Алгоритмическая предвзятость (предвзятость ИИ) — это феномен, который возникает, когда алгоритм дает результаты, которые систематически искажаются из-за ошибочных предположений в процессе машинного обучения. Можно подумать, что инструменты на основе искусственного интеллекта (AI) должны давать беспристрастные результаты, если они управляются машиной; однако этот миф необходимо развеять, поскольку эти инструменты учатся на примерах (набор данных) вместо того, чтобы следовать инструкциям. Как объясняет Кэсси Козырков, главный инженер по разведке в Google, наборы данных — это учебники для машинных студентов, по которым они могут учиться, и как у обычных учебников есть авторы-люди, у которых могут быть свои собственные предубеждения, так и у наборов данных. Поэтому неудивительно, если у ученика или у машины появляются искаженные взгляды, когда им преподают предвзятое содержание. Поэтому пользователей предостерегли от использования этих инструментов ИИ. Но это не помешало растущей популярности инструментов ИИ или отрасли решить предвзятость ИИ. Поскольку большая часть мира принимает идеал разнообразия, решения по исправлению предвзятости ИИ также заключаются в том, чтобы сделать наборы данных разнообразными.
2. Разнообразие наборов данных Что, почему, как
Алгоритм так же хорош, как и данные, которые вы в него вкладываете. Инструменты искусственного интеллекта зависят от чистых, точных и хорошо размеченных данных для получения точных результатов. Именно поэтому проекты ИИ тратят больше всего времени на сбор и создание целостного набора данных. Набор данных, который имеет пропорциональное количество различных классов (метки), скорее всего, будет более разнообразным. Например, обучающий набор данных, необходимый для создания фильтра электронной почты, будет иметь такие метки, как спам и не спам, тогда как обучающий набор данных о различных животных будет иметь такие метки, как кошка, собака, лошадь. и т. д. Разнообразный набор данных, вероятно, будет иметь сопоставимое количество каждой из этих меток в наборе данных.
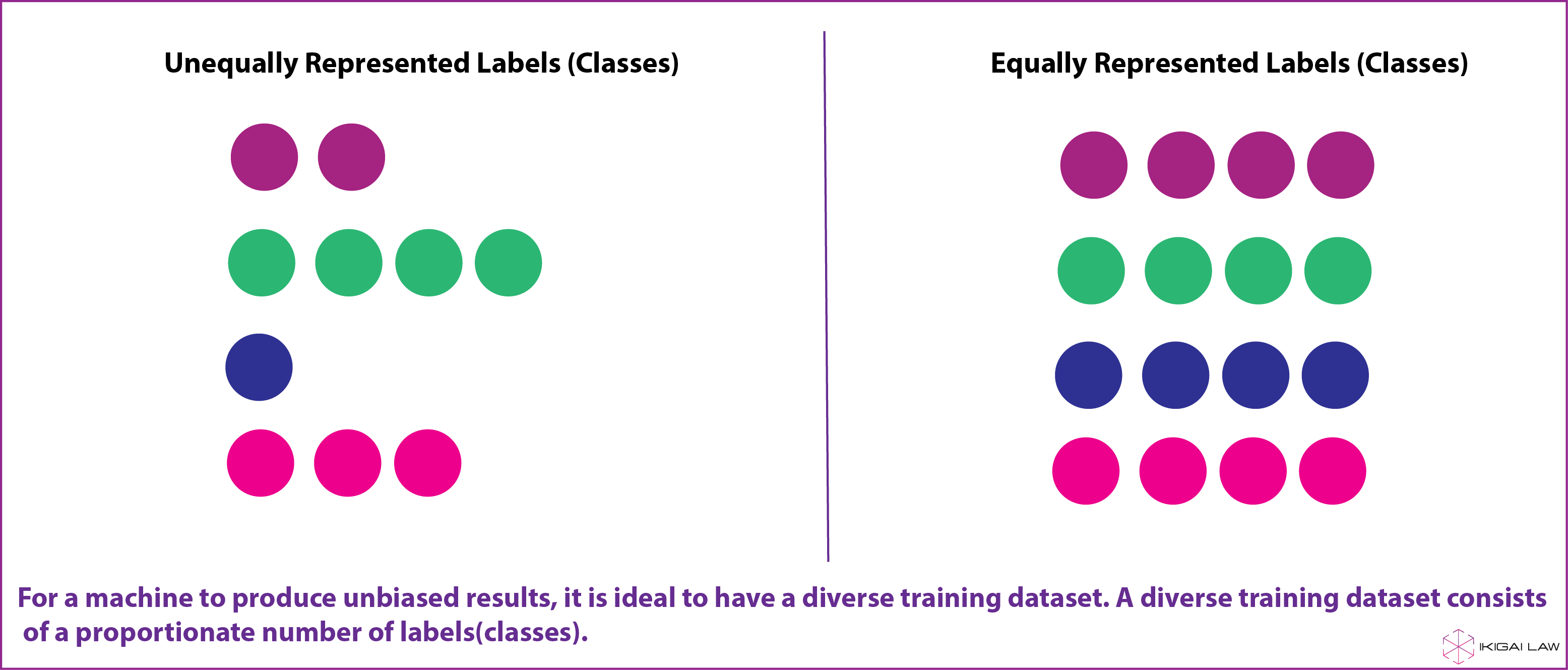
Наличие сбалансированной частоты каждого класса в наборе данных для обучения имеет решающее значение для любого инструмента ИИ для получения точных результатов. Система распознавания лиц Amazon, которая использовалась полицией для идентификации преступников, давала 40% ложных совпадений для лиц по цвету. Это произошло из-за более низкой частоты цветных лиц (и других групп меньшинств) по сравнению с белыми лицами в обучающем наборе данных системы. Также высказано мнение, что системы распознавания лиц точно определяют расы, которые их развивают, в случае с Amazon это были белые люди. Поэтому такие компании, как IBM, теперь вложили значительные средства в то, чтобы сделать свои обучающие наборы данных более разнообразными.
