным.
Работа с Azure ML (стиль MLflow)
Мы начинаем предлагать некоторую поддержку специалистам по данным на этапе обучения модели.
Для первого впечатления вы можете взглянуть на следующий блокнот Jupyter:
import mlflow from azureml.core import Workspace from azuremite.configuration import WORKSPACE_NAME, SUBSCRIPTION_ID, RESOURCE_GROUP, EXPERIMENT_NAME, MODEL_PATH from sklearn.linear_model import Ridge import mlflow.sklearn def get_workspace(): ws = Workspace.get(name=WORKSPACE_NAME, subscription_id=SUBSCRIPTION_ID, resource_group=RESOURCE_GROUP) return ws
Это ключ: в следующих двух строках мы получаем ссылку на рабочую область Azure ML и настраиваем ее для работы в качестве сервера отслеживания для MLflow.
ws = get_workspace() mlflow.set_tracking_uri(ws.get_mlflow_tracking_uri())
Этот метод извлекает данные для обучения (в данном случае из файла .csv)
def get_training_data(): sample_files_path = os.environ.get(‘SAMPLE_FILES_PATH’,’.’) trainingDataFilePath = sample_files_path + ‘/articulos_ml.csv’ data = pd.read_csv(trainingDataFilePath) # veamos cuantas dimensiones y registros contiene (son 161 registros con 8 columnas) # print(data.shape) # Vamos a RECORTAR los datos en la zona donde se concentran más los puntos filtered_data = data[(data[‘Word count’] <= 3500) & (data[‘# Shares’] <= 80000)] return filtered_data
Этот метод описывает простой тренировочный процесс:
def train(alpha_arg, training_data): dataX = training_data[[“Word count”]] X_train = np.array(dataX) y_train = training_data[‘# Shares’].values # Creamos el objeto de Regresión Ridge regr = Ridge(alpha=alpha_arg) # Entrenamos nuestro modelo (worst model ever) regr.fit(X_train, y_train) return regr
И этот сегмент кода можно считать жемчужиной в короне этого ноутбука. Мы начинаем регистрацию нового эксперимента Azure ML (всего лишь немного API MLflow). Затем мы продолжаем объявлять «запуск» (да, оба MLflow и Azure ML используют те же концепции, что и «эксперименты», «запуски», «показатели журнала», «артефакты журналов», «модели журналов» и т. Д.), Обучение модель, регистрируя некоторые метрики и, наконец, регистрируя (сохраняя) обученную модель. Помните, что мы работаем против AzureML с помощью MLflow API.
experiment_name = EXPERIMENT_NAME mlflow.set_experiment(experiment_name) with mlflow.start_run(): alpha = 0.01 regression_model = train(alpha) mlflow.log_metric(‘alpha’, alpha) # Save the model to the outputs directory for capture model_save_path = MODEL_PATH mlflow.sklearn.log_model(regression_model, model_save_path)
Вы можете увидеть (видимые) результаты на следующих снимках экрана:

Мы можем отслеживать показатели и время выполнения на панели мониторинга Azure.


После того, как процесс обучения и регистрации (сохранения) модели завершен, самое время извлечь и оценить ее.
Следующий фрагмент кода покажет вам, как получить модель из последнего прогона (эксперимента):
# model2.py
from azureml.core.model import Model
from azuremite.workspace import get_workspace
from azuremite.configuration import EXPERIMENT_NAME, MODEL_PATH
import mlflow.sklearn
def get_experiment():
ws = get_workspace()
experiment_name = EXPERIMENT_NAME
exp = ws.experiments[experiment_name]
return exp
def get_last_run_id():
exp = get_experiment()
runs = list(exp.get_runs())
runId = runs[0].id
print(f”last run ID={runId}”)
return runId
def get_model_uri(runId=get_last_run_id(), model_save_path=MODEL_PATH):
ws = get_workspace()
mlflow.set_tracking_uri(ws.get_mlflow_tracking_uri())
model_uri = ‘runs:/{}/{}’.format(runId, model_save_path)
return model_uri
def get_model(runId=get_last_run_id(), model_save_path=MODEL_PATH):
ws = get_workspace()
mlflow.set_tracking_uri(ws.get_mlflow_tracking_uri())
model_uri = get_model_uri(runId, model_save_path)
model = mlflow.sklearn.load_model(model_uri)
return model
Мы надеемся, что названия методов будут понятными. С помощью методов, показанных выше, вы можете провести эксперимент, найти идентификатор последнего запуска или получить модель, связанную с данным запуском (идентификатор).
Теперь модель готова для ее скоринга с помощью следующего (такого же простого, как и последний) скрипта:
# score2.py from sklearn.externals import joblib from azuremite.model2 import get_model import pandas as pd from azureml.core.model import Model def init(): global model # retrieve the model model = get_model() def run(raw_data): df = pd.DataFrame(data) # make prediction y_hat = model.predict(df) # you can return any data type as long as it is JSON-serializable return y_hat.tolist() if __name__ == ‘__main__’: init() data = [[2000]] prediction = run(data) print(prediction)
Создание изображения
Пришло время упаковать и развернуть модель как образ контейнера, который, наконец, позволит представить модель как веб-службу.
Это действительно просто, мы покажем, как это сделать с помощью простого сегмента кода (помните, MLflow API):
# image.py def build_image(): ws = get_workspace() m_uri = get_model_uri() azure_image, azure_model = mlflow.azureml.build_image(model_uri=m_uri, workspace=ws, model_name=’worst-model’, image_name=IMAGE_NAME, synchronous=True)

Это приводит к созданию образа контейнера, который отображается в разделе «Изображения» рабочей области:

