Как написал в своем посте Питер Бейлис, запросы к неструктурированным данным с помощью SQL — болезненный процесс. Кроме того, разработчики часто предпочитают динамические языки программирования, поэтому взаимодействие со строгой системой типов SQL является барьером.
Мы в Rockset создали первую бессхемную платформу данных SQL. В этом и нескольких последующих постах мы хотели бы познакомить вас с нашим подходом. Мы познакомим вас с нашими мотивами, несколькими примерами и некоторыми интересными техническими проблемами, которые мы обнаружили при создании нашей системы.
Многие из нас в Rockset являются поклонниками языка программирования Python. Нам нравится его прагматизм, его серьезное отношение Должен быть один — и желательно только один — очевидный способ сделать это (Дзен Python) и, что немаловажно, его простая, но мощная система типов.
Python имеет строгую и динамическую типизацию:
- Надежно, поскольку значения имеют один определенный тип (или
None), а значения несовместимых типов не преобразуются автоматически друг в друга. Строки — это строки, числа — это числа, логические значения — это логические значения, и они не смешиваются, кроме как четкими и четко определенными способами. В отличие от JavaScript, который имеет слабую типизацию. JavaScript позволяет (например) складывать и сравнивать числа и строки с запутанными результатами. - Динамический, поскольку переменные получают информацию о типе во время выполнения, и одна и та же переменная может в разные моменты времени содержать значения разных типов.
a = 5заставитaсодержать целое число; последующее присвоениеa = 'hello'заставитaсодержать строку. В отличие от Java и C, которые статически типизированы. Переменные должны быть объявлены, и они могут содержать значения только того типа, который указан при объявлении.
Конечно, ни один язык не попадает точно ни в одну из этих категорий, но тем не менее они образуют полезную классификацию для понимания систем типов на высоком уровне.
Большинство баз данных SQL, напротив, имеют строгую и статическую типизацию. Значения в одном и том же столбце всегда имеют один и тот же тип, а тип определяется во время создания таблицы, и его трудно изменить позже.
Что не так со статической типизацией SQL?
Это несоответствие импеданса между языками с динамической типизацией и статической типизацией SQL оттолкнуло разработку от баз данных SQL к системам NoSQL. На системах NoSQL проще создавать приложения, особенно на ранних этапах, до того, как модель данных стабилизируется. Конечно, отказ от традиционных баз данных SQL означает потерю эффективных индексов и возможности выполнять сложные запросы и соединения.
Кроме того, современные наборы данных часто имеют полуструктурированную форму (JSON, XML, YAML) и не соответствуют четко определенной статической схеме. Часто приходится создавать конвейер предварительной обработки, чтобы определить правильную схему для использования, очистить входные данные и преобразовать их в соответствии со схемой, и такие конвейеры ненадежны и подвержены ошибкам.
Более того, SQL традиционно не очень хорошо работает с глубоко вложенными данными (массивы JSON массивов объектов, содержащих массивы…). Затем конвейер данных должен сгладить данные или, по крайней мере, функции, к которым необходимо получить быстрый доступ. Это еще больше усложняет процесс.
Что такое Альтернатива?
Что, если мы попытаемся построить базу данных SQL, которая динамически типизируется с нуля, не жертвуя при этом мощью SQL?
Модель данных Rockset аналогична JSON: значения либо
- скаляры (числа, логические значения, строки и т. д.)
- массивы, содержащие любое количество произвольных значений
- карты (которые, заимствуя из JSON, мы называем «объектами»), отображающие строковые ключи в произвольные значения
Мы расширяем модель данных JSON для поддержки других скалярных типов (например, типов, связанных с датой и временем), но подробнее об этом в следующем посте.
Важно отметить, что документы не обязательно должны иметь одинаковые поля. Совершенно нормально, если поле встречается, скажем, в 10% документов; запросы будут вести себя так, как если бы это поле было NULL в остальных 90%.
