
Отказ от ответственности: я только что получил диплом специалиста в области науки о данных со специализацией в области больших данных и потоковой аналитики, но я ни в коем случае не являюсь экспертом в этой области. Чего я надеюсь достичь с помощью этого поста, так это упростить то, что я узнал из программы, объяснить неспециалистам, желающим узнать больше об этой области. Я, конечно, не смогу рассказать все о больших данных в этом посте, но я хотел бы хотя бы провести параллели между анализом больших данных и традиционным анализом данных, чтобы больше людей не боялись приближаться к нему. Не стесняйтесь исправлять любые неправильные представления, которые у меня могут быть.
Долгое время термин большие данные использовался, чтобы ввести в заблуждение людей как внутри, так и за пределами области науки о данных. Скажите кому-нибудь на сетевой сессии, что вы занимаетесь ИИ, машинным обучением и большими данными, и на вас сразу же будут смотреть с восхищением, как если бы вы были богоподобной фигурой. Святая Троица, которая, кажется, означает все, но ничего. Потому что о чем именно мы говорим, когда говорим ИИ, машинное обучение и большие данные? В моем предыдущем посте о нечетких модных словах, используемых в науке о данных я объяснил, как эти термины на самом деле означают очень разные вещи, которые концептуально не связаны.

«Большие данные» просто означают огромные объемы данных. Машинное обучение или ИИ не обязательно должны быть связаны с большими данными, потому что этот термин просто описывает тип данных. Вы можете принимать большие данные, хранить большие данные, обрабатывать большие данные или анализировать большие данные, и все это без использования машинного обучения. Точно так же «искусственный интеллект» - это просто описание вычислительного процесса, похожего на человека, который может включать или не включать машинное обучение. ИИ можно достичь разными способами, и машинное обучение - лишь один из многих методов. На самом деле имеет смысл сказать: «Я использовал машинное обучение для решения этой проблемы», но если кто-то говорит «Я использовал ИИ для решения этой проблемы», они, вероятно, имеют в виду, что они использовали машинное обучение.
Разница между машинным обучением и искусственным интеллектом:
Если он написан на Python, это, вероятно, машинное обучение;
если он написан в PowerPoint, это, вероятно, AI.
- Мат Веллосо (технический советник технического директора Microsoft)
Что такое большие данные?
Теперь, когда мы избавились от этих запутанных терминов, давайте сосредоточимся на объяснении, что такое большие данные. Я знаю, что приятно говорить людям, что вы работаете с большими данными, но, как показывает опыт, если вы можете загружать свои данные и работать с ними с помощью Microsoft Excel или диспетчера баз данных SQL, я сожалею, что сообщаю вы, вероятно, не имеете дело с большими данными. Как следует из названия, размер больших данных может входить в диапазон терабайт, поэтому попытка загрузить его в Excel или SQL, вероятно, приведет к зависанию всей вашей машины из-за недостаточной вычислительной мощности.
Но вместо того, чтобы использовать эту расплывчатую ссылку, давайте взглянем на формальное определение того, что такое большие данные. В целом, большие данные определяют три составляющих: Объем, скорость и разнообразие.