Системы распознавания лиц создаются с использованием подмножества моделей машинного обучения (ML), называемых моделями глубокого обучения. Алгоритмы глубокого обучения для таких систем реализуются с использованием искусственных нейронных сетей (ИНС). Несмотря на то, что ANN являются подкатегорией моделей ML, они функционируют совершенно иначе, чем базовые модели ML. Базовые модели машинного обучения улучшают свою производительность при выполнении задачи T, измеряемой P, изучая опыт E, тогда как модели глубокого обучения представляют свой мир как вложенную иерархию понятий, где каждое понятие определяется по отношению к более простому. понятие и аналогичным образом более абстрактные представления вычисляются в терминах менее абстрактных представлений. Также замечено, что производительность модели глубокого обучения увеличивается с увеличением количества данных, тогда как производительность других моделей обычно останавливается после определенного момента.
Рассмотрим следующий график (источник), чтобы понять, как больше данных влияет на производительность и точность.
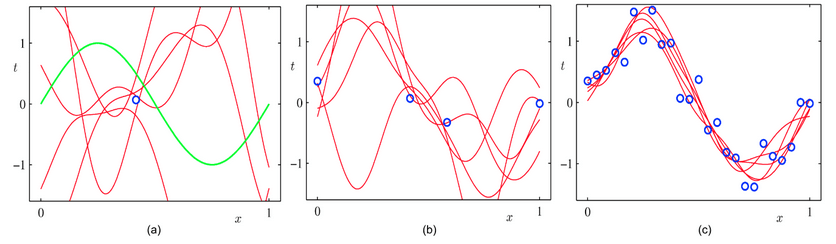
Цель на приведенном выше слайде — подобрать кривую, которая будет напоминать траекторию зеленой кривой. Если бы мы подогнали кривую, проходящую через единственную синюю точку, которая является одной точкой данных, как показано на рисунке (а), мы бы столкнулись с несколькими кривыми, которые соответствовали бы критериям. По мере увеличения количества точек данных количество кривых, удовлетворяющих условию, уменьшается, как показано на рисунке (b), и, наконец, соответствует кривой, аппроксимирующей зеленую кривую, как показано на рисунке ©. С увеличением точек данных алгоритм находится в лучшем положении для обобщения выходных данных, которые будут соответствовать требованиям пользователя. Та же аналогия применима к системам распознавания лиц, где предоставление алгоритму более разнообразных лиц позволяет ему идентифицировать более четкие черты лица (такие как изменение цвета, положение органов, размер органов и т. д.), тем самым повышая его точность. Наличие меньшего количества экземпляров цветных лиц похоже на наличие одной синей точки (как показано на рисунке (а)), где алгоритм с большей вероятностью рассмотрит темное лицо, как у гориллы (аналогично подбору нескольких возможных, но неправильные кривые, как показано на рисунке (а)). Следовательно, наличие значительного количества всех меток было бы обязательным условием точности алгоритма.
Другая проблема, которая может возникнуть из-за непропорциональной частоты меток, заключается в том, что алгоритм неправильно классифицирует случаи меньшинства как «аномалию». Поскольку эти алгоритмы основаны на обобщении, алгоритм, на который оказывается давление с целью получения результата в течение короткого промежутка времени, может полностью отклонить ярлыки меньшинства, классифицируя их как выбросы, что может привести к снижению общей точности.