Разные документы могут иметь значения разных типов в одном и том же поле. Это важно; многие реальные наборы данных не являются чистыми, и вы найдете (например) почтовые индексы, которые хранятся как целые числа в одной части набора данных и хранятся как строки в других частях. Rockset позволит вам принимать и запрашивать такие документы. В зависимости от запроса значения неожиданных типов могут игнорироваться, обрабатываться как NULL или сообщать об ошибках.
Будет небольшое снижение производительности, вызванное динамической природой системы типов. Легче написать эффективный код, если вы знаете, что обрабатываете, например, большой блок целых чисел, а не проверяете каждое значение. Но на практике данные действительно смешанного типа встречаются редко — возможно, в столбце целых чисел будет несколько строк-выбросов, поэтому на практике проверки типов могут быть удалены из критических путей кода. На высоком уровне это похоже на то, что сегодня делают компиляторы Just-In-Time для динамических языков: да, переменные могут изменять типы во время выполнения, но обычно это не так, поэтому стоит оптимизировать для общего случая.
Традиционные реляционные базы данных возникли во времена, когда хранение было дорогим, поэтому они оптимизировали представление каждого отдельного байта на диске. К счастью, это больше не так, что открывает двери для внутренних форматов представления, которые отдают предпочтение функциям и гибкости, а не использованию пространства, что мы считаем достойным компромиссом.
Простой пример
Я хотел бы показать вам простой пример того, как вы можете использовать динамические типы в Rockset SQL. Мы начнем с тривиально небольшого набора данных, состоящего из базовой биографической информации для шести воображаемых людей, представленных в виде файла с одним документом JSON в каждой строке (это формат, который Rockset изначально поддерживает):