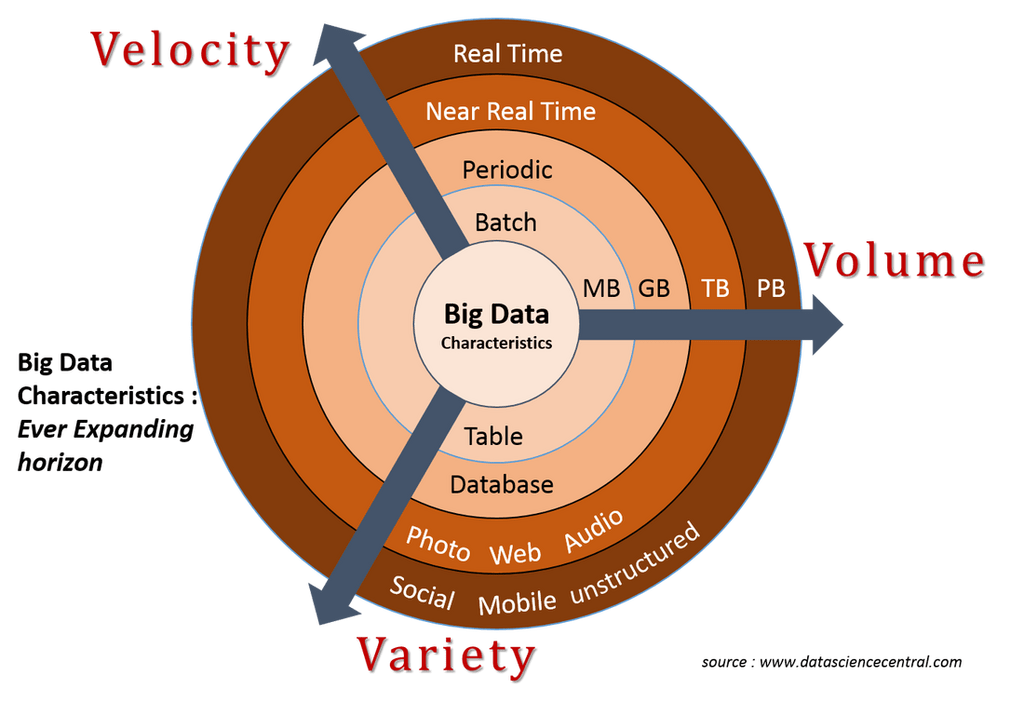
Объем - это объем собранных данных, который измеряется как минимум в гигабайтах и может достигать терабайт или даже петабайт.
Скорость - это скорость, с которой данные передаются и накапливаются, что в конечном итоге приведет к очень большому объему.
Разнообразие относится к множеству различных типов собираемых данных, таких как текст, аудио и видео, что приводит к очень сложному и неструктурированному озеру данных.
Выполнение всех трех V не обязательно для определения того, что такое большие данные. Если ваши данные удовлетворяют одному из критериев V, их можно рассматривать как большие данные. Недавно к этому миксу были добавлены еще 2 буквы V: достоверность и ценность. Правдивость указывает на точность данных, а Ценность указывает на их ценность. Однако эти V, похоже, не только описывают и дифференцируют большие данные, поэтому мы будем придерживаться исходных 3 V.
Что такое Hadoop?

Итак, я уже упоминал, что традиционные машины обычно не могут хранить и обрабатывать большие данные. Именно здесь на помощь приходят специализированные инструменты, такие как Hadoop и Cloud Computing. Apache Hadoop - это программный фреймворк с открытым исходным кодом, который управляет хранением и обработкой больших данных через кластер машин. Технические детали всей архитектуры Hadoop довольно сложны, но для целей этой публикации я кратко объясню один из ее основных компонентов: распределенную файловую систему Hadoop.
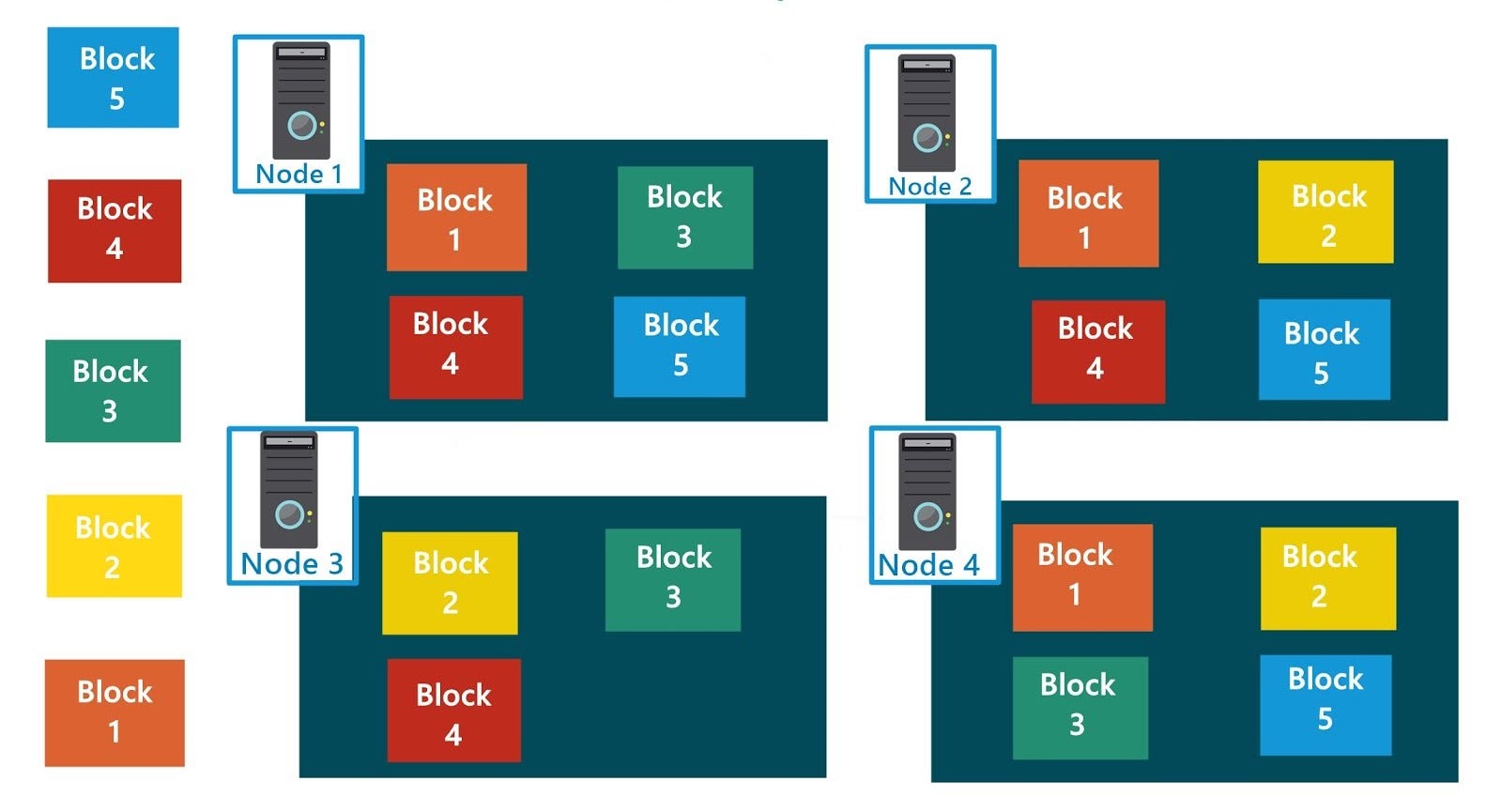
