Содержание этой статьи вдохновлено курсом Udemy Machine Learning A-Z Кирилла Еременко и Хаделин Де Понтевес.
Если вы специалист по данным, самая важная часть вашего пути - это предварительная обработка данных. Эта часть определяет остальную часть вашей работы. На этом этапе сбора данных данные, которые мы получаем, могут быть не всегда правильными, у нас могут быть некоторые недостающие значения, нежелательные функции или строковые данные. Но для любой хорошей модели машинного обучения нам нужно будет выбрать только необходимые функции для хорошей точности нашей модели. Для хорошей точности модели нам понадобятся чистые данные. Этот этап вашего путешествия называется предварительной обработкой данных.

Мы можем разделить наш процесс на 4 этапа:
- Разделение набора данных Train и Test
- Обработка отсутствующих значений
- Кодирование категориальных признаков
- Масштабирование функций
Теперь давайте рассмотрим каждую из вышеупомянутых тем более глубоко. Это руководство также включает код.
Разделение наборов данных для обучения и тестирования
Мы выполняем эту операцию для проверки модели. Многие люди совершают огромную ошибку, прогнозируя точность обученного набора данных. Они делают прогнозы на основе своих обученных данных и сравнивают их с фактическими значениями обученных данных. Такой подход иногда терпит неудачу. У нас будут как хорошие, так и плохие прогнозы. Таким образом, наша модель машинного обучения не будет такой точной для новых данных.
Предположим, у вас есть набор данных для прогнозирования цен на жилье, не связанный с цветом двери. В выборке данных все дома с дверью зеленого цвета стоят дорого. Работа модели заключается в прогнозировании на основе этого образца, но здесь она находит образец, который двери с зеленым цветом дают высокую стоимость. Модель может быть точной для данных обучения. Но с тестовыми данными это не работает. Итак, мы косвенно измеряем функцию, которая не требуется для построения модели. Таким образом, точность тестовых данных становится очень низкой.
Таким образом, самый простой способ решить эту проблему - исключить некоторые данные во время обучения. Это называется данные проверки.
# Importing the libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# Importing the dataset
dataset = pd.read_csv('./Data.csv')
X = dataset.iloc[:, :-1].values
y = dataset.iloc[:, 3].values
# Splitting the dataset into the Training set and Test set
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
Приведенный выше код импортирует необходимые пакеты для обработки данных. Затем набор данных импортируется как файл .csv (значения, разделенные запятыми). Позже мы разделили целевую переменную «y» и остальные функции на «X».
Позже мы импортируем наиболее часто используемый пакет Python для обработки данных, известный как Sklearn. В строке ниже импортируются необходимые пакеты для разделения данных в виде набора для обучения и тестирования.
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
Поскольку весь набор данных разделен на наборы данных Train и Test, мы должны использовать 4 отдельные переменные для обработки данных, известных как X_train, X_test, y_train и y_test. Функция train_test_split () разделяется в соответствии с переданными параметрами. Здесь test_size = 0,2 означает, что 20% всего набора данных разделено как тестовые данные со случайным разделением. Если random_state не упоминается, разбиение будет выполняться последовательно. Иногда это может создавать проблемы в определенных наборах данных, где данные неадекватны.
Разделение наборов данных Train и Test всегда не требуется, если оба даны отдельно.
Обработка отсутствующих данных
Здесь можно использовать разные методы. Но давайте перейдем к банальному.
# Taking care of missing data from sklearn.preprocessing import Imputer imputer = Imputer(missing_values = 'NaN', strategy = 'mean', axis = 0) #Mean strategy by replacing NaN along the columns(axis=0) imputer = imputer.fit(X[:, 1:3]) # Fit the replace data X[:, 1:3] = imputer.transform(X[:, 1:3]) # replace the original data
Импьютер пакета sklearn.preprocessing используется для обработки недостающих данных. Работа Imputer заключается в нахождении значений = «NaN» по оси = 0 (столбцы) и заполнении недостающих данных средним значением оставшихся имеющихся данных.
Кодирование категориальных признаков
В любой модели машинного обучения числовые данные имеют больший смысл для компьютера, чем строковые данные. Итак, основная цель этого процесса - преобразовать похожие повторяющиеся категориальные значения в числовые данные.
Обычно это делается путем кодирования данных с помощью LabelEncoder.
# Encoding categorical data # Encoding the Independent Variable from sklearn.preprocessing import LabelEncoder labelencoder_X = LabelEncoder() X[:, 0] = labelencoder_X.fit_transform(X[:, 0])
Мы импортируем LabelEncoder из sklearn.preprocessing и создаем функцию LabelEncoder (). Теперь поместите и преобразуйте категориальные данные обучения в эту функцию.