{"name": "Tudor", "age": 40, "zip": 94542}
{"name": "Lisa", "age": 21, "zip": "91126"}
{"name": "Hana"}
{"name": "Igor", "zip": 94110.0}
{"name": "Venkat", "age": 35, "zip": "94020"}
{"name": "Brenda", "age": 44, "zip": "90210"}Как это часто бывает с реальными данными, этот набор данных не является чистым. В некоторых документах отсутствуют определенные поля, а поле почтового индекса (которое должно быть строкой) имеет значение int для одних документов и float для других.
Rockset без проблем принимает этот набор данных:
$ rock add tudor_example1 /tmp/example_docs
COLLECTION ID STATUS ERROR
tudor_example1 3e117812-4b50-4e55-b7a6-de03274fc7df-1 ADDED None tudor_example1 3e117812-4b50-4e55-b7a6-de03274fc7df-2 ADDED None tudor_example1 3e117812-4b50-4e55-b7a6-de03274fc7df-3 ADDED None tudor_example1 3e117812-4b50-4e55-b7a6-de03274fc7df-4 ADDED None tudor_example1 3e117812-4b50-4e55-b7a6-de03274fc7df-5 ADDED None tudor_example1 3e117812-4b50-4e55-b7a6-de03274fc7df-6 ADDED Noneи мы видим, что он сохранил исходные типы полей:
$ rock sql
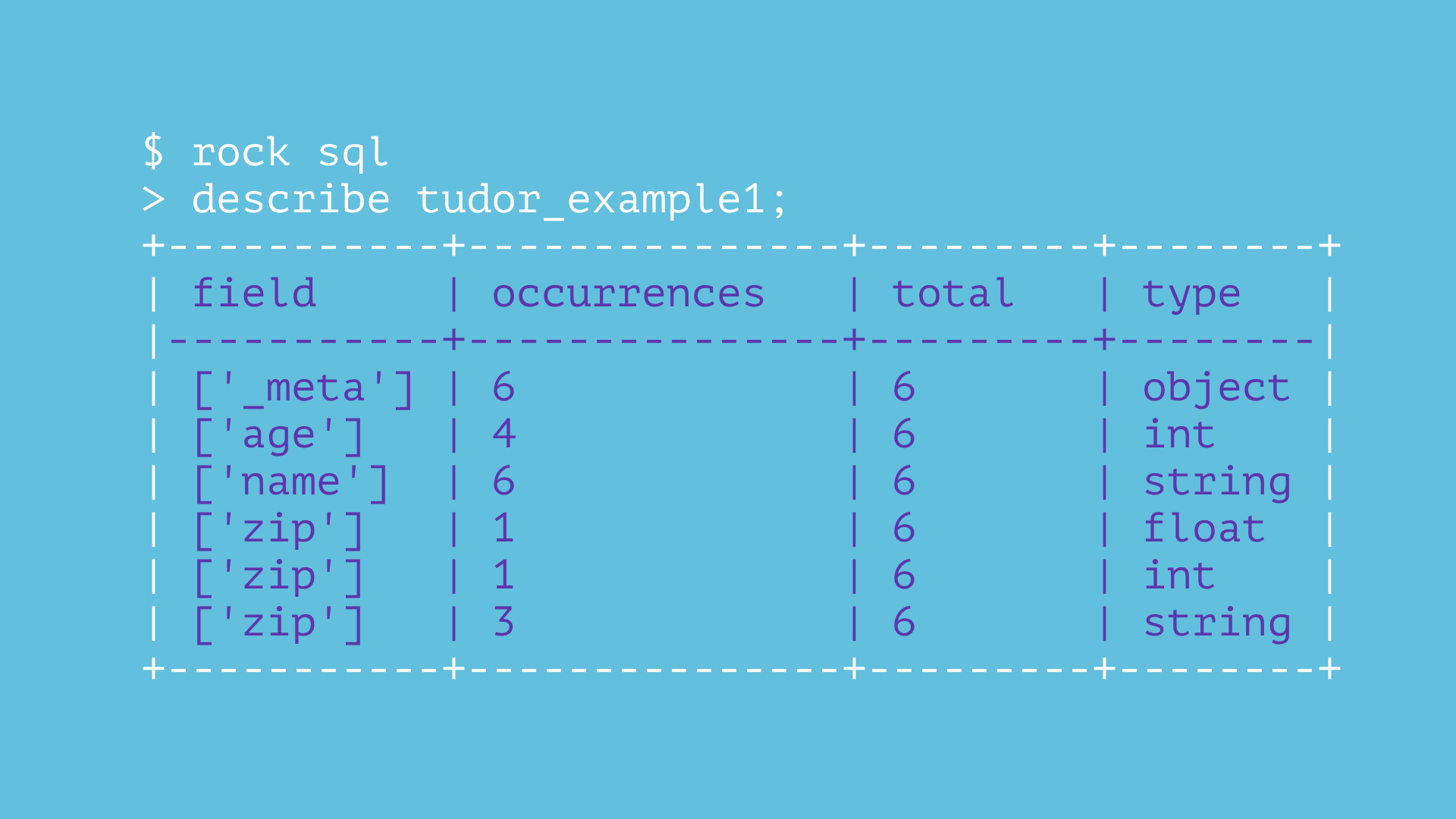
> describe tudor_example1;
+-----------+---------------+---------+--------+
| field | occurrences | total | type |
|-----------+---------------+---------+--------|
| ['_meta'] | 6 | 6 | object |
| ['age'] | 4 | 6 | int |
| ['name'] | 6 | 6 | string |
| ['zip'] | 1 | 6 | float |
| ['zip'] | 1 | 6 | int |
| ['zip'] | 3 | 6 | string |
+-----------+---------------+---------+--------+Обратите внимание, что поле zip существует в 5 из 6 документов и имеет значение float в одном документе, int в другом и string в трех других.