Распределенная файловая система Hadoop (HDFS) - это основная система хранения данных, используемая приложениями Hadoop. Распределенная файловая система работает, разделяя большие данные на множество блоков, дублируя по 3 копии каждого блока и распределяя копии по разным серверам. Идея такой конструкции заключается в достижении высокой доступности и отказоустойчивости, что позволяет обрабатывать данные более эффективно и устойчиво к сбоям. Этот тип обработки также известен как параллельная обработка.
Один из способов получить доступ к Hadoop - через Cloudera. Cloudera - компания-разработчик программного обеспечения, которая помогает распространять Hadoop с помощью своего программного обеспечения и сервисов, и он доступен как локально, так и на нескольких облачных платформах. Чтобы ознакомиться с Cloudera и Hadoop, можно загрузить Виртуальную машину QuickStart (VM) Cloudera, чтобы опробовать ее в среде песочницы.

В Cloudera есть интерфейс браузера под названием Hue UI. Hue - это веб-интерфейс с открытым исходным кодом для Hadoop, который позволяет получать доступ к HDFS через файловый браузер, а также позволяет обрабатывать и запрашивать большие данные, подключившись к Hive.

Файловый браузер работает так же, как и любой другой файловый менеджер, и он особенно полезен, если вы не знакомы с использованием командной строки Linux для выполнения команд в HDFS. После того, как вы переместили файл данных с платформы Cloudera в HDFS, вы увидите, что он отображается в браузере файлов, и вы можете использовать путь к файлу HDFS для загрузки данных.