Обычно получение разнообразного набора данных является сложной задачей. Иногда это может быть связано с полным отсутствием информации на определенных этикетках, таких как дни стихийных бедствий, или иногда получение информации может быть дорогим. Решения широкого уровня для устранения предвзятости ИИ требовали внести больше разнообразия в команды разработчиков инструментов ИИ с точки зрения навыков, взглядов, пола, этики, дисциплины и т. д. Точно так же решения технического уровня также были направлены на разработку методов. это изменит набор обучающих данных, чтобы он стал хорошо сбалансированным. Это может быть достигнуто, но не ограничивается:
1. Продуманное добавление недопредставленных меток данных.
Пример этого метода можно увидеть в Google Быстро рисуй! эксперимент. Этот эксперимент был направлен на ознакомление широкой международной аудитории с ИНС. Людей просили рисовать обычные предметы, в то время как система одновременно пыталась распознать эти объекты менее чем за 20 секунд. В рамках процесса рисования в ходе эксперимента было собрано более 115 000 рисунков обуви, однако команда разработчиков поняла, что в этом наборе данных в подавляющем большинстве представлены кроссовки. Учитывая такую высокую частоту появления кроссовок, система была настроена на идентификацию только кроссовок как обуви. Здесь команде разработчиков пришлось искать дополнительные тренировочные дудлы других стилей обуви, чтобы заполнить пробелы и разнообразить набор данных.
2. Создание разнообразного дочернего набора данных из большего родительского набора данных.
Пример этого метода можно увидеть в работе Prasad et al. (2014), где исследователи реконструировали небольшой набор данных из большого набора входных данных, но более сбалансированного по отношению к различным меткам. Один из способов реализации этой модели поясняется на инфографике ниже.
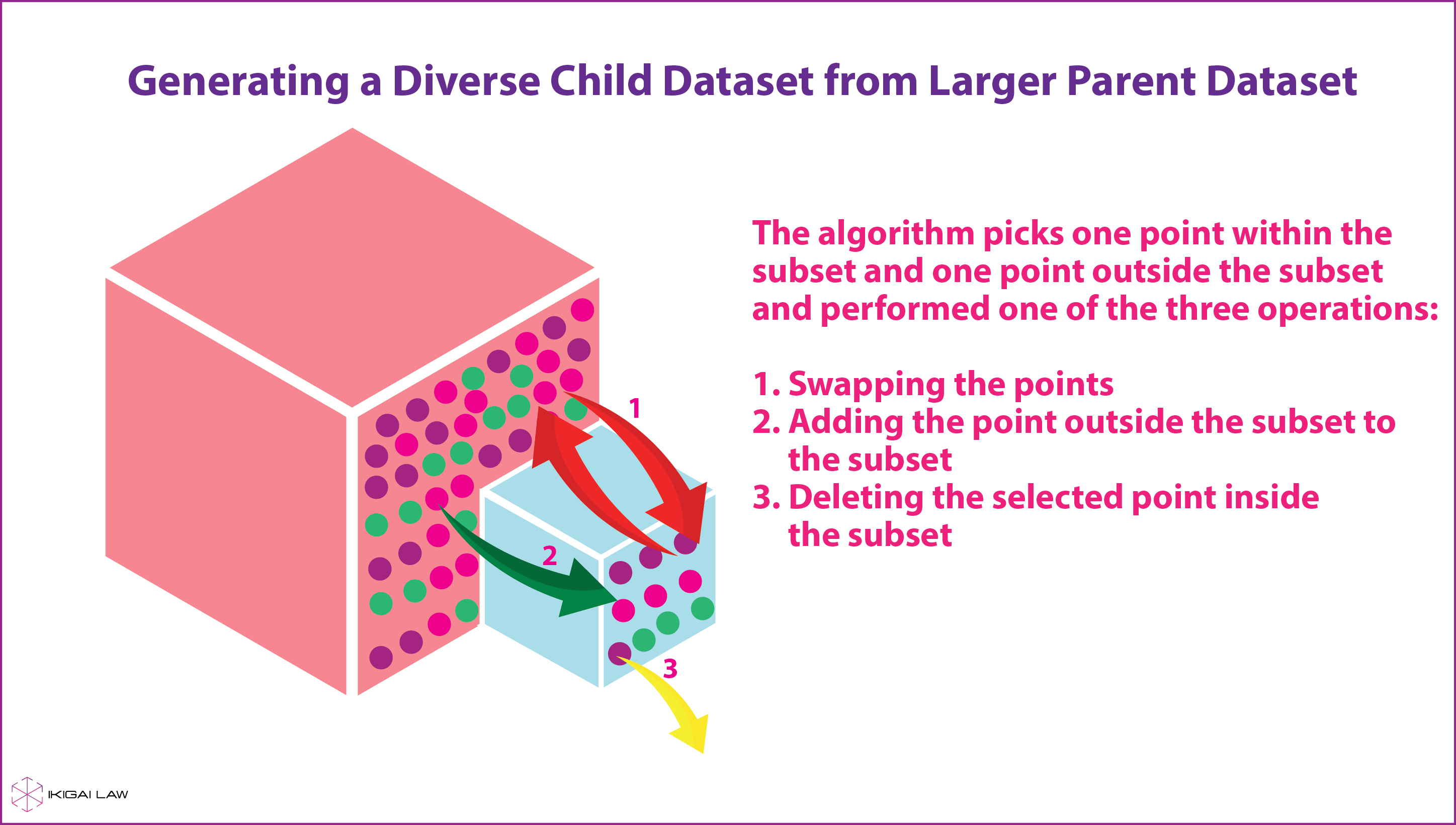
Чтобы лучше понять этот процесс, представьте себе большую коробку с разноцветными шариками и маленькую пустую коробку. Задача состоит в том, чтобы заполнить меньшую коробку шариками из большей коробки так, чтобы все шарики разных цветов были хорошо представлены. Идея здесь состоит в том, чтобы сначала взять шарики случайным образом из большой коробки, положить их в меньшую коробку и заполнить ее до краев. Затем вы выбираете по одному шарику из каждой коробки и выполняете одну из трех операций: (а) меняете местами шарики, т.