Rockset обрабатывает документы, в которых поле zip не существует, как если бы это поле было NULL:
> select name, zip from tudor_example1; +--------+---------+ | name | zip | |--------+---------| | Brenda | 90210 | | Lisa | 91126 | | Venkat | 94020 | | Tudor | 94542 | | Hana | <null> | | Igor | 94110.0 | +--------+---------+> select name from tudor_example1 where zip is null; +--------+ | name | |--------| | Hana | +--------+
И Rockset поддерживает различные cast и функции самоанализа типов, которые позволяют выполнять запросы по типам:
> select name, zip, typeof(zip) as type from tudor_example1 where typeof(zip) <> 'string'; +--------+--------+---------+ | name | type | zip | |--------+--------+---------| | Igor | float | 94110.0 | | Tudor | int | 94542 | +--------+--------+---------+> select name, zip::string as zip_str from tudor_example1; +--------+-----------+ | name | zip_str | |--------+-----------| | Hana | <null> | | Venkat | 94020 | | Tudor | 94542 | | Igor | 94110 | | Lisa | 91126 | | Brenda | 90210 | +--------+-----------+> select name, zip::string zip from tudor_example1 where zip::string = '94542'; +--------+-------+ | name | zip | |--------+-------| | Tudor | 94542 | +--------+-------+
Запрос вложенных данных
Rockset также позволяет эффективно запрашивать глубоко вложенные данные, рассматривая вложенные массивы как таблицы верхнего уровня и позволяя использовать полный синтаксис SQL для запроса к ним.
Давайте дополним тот же набор данных и добавим информацию о том, где работают эти люди:
{"name": "Tudor", "age": 40, "zip": 94542, "jobs": [{"company":"FB", "start":2009}, {"company":"Rockset", "start":2016}] }
{"name": "Lisa", "age": 21, "zip": "91126"}
{"name": "Hana"}
{"name": "Igor", "zip": 94110.0, "jobs": [{"company":"FB", "start":2013}]}
{"name": "Venkat", "age": 35, "zip": "94020", "jobs": [{"company": "ORCL", "start": 2000}, {"company":"Rockset", "start":2016}]} {"name": "Brenda", "age": 44, "zip": "90210"}Добавьте документы в новую коллекцию:
$ rock add tudor_example2 /tmp/example_docs
COLLECTION ID STATUS ERROR
tudor_example2 a176b351-9797-4ea1-9869-1ec6205b7788-1 ADDED None tudor_example2 a176b351-9797-4ea1-9869-1ec6205b7788-2 ADDED None tudor_example2 a176b351-9797-4ea1-9869-1ec6205b7788-3 ADDED None tudor_example2 a176b351-9797-4ea1-9869-1ec6205b7788-4 ADDED None tudor_example2 a176b351-9797-4ea1-9869-1ec6205b7788-5 ADDED NoneМы поддерживаем полустандартную табличную функцию UNNEST SQL, которую можно использовать в соединении или подзапросе для «развертывания» поля массива:
> select p.name, j.company, j.start from
tudor_example2 p cross join unnest(p.jobs) j
order by j.start, p.name;
+-----------+--------+---------+
| company | name | start |
|-----------+--------+---------|
| ORCL | Venkat | 2000 |
| FB | Tudor | 2009 |
| FB | Igor | 2013 |
| Rockset | Tudor | 2016 |
| Rockset | Venkat | 2016 |
+-----------+--------+---------+Проверка на существование может быть выполнена с помощью обычного синтаксиса semijoin (подзапрос IN/EXISTS). Наш оптимизатор распознает тот факт, что вы запрашиваете вложенное поле в той же коллекции, и может эффективно выполнить запрос. Получим список людей, которые работали в Facebook:
> select name from tudor_example2
where 'FB' in (select company from unnest(jobs) j);
+--------+
| name |
|--------|
| Tudor |
| Igor |
+--------+Если вас интересуют только вложенные массивы (но вам не нужно коррелировать с родительской коллекцией), у нас есть для этого специальный синтаксис; любой вложенный массив объектов может быть представлен как таблица верхнего уровня:
> select * from tudor_example2.jobs j;
+-----------+---------+
| company | start |
|-----------+---------|
| ORCL | 2000 |
| Rockset | 2016 |
| FB | 2009 |
| Rockset | 2016 |
| FB | 2013 |
+-----------+---------+Я надеюсь, что вы сможете увидеть преимущества способности Rockset принимать необработанные данные без какой-либо подготовки или моделирования схемы и при этом эффективно использовать строго типизированный SQL.
В будущих постах мы переключим передачу и углубимся в детали некоторых интересных проблем, с которыми мы столкнулись при создании Rockset. Быть в курсе!
Первоначально опубликовано на https://rockset.com 1 ноября 2018 г.