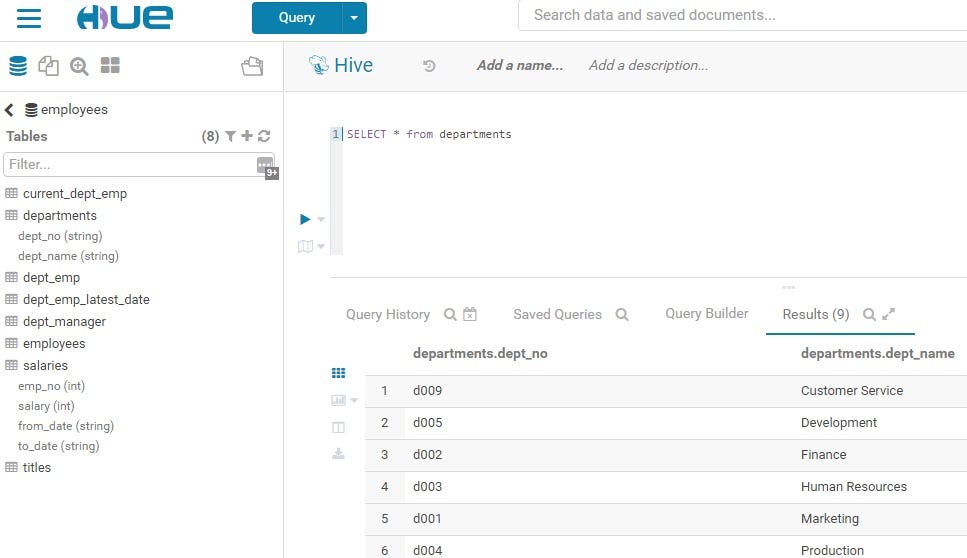
Apache Hive - это система хранилища данных, построенная на основе Hadoop для обработки и запроса больших данных. Хотя Hive использует диалект SQL под названием HiveQL, который очень похож на язык запросов в традиционных базах данных, все же есть некоторые различия из-за необходимости соблюдать ограничения Hadoop. Тем не менее, как вы можете видеть на изображении выше, Hive Editor в пользовательском интерфейсе Hue очень похож на традиционные редакторы SQL, и люди, которые уже знакомы с SQL, определенно окажутся дома.
Теперь, когда вы лучше понимаете, как можно хранить и обрабатывать большие данные, давайте перейдем к анализу больших данных.
Что такое Spark?

Apache Spark - это единый движок аналитики для больших данных и машинного обучения, который может взаимодействовать с HDFS. Во время обработки Spark сохраняет данные, используемые в качестве устойчивого распределенного набора данных (RDD), в памяти, которая представляет собой неизменяемую, секционированную коллекцию элементов данных, которая распределяется по кластеру машин и может использоваться параллельно, что делает ее « отказоустойчивой".
Первоначально Spark был написан на языке программирования Scala, но из-за популярности других языков программирования в науке о данных Spark теперь также поддерживает Python, R, SQL и Java. Это действительно здорово, потому что Python, R и SQL широко используются в отрасли науки о данных, поэтому переход на Spark на самом деле не будет таким уж чуждым. Фактически, версия Spark, использующая язык программирования Python, известна как PySpark, который представляет собой API Python, который позволяет взаимодействовать с RDD Spark.

Следующий логичный вопрос, который следует задать: как получить доступ к Spark и использовать его? Как видно из изображения выше, один из способов доступа к Spark - через терминал Cloudera. При вводе pyspark в терминале будет вызвана оболочка Python Spark, и PySpark можно будет использовать в командной строке. Но поскольку командная строка - не самый удобный способ анализа данных, другой вариант доступа к Spark - через веб-интерфейс пользователя под названием Databricks.
Databricks был основан создателями Spark и предоставляет оперативную облачную платформу для обработки больших данных в виде записных книжек, похожих на записные книжки Jupyter. Это снова помогает при переходе на Spark, поскольку многие люди в индустрии обработки данных привыкли использовать Jupyter. Имея язык программирования и пользовательский интерфейс, знакомый большинству людей, чего еще мы можем желать?