Развертывание модели
Еще один шаг, чтобы нанести глазурь на торт.
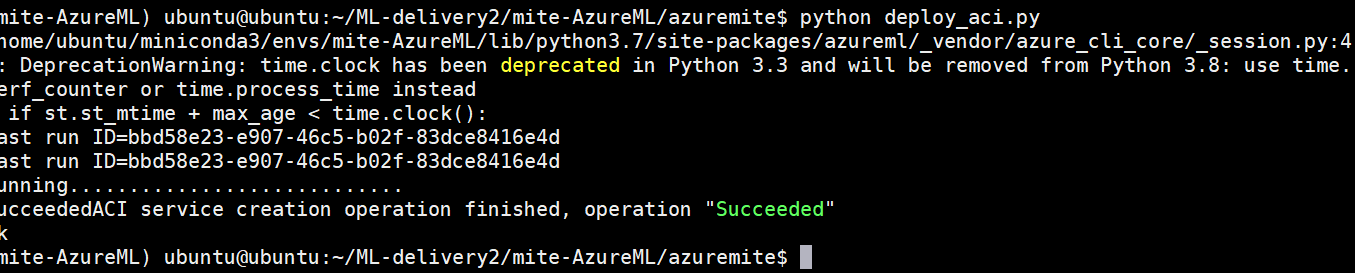
Недавно созданный образ можно развернуть в экземплярах контейнеров Azure (ACI) или в службе Azure Kubernetes (AKS) для обслуживания с помощью всего нескольких строк кода (конечно, с помощью MLflow API).
# deploy_aci.py
from azureml.core.webservice import AciWebservice, Webservice
from azuremite.workspace import get_workspace
from azuremite.image import get_image
from azuremite.configuration import LOCATION, MODEL_NAME
def deploy_image():
ws = get_workspace()
azure_image = get_image()
aci_config = AciWebservice.deploy_configuration(cpu_cores=1, memory_gb=1, tags={‘method’ : ‘sklearn’},
description=’Worst model’,
location=LOCATION)
webservice = Webservice.deploy_from_image(image=azure_image, workspace=ws, name=MODEL_NAME, deployment_config=aci_config)
webservice.wait_for_deployment(show_output=True)
if __name__ == ‘__main__’:
deploy_image()
{kind=link}
Подробности реализации, отображаемые в пользовательском интерфейсе машинного обучения Azure:


На этом этапе мы можем запросить конечную точку оценки веб-службы ACI, отправив HTTP-запрос POST, который содержит входной вектор, например, с помощью Postman:

Поскольку платформа ACI рекомендуется только для развертывания промежуточных моделей и моделей разработки, мы, наконец, развертываем модель в производственной среде с помощью службы Azure Kubernetes (AKS).
# deploy_aks.py from azuremite.workspace import get_workspace from azuremite.image import get_image from azuremite.cluster import get_cluster from azuremite.configuration import AKS_NAME from azureml.core.webservice import Webservice, AksWebservice def deploy_image(): ws = get_workspace() azure_image = get_image() # Set the web service configuration (using default here with app insights) aks_config = AksWebservice.deploy_configuration(enable_app_insights=True) # Unique service name service_name = AKS_NAME aks_target = get_cluster() # Webservice creation using single command aks_service = Webservice.deploy_from_image( workspace=ws, name=service_name, deployment_config = aks_config, image = azure_image, deployment_target = aks_target) aks_service.wait_for_deployment(show_output=True) if __name__ == ‘__main__’: deploy_image()
Прежде чем запрашивать конечную точку оценки веб-службы AKS, мы должны узнать URI:
# deploy_aks.py from azuremite.workspace import get_workspace from azuremite.image import get_image from azuremite.cluster import get_cluster from azuremite.configuration import AKS_NAME from azureml.core.webservice import Webservice, AksWebservice def get_service(): ws = get_workspace() services = Webservice.list(workspace = ws, compute_type=’AKS’) return services[0] if __name__ == ‘__main__’: print(get_service().scoring_uri)
Мы снова оцениваем прогнозы для обученной (регрессионной) модели.
Используя простой скрипт:
# score3.py
from azuremite.deploy_aks import get_service
import pandas as pd
import requests
import json
def init():
wservice = get_service()
key1, key2 = wservice.get_keys()
global scoring_uri, headers
headers = {‘Content-Type’:’application/json’,
‘Authorization’: ‘Bearer ‘ + key1}
print(headers)
scoring_uri = wservice.scoring_uri
def run():
jsonContent = {“columns”:[0],”index”:[0],”data”:[[2000]]}
# make prediction
resp = requests.post(scoring_uri, json=jsonContent, headers=headers)
# you can return any data type as long as it is JSON-serializable
print(resp.status_code)
print(resp.content)
return resp.json()
if __name__ == ‘__main__’:
init()
prediction = run()
print(prediction)

или используя Почтальон:


Заключение
С этой публикацией вы теперь сможете обслуживать модель машинного обучения в AKS (служба Azure Kubernetes). Настроить проект легко, и вы можете сэкономить много времени, если вы новичок, обслуживающий модели машинного обучения в облаке. Как видите, MLflow API предоставляет простой способ запустить и развернуть предварительно обученные модели за считанные минуты.
Не стесняйтесь проверять мое репо. Он был опубликован под безлицензионной лицензией, поэтому не стесняйтесь изменять и использовать его для своего проекта.
Хотите учиться?
Я веб-разработчик и разработчик больших данных из Мадрида (Испания). Сосредоточение внимания на новейших достижениях в области разработки программного обеспечения, больших данных, машинного обучения и темах, связанных с облачными технологиями. Не стесняйтесь связываться со мной в LinkedIn или Github.