Теперь все строковые данные преобразованы в числовые данные, которые легко подогнать под модель.


Здесь большая проблема возникает, когда категорий слишком много. Мы можем решить эту проблему с помощью One Hot Encoding, где каждая метка кодируется как двоичное представление десятичных чисел.
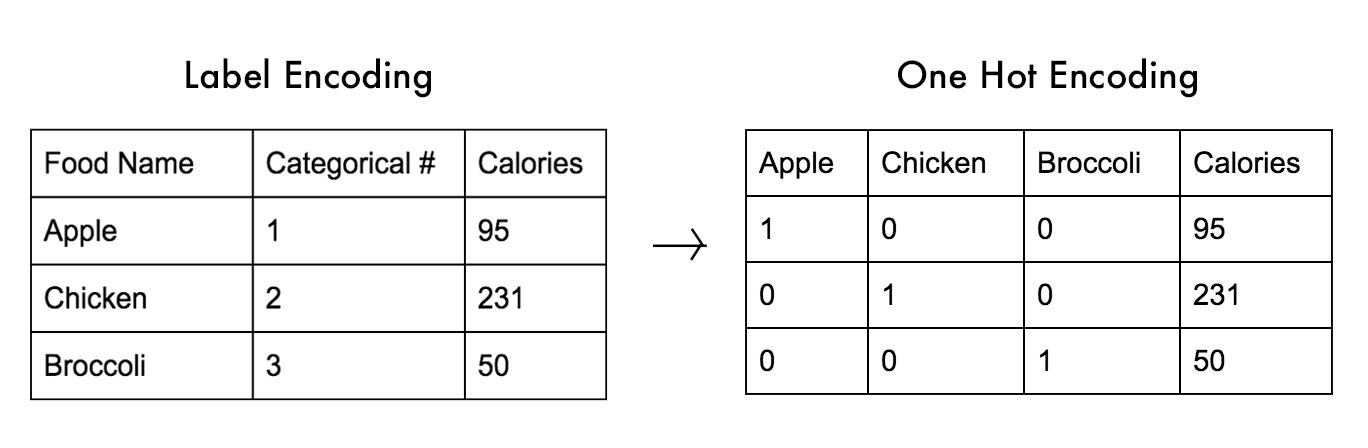
Если вы посмотрите на приведенный выше пример, закодированная метка преобразуется в One Hot Encoding, где, если Apple может быть представлен как 100, Chicken как 010
# Use Onr hot encoding to prevent the problem of ordering in the #label encoder ''' France Germany England 1 0 0 0 1 0 0 0 1 ''' from sklearn.preprocessing import OneHotEncoder onehotencoder = OneHotEncoder(categorical_features = [0]) X = onehotencoder.fit_transform(X).toarray()
Приведенный выше код может One Hot Encode кодировать данные обучения, а позже вы можете легко поиграть с этими данными, которые относительно легко представить.
Масштабирование функций
Это один из самых полезных методов при работе с огромным объемом данных. В некоторых моделях машинного обучения целевые функции не работают должным образом без нормализации. Пример. Классификация выполняется путем вычисления евклидова расстояния между двумя точками. Если данные огромны, то расчет расстояния меняется, тогда расстояние будет регулироваться определенной особенностью.
from sklearn.preprocessing import StandardScaler sc_X = StandardScaler() X_train = sc_X.fit_transform(X_train) X_test = sc_X.transform(X_test) sc_y = StandardScaler() y_train = sc_y.fit_transform(y_train)
Этого можно добиться с помощью стандартного масштабирования данных. Подгоните и преобразуйте свои данные обучения и данные тестирования в функцию StandardScaler (). Это легко сделать с помощью пакетов sklearn.
На этом мы подошли к концу этого руководства по предварительной обработке данных. Описанные выше методы являются примитивными методами, которые обычно используются специалистами по анализу данных. Но для повышения точности можно также использовать более совершенные методы, настроив гиперпараметры этих функций.
Надеюсь, вы получили некоторое представление о предварительной обработке данных. Надеюсь, вам понравилось чтение. Спасибо.
Любые запросы можно размещать в комментариях.
Автор: Сришилеш П.С.
Электронная почта: [email protected]
LinkedIn: https://www.linkedin.com/in/srishilesh/
GitHub: https: / /github.com/srishilesh
Kaggle: https://www.kaggle.com/srishilesh