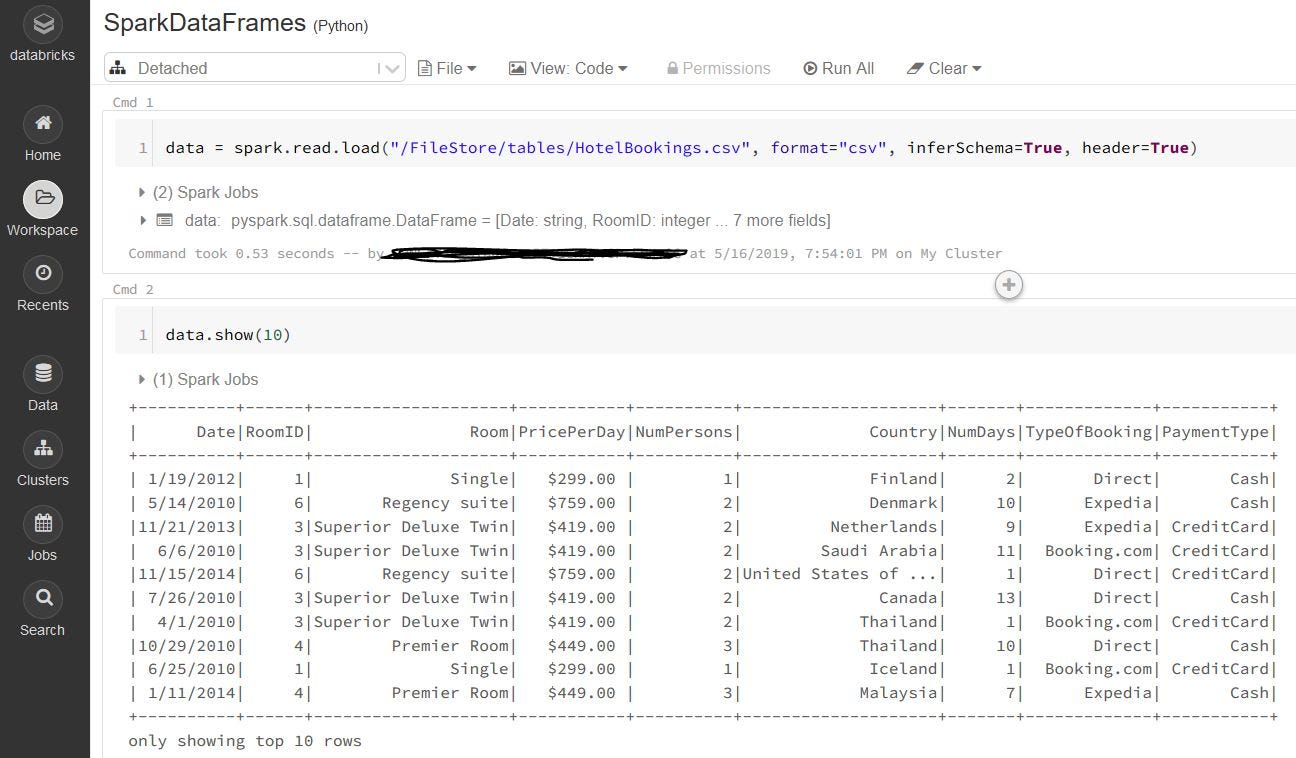
Как оказалось, простота использования не ограничивается этим. Пользователи R и Python Pandas будут знакомы с термином DataFrames. Spark также использует DataFrames. Spark DataFrame - это, по сути, набор данных, организованный в столбцы. Концептуально это то же самое, что и фреймы данных в R и Python, но с более обширной внутренней оптимизацией. Источник для Spark DataFrames может поступать из многих источников - от RDD Spark, о которых мы упоминали ранее, таблиц Hive от Hadoop или даже из внешних баз данных, таких как MySQL.
Но когда дело доходит до использования функций в Spark, существуют некоторые отличия по сравнению с Python. Чтобы упростить ситуацию, мы сравним функции для RDD Spark с эквивалентами для массивов Python, а функции для Spark DataFrames с эквивалентами для Pandas DataFrames. Чтобы загрузить файлы в Databricks, файлы должны быть сначала загружены в Файловую систему Databricks (DBFS). Следовательно, вы заметите, что путь к файлу для последующих сравнений со Spark начинается с dbfs://FileStore/table/.

Как вы можете видеть на изображении выше, большое количество функций для массивов Python также может быть реализовано с помощью операций Spark RDD. Операции RDD, такие как union(otherData) и distinct(), называются методами преобразования, поскольку они создают новые RDD, а такие операции, как collect() и count(), называются методами действий, поскольку они запускают вычисление в RDD и возвращают значение. Обратите внимание, что RDD нельзя просто создать, просто определив переменную; метод sc.parallelize([]) необходимо использовать даже при создании пустого RDD. Кроме того, индексирование в RDD не может быть достигнуто просто с помощью двоеточия :, поэтому метод take(n) требуется для печати первых n строк.

Интересно, что Spark DataFrames очень похожи на Pandas DataFrames, с некоторыми небольшими различиями в словах, используемых для вызова одних и тех же функций. Тем не менее, логика почти такая же, поэтому адаптация к Spark DataFrames не должна быть слишком сложной. Фактически, многие функции, такие как show(), select() и union(), названы в честь предложений, используемых в SQL, поэтому пользователям Python и SQL это будет очень удобно.
