
Сидя на уроке статистики, мой профессор часто повторял, насколько важно решить гипотезы, которые нужно проверить, прежде чем смотреть на данные. Он высмеивал идею интеллектуального анализа данных и заявлял, что любой, кто формулирует свои гипотезы после просмотра данных, обречен на провал.
Он никогда не говорил почему.
Я видел похожие мысли, отраженные в руководящих принципах по разработке медицинских испытаний: перед началом рандомизированного контрольного испытания для проверки эффективности лекарственного средства очень важно заранее сформулировать гипотезы, которые вы ожидаете.
Я довольно долго задавался вопросом о причине этого, и недавно, выяснив это, я подумал, что поделюсь почему на примере.
Представьте, что у нас есть такая переменная, как высота. Распространяется нормально. Мы отбираем 3 человек из популяции, измеряем их рост и берем среднее значение. Назовем это X1. Мы выбираем 3 разных людей из ОДНОЙ популяции, усредняем их рост и называем это X2.
Теперь представьте, что мы провели двусторонний t-тест, оценивая, если X1 = X2 с альфа = 0,05. Нулевая гипотеза:
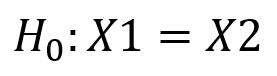
и альтернативная гипотеза

Поскольку 2 средних получены из одной и той же совокупности, мы ожидаем, что p> 0,05 и что мы не сможем отклонить нуль. Однако всегда существует редкая вероятность того, что одна группа будет отобрана исключительно из одного хвоста распределения, в то время как другая - из другого хвоста, и разница между X1 и X2 неожиданно велика. В таких случаях мы ошибочно отвергнем нулевую гипотезу, и, исходя из нашей альфы, вероятность этого составляет 5%.
Мы можем проверить это с помощью моделирования, когда мы многократно отбираем 2 группы по 3 человека из одного и того же нормального распределения и применяем t-тест к их средним значениям. Мы делаем это 100000 раз и строим гистограмму p-значений ниже. Как и ожидалось, мы получаем равномерное распределение, и около 5% значений p находятся в диапазоне от 0 до 5%. Это ложные срабатывания и важный момент, на котором стоит остановиться.

Несмотря на то, что эти группы происходили из одного и того же распределения, если бы мы не знали этого и просто смотрели на средства, есть вероятность 5%, мы бы неправильно заключили, что они происходят из разных распределений.
Эта частота ошибок присуща статистике, и мы допускаем, что наш вывод об отклонении нулевой гипотезы с вероятностью 5% неверен. Пока мы уверены, что это 5% и остается 5%, мы в порядке.
Но теперь давайте посмотрим, что происходит, когда мы меняем гипотезы после просмотра данных.
Мы моделируем это, снова рисуя 2 группы по 3 человека из данных. Мы сортируем каждую группу по высоте, и если средний член 1-й группы выше самого высокого члена 2-й группы, мы меняем наши гипотезы на:

Обратите внимание, что это односторонняя гипотеза, и с ее помощью может быть проще получить значимые результаты. Если средний член одной группы не выше всех в другой группе, мы, как обычно, используем вышеупомянутую двустороннюю гипотезу. Этот процесс воспроизводит поведение исследователя, который намеревается использовать двустороннюю гипотезу, но после анализа данных понимает, что у него больше шансов получить значимые результаты, используя одностороннюю гипотезу.
Выполнив еще одну симуляцию из 100000 выборок, мы получим гистограмму ниже. Обратите внимание на то, что произошло с количеством значений p, попадающих в диапазон 0–5%. Он резко увеличился.

Обращение к данным и изменение наших гипотез повысило вероятность отклонения нулевой гипотезы, хотя мы не должны этого делать. И хуже всего то, что мы даже не осознаем, что это происходит. Мы можем получить гораздо более «значимые» результаты, но все они могут быть ложноположительными.
В медицине и клинических исследованиях мы хотим любой ценой избежать неверных заявлений об эффективности препарата. Представьте себе вред и расходы, связанные с употреблением миллионов людей лекарств, которые мы ошибочно полагаем работающими, потому что исследователь изменил свои гипотезы после просмотра данных и ошибочно отверг нулевое значение.
Это была бы катастрофа.
Вот почему вам, вероятно, не следует менять свои гипотезы после просмотра данных.
Сообщите мне свои мысли и если у вас возникнут какие-либо вопросы, в комментариях ниже.