е. вы кладете шарик из большей коробки в меньшую коробку, а шарик из меньшей коробки в большую коробку; (b) Вы только добавляете шарик из большей коробки в меньшую; © Вы удаляете только шарик из меньшего ящика из всей системы. Этот процесс замены, добавления или удаления шариков продолжается до тех пор, пока каждая операция не увеличивает разнообразие шариков в маленькой коробке, и останавливается только тогда, когда система достигает равновесия, при котором добавление или удаление любого шарика из маленькой коробки приведет к разнообразию шариков. падать. На практике этот метод показал многообещающие результаты в случае создания трейлеров к фильмам или обобщения длинных документов за счет включения всех типов информации и обеспечения разнообразия, тем самым уменьшая предвзятость в отношении доминирующих меток.
3. Изучение латентных структур [1].
Рассмотрим такой пример: здание подожжено. Обычно количество пожарных машин, прибывающих на место, и стоимость ущерба от пожара оказываются коррелированными. Однако на самом деле увеличение размера пожара приведет к увеличению как пожарных машин, так и стоимости потерь, что опровергает первоначальную гипотезу о том, что пожарные машины и стоимость потерь каким-то образом коррелируют. Здесь размер пожара — неучтенная латентная переменная. Латентная (скрытая по-гречески) переменная — это неизмеряемая, невидимая переменная, которая ведет себя как вмешивающаяся и вызывает два события X и Y, без которых X и Y казались бы коррелированными. Изучение латентных структур помогает нам объяснить искажающий фактор, на основе которого корреляция между X и Y обычно ослабевает или исчезает, и позволяет нам делать соответствующие прогнозы.
Пример этого метода можно увидеть в работе Amini et al. (2019), где исследователи использовали алгоритм глубокого обучения для выявления недопредставленных частей набора обучающих данных (здесь общедоступный набор данных CelebA, который содержит различные изображения лиц, обычно используемые для обучения систем распознавания лиц) и увеличил вероятность (или шанс) выбора цветного лица по сравнению с белым лицом, так что он создал сбалансированный набор данных с одинаково представленными метками. Это аналогично принуждению алгоритма выбирать одно цветное лицо для одного белого лица, чтобы поддерживать соотношение 1:1, несмотря на то, что исходный набор данных имеет соотношение цветных лиц к белым лицам 1:10. Это расчетное увеличение выбора определенных точек данных (или выборки) вызвано изучением скрытой структуры в наборе обучающих данных. Исследователи пришли к выводу, что их метод показал повышенную точность классификации и снижение категориальной предвзятости по признаку расы и пола по сравнению со стандартными классификаторами.
(Автор: Виханг Джумле, помощник, при участии Анирудха Растоги, основателя Ikigai Law. Инфографика создана Акрити Гарг, менеджером по коммуникациям.)
[1] Скрытая структура определяется путем изучения вероятностного распределения скрытых переменных набора данных.
Первоначально опубликовано на https://www.ikigailaw.com 14 августа 2019 г.