Еще одна отличная функция в Spark DataFrames - toPandas(). Эта функция позволяет преобразовать ваш Spark DataFrame в Pandas DataFrame в Databricks, если когда-либо возникнет необходимость использовать библиотеку построения графиков Python для визуализации данных. Однако это преобразование должно выполняться только после того, как вы отфильтровали свои большие данные в гораздо меньший фрейм данных с помощью Spark DataFrames, поскольку Pandas DataFrames не предназначен для обработки больших данных.
Бонус: машинное обучение

Честно говоря, у меня пока нет большого опыта использования машинного обучения на Python или Spark. Но из того, что я прочитал и понял, scikit-learn - самая популярная библиотека машинного обучения на традиционном Python, а MLlib - это библиотека машинного обучения, разработанная Spark для работы с большими данными. Если это правда, тогда концепция должна быть такой же, как и то, что мы уже прошли выше.
Если ваши данные слишком велики и вам нужно запускать на них алгоритмы машинного обучения, вероятно, было бы лучше использовать MLlib, поскольку это распределенная структура, предназначенная для параллельной обработки. Но если вы можете уменьшить свои данные до более управляемого размера для преобразования в Pandas DataFrame, scikit-learn станет жизнеспособным вариантом.
Чтобы узнать больше о различиях между scikit-learn и Spark MLlib, ознакомьтесь с этим вопросом и ответами на Quora:
А если вы хотите узнать больше о различных типах машинного обучения, прочтите мой предыдущий пост.
Обязательно ли больше лучше?
Мы довольно много рассмотрели, что такое большие данные, и как мы можем хранить, обрабатывать и анализировать их с помощью нескольких специализированных инструментов. Но если мы вернемся к сути вопроса, мы, вероятно, также должны спросить себя, почему мы вообще имеем дело с большими данными?
Нет сомнений в том, что в сегодняшнем мире с высокой степенью цифровизации у нас есть тонны данных, которые ждут, чтобы мы их использовали, а развитие технологий распределенных файловых систем и параллельной обработки дало нам возможность обрабатывать большие данные. Но означает ли способность обрабатывать большие данные, что мы всегда должны стремиться к сбору больших данных? Проблема с большими данными заключается в том, что при таком большом количестве информации часто трудно сосредоточиться на ответах на очень конкретные вопросы. Чтобы проанализировать такой большой объем информации, неизбежно потребуется использование автоматических процессов для выбора модели. Но недостатком использования автоматических процессов является то, что результирующая модель обычно становится не интерпретируемой.
В феврале этого года статистик из Университета Райса, доктор Женевера Аллен, выступил с предупреждением о том, что то, как сегодня используется машинное обучение, может способствовать кризису воспроизводимости в науке. В значительной степени это связано с чрезмерной зависимостью от результатов, полученных с помощью моделей машинного обучения. Когда наборы данных огромны, модели нередко выбирают закономерности, которые на самом деле ничего не значат. Следовательно, для человека, управляющего моделью, очень важно иметь контроль над тем, что в нее входит, и иметь хорошее представление о контексте решаемой проблемы.

Причина, по которой малые данные могут иметь большую ценность, чем большие данные, заключается в том, что они часто более доступны, понятны и действенны по сравнению с большими данными. Чтобы ответить на конкретные вопросы, необходимо использовать статистический вывод, а Small Data больше подходит для такого анализа. Проверяя гипотезы, основанные на прочной теоретической основе, статистический анализ может помочь интерпретировать результаты более тонко, а выводы будут намного более реалистичными и консервативными.
В любом случае, что, пожалуй, наиболее важно, это то, что мы понимаем, что разные инструменты предназначены для работы с большими и малыми данными по отдельности. До тех пор, пока мы не злоупотребляем методами, для которых они не предназначены, идеи, вероятно, можно будет найти как в больших, так и в малых данных.
Если вы хотите узнать больше о кризисе воспроизводимости, ознакомьтесь с моим сообщением о байесовском анализе и кризисе репликации:
Если вы хотите узнать больше о показателях точности машинного обучения, ознакомьтесь с моим сообщением о Матрице неточностей:
Первоначально опубликовано по адресу: https://learncuriously.wordpress.com/2019/07/28/big-data-for-beginners